![]()
1
Access by Geographic Content to Textual Corpora: What Orientations?
1.1. Introduction
The volume of digital corpora is always on the rise and the retrieval of relevant documents is an increasingly delicate task. The ambiguity of natural language terms contributes to this difficulty in the automatic interpretation of the expression of the need for information as well as in the automatic evaluation of the correspondence between documents and needs. The multiple meanings of the terms and their numerous uses in varied contexts make delicate, indeed, the task of information retrieval. Our working hypothesis therefore consists of distinguishing the spatial, temporal and thematic dimensions in order to implement dedicated approaches in the processes of indexing and information retrieval (IR). The objective is to contribute to a better content analysis of textual corpora as well as to a better grasp of the search criteria expressed in a query. Let us recall that we are studying textual corpora with “territorial” denotations, digitized, to which processes of character recognition have been applied but whose logical structure has not been conserved.
This chapter is organized as follows. Section 1.2 presents the general context related to geographic information retrieval (GIR). Section 1.3 introduces privileged fields of research as well as the position of our study. Section 1.4 gives a rough sketch of our research approach in the construction of spatial, temporal and multicriteria search engines.
1.2. Access by geographic content to textual corpora
The study concerning the processing of information in text is mainly detailed in theses [BAZ 05, LES 07, PAL 10a, KER 11]. Following a number of reminders related to document retrieval and textual corpora, we will describe the characteristics of corpora with “territorial” denotations and their uses. This category of corpora will constitute the field of experimentation for our propositions.
1.2.1. Document retrieval and textual corpora
Document retrieval or information retrieval [BAE 99, BOU 08] is traditionally defined as a set of techniques allowing us to select, from a collection of documents, information that is likely to meet the needs of the user.
A collection of documents (document repository or corpus) is the information accessible via the document retrieval system (or information retrieval system, IRS). It consists of documents, unit elements. Textual documents are represented by a set of descriptors (terms, for example) stored in files of descriptive instructions (metadata) or indexes whose structure can be more complex [BES 04]. However, the notion of document in itself is vague. Generally defined by its container (e.g. a book, the physical object that contains the text), it often varies and the expected result of a query may not be an entire book but one or more particularly relevant fragments. This is indeed the reason why we use the expression “document unit” or “document fragment” to define the unit of text returned to the user [BAZ 05].
Finally, a query corresponds to the expression of the information needs of the user. It constitutes the input parameter to the retrieval system and is expressed in a query language that is often simple: a choice of keywords and logical operators, for instance. Nevertheless, other languages are presented in literature: natural language, graphical language, etc. [GOK 09].
1.2.2. Textual corpora with “territorial” denotations
A textual corpus with “territorial” denotations is composed of travelogues, stories, newspapers, novels, poems, etc. These documents describe/discuss a territory. As detailed in [KER 11], the territorial dimension is symbolized in textual documents by a significant frequency of toponyms, outlined facts or described observations. Toponyms denote, for example, streams, cities and buildings. The facts describe, for example, political or sport-related events as well as various other events. The observations refer to architecture, botany, geology, agriculture, etc. These categories of information are, in a general way, linked to a location or a period of time.
– Territory: The Longman Dictionary defines the term territory as “an area for which one person or branch of an organization is responsible”. Kergosien [KER 11] presents a consistent overview of the notion of territory. Among the different definitions proposed, we will retain the following two [KER 11, p. 70]: “A globally accepted definition in geography describes territory as a space on which an authority is exercised and is limited by political and administrative borders. This definition is subject to debate, however the notion of territory generally integrates a geographic space composed of places (spatial component) as well as relations with different subjects (thematic component) and/or references to a period (temporal component)”. It also describes a second point of view, that of geomatics. “Geomatics is the scientific field hovering between geography and computer science which mainly deals with problems of storage, processing and diffusion of geographic information. The characterization of geographic information in a particular territory is defined in the form of geographic entities (GEs) composed of spatial (SEs), temporal (TEs) and thematic entities. It should be noted that each one of these entities is not always specified or can be implicit”. Kergosien [KER 11] proposes an approach of ontology construction as a tool for the structured representation of a territory but also as a support to IR and to the browsing of document repositories.
– Examples of corpora: Territory is at the heart of numerous types of corpora. We can quote, for example, the French-speaking corpus of archives, mainly composed of texts, maps and lithographies related to the city of Saint-Étienne and to its river Furan1; the multi-lingual corpus (German and French) of the Swiss Alpine Club2, composed of reports, accounts, essays and thoughts under the theme of mountaineering; tourist guides such as the different ranges of Lonely Planet3 books or of the Michelin guide4; and the equally numerous hiking guides5 and other travel blogs6.
These corpora have the principal characteristic of containing a very large number of place names (spatial named entities will be defined further on); the places referred to in such a way generally have a fine level of detail in a relatively confined space (a river, a city and mountain range, for example). The Geotopia7 and Text+Berg digital8 projects are good examples of this. The objective of the first is to experiment with georeferencing techniques in order to help organize, transmit, share and interpret archival data [JOL 11]. The second aims to digitize and promote a corpus of alpine literature [VOL 10].
– The corpus of MIDR: MIDR9, from a perspective of cultural heritage promotion, has digitized and implemented the optical character recognition of its heritage document repository with the aim of indexing it into a document retrieval system. This way, the digitized documents can benefit from a renewed visibility and be exploited by a larger public. It should be noted that this digitalization, keeping in mind the cost of the operation, has been carried out by a provider without the correction of errors and the recovery of the documents’ structure, with the exception of their division into paragraphs.
Let us recall that this corpus is composed of documents of different types (literary studies, travelogues, newspapers, old geographic maps, lithographies, postcards, etc.), which have the common denominator of dealing with the Pyrénées territory in the 18th and 19th Centuries. A preliminary study of the corpus has revealed a predominant geographic connotation in the documents, as much in the literary studies dealing with travelogues as in the local periodicals whose articles relate to information about the territory. An experimentation has allowed us, for example, to extract almost 10,000 spatial named entities from 10 books within the corpus (i.e. 600,000 terms).
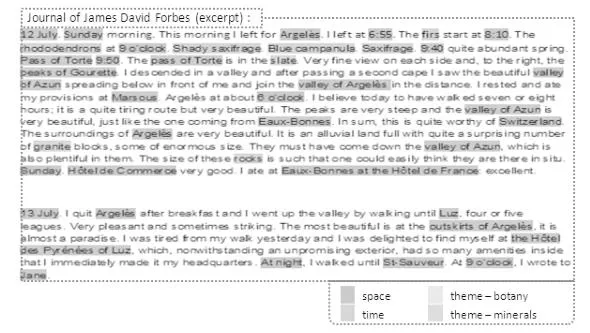
Indeed, a large amount of information makes reference to places, spatial indications as well as descriptions of landscape, temporal indicators and dates, implying a significant importance of these documents for the geographic aspect. Let us consider, as an example, travelogues (see the excerpt in Figure 1.1). The authors of these pieces of study use, most of the time, an identical structure: the text is divided into sections describing a portion of their travel. Each portion can consist of the description of an itinerary, a stage, a point of view, an observation, an event, etc.
Figure 1.1. Document excerpt – The Travel to the Pyrénées, David James Forbes, CAIRN Editions (1835)
Figure 1.1 represents two paragraphs from the travel journal of James David Forbes. In it we can find toponyms such as, for example, the “pass of Torre” whose toponymical reference name is “Torre”. We can also observe temporal references such as “12 July” and thematic such as “granite” (to be considered, for example, from a mineral point of view) or “firs” (of particular interest from a botanical point of view). Let us also note the varying levels of the complexity of information: we refer to “Argelès” as a simple spatial information whereas “outskirts of Argelès” is a complex spatial piece of information that evokes a relation of adjacency whose interpretation necessitates an additional analysis of the text.
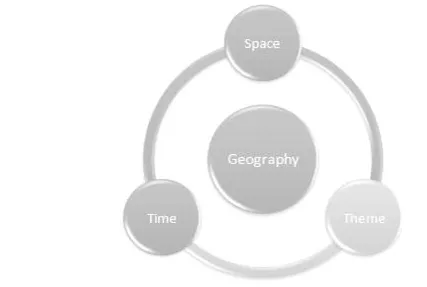
– Geographic information: The central element of the corpus being the geographic information, let us review a definition coming from geomatics: illustrated in Figure 1.2, it considers geographic information to be as a molecule not only composed of a spatial component, but also of a temporal component and a thematic component, or phenomenon [USE 96, GAI 01]. For example, the text “musical instruments in the vicinity of Laruns at the beginning of the 19th Century” fully describes this geographic molecule, with “musical instruments” corresponding to the thematic component. Let us note that some components might nonetheless be absent.
In the geography markup language (GML) specification10 and the research on databases [LE 04], we can see the appearance of the notion of temporality. Thus, it is possible to associate a piece of geographic information with one or more geo-referenced representations, valid at a certain moment in history [GAL 01]. For instance, a city or a forest has a variable spatial definition over time which can be a creation, a disappearance, an expansion or a reduction. Finally, a phenomenon is often associated with it: subject of research, for example, a regional pollution at a given period of time [PAL 10a].
Figure 1.2. Spatial, temporal and thematic dimensions of geographic information
1.2.3. Access to textual content
A study conducted on IR tasks led by students has revealed that the three main categories “of search criteria” are of bibliographical (people), chronological (periods) and spatial (toponyms) types [MAN 09]. Many other studies show a considerable proportion of references to places in the search criteria of users: for the Excite [SAN 04], AOL [GAN 08] and Yahoo [JON 08] engines, this proportion varies between 12.7 and 18.6%. Moreover, 79.5% of these queries contain toponyms [SAN 04].
In the context of digital libraries (DLs), the interfaces of IR and navigation in the resulting documents are by default composed of a subject (themes) and chronological (see the Google Books, Europeana and Gallica projects) or subject, chronological and spatial (see the Bibliothèque Numérique Mondiale project) dimensions. Here, the IR process implements advanced document management tools. These document management systems are based on metadata composed of descriptive instructions or full-text indexes in which geographical information, toponyms among others, are exploited in the same way as all the other terms.
Concerning the corpus of MIDR, a number of categories of use could be studied.
A qualitative study of the activities of librarians ...