In this ground-breaking practical reference, the family of aspartic acid proteases is described from a drug developer's perspective. The first part provides a general introduction to the family of aspartic acid proteases, their physiological functions, molecular structure and inhibition. Parts two to five present various case studies of successful protease inhibitor drug design and development, as well as current and potential uses of such inhibitors in pharmaceutical medicine, covering the major therapeutic targets HIV-1 protease, renin, beta-secretase, gamma-secretase,plasmepsins and fungal proteases. A ready reference aimed primarily at professionals in the pharmaceutical industry, as well as for anyone studying proteases and their function.
characterizes the kinetics of cleavage of an enzyme–substrate pair
Kcat
turnover number of an enzyme
Km
Michaelis–Menten constant
1.1 Introduction
All cells, tissues, and organisms require proteolysis for the control of metabolism and growth. Even a virus, the smallest nucleic acid-based self-replicating organism, typically requires either host cell proteolysis or enzymes coded by its own genetic material to provide processing of initial viral gene products. Proteolysis is required to activate prohormones and other precursor molecules, to invade into cells and tissues, to release membrane-bound molecules, to provide a cascade effect in a variety of rapid response systems, to regulate cell growth, tissue homeostasis, remodeling, and renewal, and to stimulate cell division, to name but a few vital functions. This applies to pathogenic organisms as well as to normal cells and tissues.
Thus, it is not surprising that proteolytic enzymes from pathogens are targets for drug discovery or that creating molecules that will selectively block the activity of an enzyme from a pathogen, while not harming normal cellular function, is an ongoing endeavor in many pharmaceutical companies and academic labs around the world.
Classically, proteolytic enzymes have been divided into four groups based on their catalytic apparatus: aspartic, cysteine, metallo-, and serine proteases. However, recently, three new systems have been defined: the threonine-based proteosome system [1], the glutamate–glutamine system of eqolisin [2], and the serine–glutamate–aspartate system of sedolisin [3]. It remains to be seen if the proteases mentioned here represent the total spectrum of proteolytic mechanisms available in biology.
This book focuses on the aspartic proteinase family of proteolytic enzymes and specifically on several enzymes that are currently being pursued as drug targets for therapeutic intervention in humans. This chapter will describe several general features of these enzymes to provide a context in which to compare the specific examples found in the following chapters.
The aspartic proteinase family has a long and complicated history. In fact, one of the first processing involving enzyme action was discovered by accident. Legend has it that around 7000 BC, an Arabic traveler placed milk in a pouch made from the stomach of an animal, possibly a sheep or a cow, and set off on a journey across a desert. Different versions of the legend suggest that the traveler was either male or female. Upon reaching the destination, the traveler opened the pouch to find that the milk had coagulated and separated into curd and whey. Sampling the curd, the traveler decided that the process had been productive and it became possible to capture the essential nutrients of milk in a more concentrated and thus easier to carry form. Many centuries later, it was discovered that the enzyme renin, which is contained in the cells lining the stomach cavity of many ruminant animals, was responsible for the cleavage of kappa-casein proteins to cause precipitation that leads to the curd.
The modern history of the aspartic proteinase family can be noted by the publication of the amino acid sequence of porcine pepsin by Jordan Tang and his colleagues at the Oklahoma Medical Research Foundation [4]. This sequence determination was done totally by classical protein chemistry methods, which resulted in information that allowed the necessary primer design to enable the cloning and DNA sequencing of many other members of the family in recent years.
1.2 Sequence Alignment and Family Tree
The MEROPS database (http://merops.sanger.ac.uk/index.htm) contains a full listing of all sequences related to the aspartic proteinase family [5]. Specifically, the A1A family of pepsin-like enzymes contains 1167 entries as of 2009, most of which have been derived from genome sequencing efforts over the past 10 years and some not even assigned a name yet. The A1B family of plant aspartic proteases contains another 406 entries, with each having a “plant-specific” insert of 55 amino acids. The A1B family will not be considered further, although the overall structure of these is very similar to the A1A family.
In addition to the A1A family, the “retropepsin” or A2A family contains another 228 sequences. This represents the retroviral enzymes related to HIV-1 protease as the archetypal member.
Due to the large number of sequences available, it is not feasible to show a sequence alignment or family tree for all the members of the pepsin and retropepsin families. Rather, selected members of the pepsin-like A1A family that are discussed in this book are aligned in Figure 1.1.
1.3 Three-Dimensional Structure
The second watershed event in the history of the aspartic proteinase family was the determination, nearly simultaneously, of the three-dimensional structures of three enzymes from fungi (James [6], Blundell [7], and Davies [8]) and that of porcine pepsin (Andreeva [9]). The structures of the fungal enzyme provided critical information that allowed the correct interpretation of the crystallographic data for porcine pepsin, yielding the structure solution. Remarkably, the overall structures of these enzymes were very similar, although important differences were immediately noted. In particular, by superimposing the N-terminal half of each enzyme, it was possible to see that the C-terminal halves all adopted significantly different orientations, while retaining the same internal architecture.
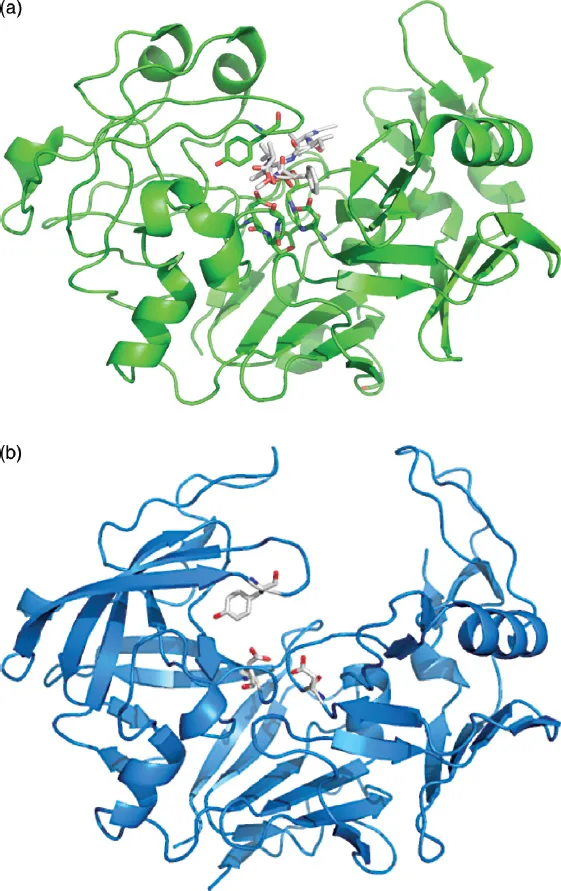
A figure showing the overall structure of the archetypical enzyme in this family, pepsin, is shown in Figure 1.2a, with several residues highlighted. This figure was prepared using PDB file 1QRP [10], a pepsin structure that contains an inhibitor molecule bound in the active site. This is seen in blue sticks in the top middle of the figure and this identifies the active site. Below the inhibitor can be seen the two catalytic aspartic acids in stick representation, which represent two of the regions of identity, one in the N-terminal domain of the enzyme and one in the C-terminal domain. In addition, in each domain, a strand of sequence (D-G-I-L-G-L in the N-terminal domain and I-L-G-D-V-F-I in the C-terminal domain) passes through a wide loop containing the catalytic domain. This is shown in detail in Figure 1.3 for the N-terminal domain. A conserved glycine must appear in the position where the strand passes through the loop due to steric constraints. Any larger residue would not fit in this crowded location. Figure 1.2b shows the structure of the Candida albicans homologue 1EAG [11] and this illustrates the overall secondary structure of the typical aspartic proteinase. Considerable segments of beta structure can be seen, with two orthogonally packed beta sheets in both the N- and C-terminal domains. In addition, at the “bottom” of the enzyme, a six-stranded beta sheet completes the structure. While there is some variation in the size of the beta strands/sheets, this basic structural arrangement is found in all the enzymes of the pepsin family, with a higher degree of variability found in the C-terminal domain.
Figure 1.1 Alignment of amino acid sequences of aspartic proteases discussed in this book. The sequences were truncated at both the amino and carboxyl terminal ends to show the main catalytically active component of each protein. Thus, some membrane spanning segments at either end were deleted for this alignment. The color code is as follows: red font shows the two catalytic aspartic acid residues, one in each of the two structurally similar domains; light green font shows identical amino acids in all the sequences aligned here, also indicated below the alignment by an “*” symbol; sea green shows amino acids that are nearly identical in all sequences with very similar properties in all enzymes, also indicated by a “:” symbol below the alignment; and light blue shows amino acids that are similar in all sequences with similar properties, indicated below the alignment by a “.” symbol. Although the cysteine residues are not completely conserved in this alignment, they are highlighted as
here due to their influence on the three-dimensional structure.
Figure 1.2 (a) Overall structure of pepsin generated by the Pymol program using PDB file 1QRP. A ribbon trace is used to show the backbone structure of the enzyme and a bound inhibitor is shown as sticks. Side chains of the enzyme are shown using stick representation with atoms colored according to the elemental identity (white = carbon; red = oxygen; blue = nitrogen). Only some conserved amino acids from Figure 1.1 are shown in this representation, as described in the text. (b) Figure showing the backbone structure of PDB file 1EAG for candidapepsin plus the two catalytic aspartic acids and Tyr75. This figure shows the orthogonal beta sheets in both the N-terminal domain, on the left-hand side, and the C-terminal domain, on the right-hand side. In addition, the six-stranded beta sheet that makes up the “bottom” of the protein is seen in the lower middle portion of the image. Three small sections of alpha helical structure are seen as well, one in the N-terminal domain and two in the C-terminal domain.
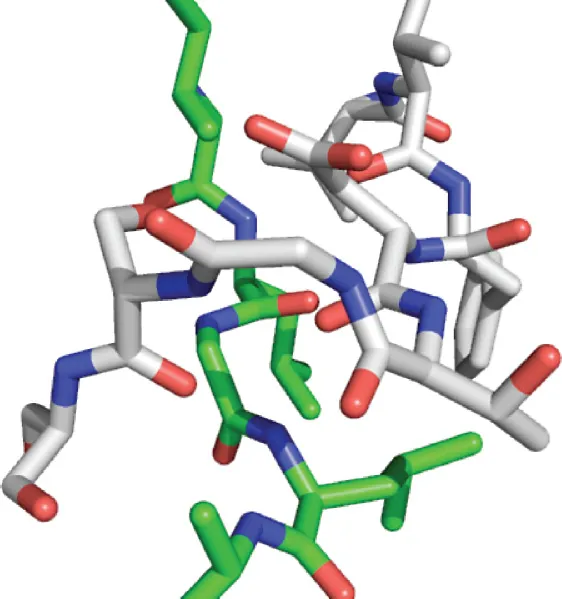
Figure 1.3 View of the N-terminal ψ-loop, where a strand of sequence (green = carbon atoms) passes through the wide loop (white = carbon atoms) that contains Asp32. A glycine must be conserved at the point where the strand passes through the loop for steric reasons.
An important conserved element of the structure is the “ψ-loop,” one found in the N-terminal domain and one found in the C-terminal domain. In this loop, a strand of beta structure passes through a wide loop that contains the catalytic Asp residue. The two “ψ-loops” fix the central structure of the enzyme and thus define the aspartic proteinase catalytic machinery. An illustration is provided in Figure 1.3.
Two additional highly conserved residues are also highlighted in Figure 1.2a: first, Tyr75 of the pepsin sequence is shown. This residue influences substrate selectivity by interaction with amino acids in the P1 and P3 positions, according to the Schechter and Berger nomenclature [12]. In addition, Trp39, while not strictly conserved throughout the family (it is replaced by an Ala in BACE-1), plays an important role in stabilizing the internal core of the N-terminal domain and interacts with Tyr75 through a hydrogen bond in some structures, as shown in Figure 1.4.
In addition to the regions of identity or strong similarity, there are several places where gaps occur in the alignment shown in Figure 1.1. As can be seen in Figure 1.5, the points where gaps of more than two amino acids occur in comparison to the pepsin structure tend to occur on the surface of the proteins and are most likely insertions of sequences to expand or contract a loop to provide some specific property, such as interaction with a receptor or a binding partner. In terms of catalytic function, it is believed that these points do not influence either the rate of cleavage or the substrate specificity of the enzymes.
Figure 1.4 A view of Trp39 and Tyr75, showing that a hydrogen bond could form between the −OH of Tyr75 and the r...
Table of contents
Cover
Title
Copyright
Preface
List of Contributors
A Personal Foreword
Part One: Overview of Aspartic Acid Proteases
Part Two: HIV-1 Protease as Target for the Treatment of HIV/AIDS
Part Three: Renin as Target for the Treatment of Hypertension
Part Four: γ-Secretase as Target for the Treatment of Alzheimer’s Disease
Part Five: β-Secretase as Target for the Treatment of Alzheimer’s Disease
Part Six: Plasmepsins and Other Aspartic Proteases as Drug Targets
Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Aspartic Acid Proteases as Therapeutic Targets by Arun K. Ghosh, Raimund Mannhold,Hugo Kubinyi,Gerd Folkers in PDF and/or ePUB format, as well as other popular books in Medicine & Pharmacology. We have over one million books available in our catalogue for you to explore.