
eBook - ePub
Deep Learning with Python
Francois Chollet
This is a test
Share book
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Deep Learning with Python
Francois Chollet
Book details
Book preview
Table of contents
Citations
About This Book
Deep Learning with Python introduces the field of deep learning using the Python language and the powerful Keras library. Written by Keras creator and Google AI researcher François Chollet, this book builds your understanding through intuitive explanations and practical examples.
Frequently asked questions
How do I cancel my subscription?
Can/how do I download books?
At the moment all of our mobile-responsive ePub books are available to download via the app. Most of our PDFs are also available to download and we're working on making the final remaining ones downloadable now. Learn more here.
What is the difference between the pricing plans?
Both plans give you full access to the library and all of Perlego’s features. The only differences are the price and subscription period: With the annual plan you’ll save around 30% compared to 12 months on the monthly plan.
What is Perlego?
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 1000+ topics, we’ve got you covered! Learn more here.
Do you support text-to-speech?
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more here.
Is Deep Learning with Python an online PDF/ePUB?
Yes, you can access Deep Learning with Python by Francois Chollet in PDF and/or ePUB format, as well as other popular books in Ciencia de la computación & Programación en Python. We have over one million books available in our catalogue for you to explore.
Information
Subtopic
Programación en PythonPart 1. Fundamentals of deep learning
Chapters 1–4 of this book will give you a foundational understanding of what deep learning is, what it can achieve, and how it works. It will also make you familiar with the canonical workflow for solving data problems using deep learning. If you aren’t already highly knowledgeable about deep learning, you should definitely begin by reading part 1 in full before moving on to the practical applications in part 2.
Chapter 1. What is deep learning?
This chapter covers
- High-level definitions of fundamental concepts
- Timeline of the development of machine learning
- Key factors behind deep learning’s rising popularity and future potential
In the past few years, artificial intelligence (AI) has been a subject of intense media hype. Machine learning, deep learning, and AI come up in countless articles, often outside of technology-minded publications. We’re promised a future of intelligent chatbots, self-driving cars, and virtual assistants—a future sometimes painted in a grim light and other times as utopian, where human jobs will be scarce and most economic activity will be handled by robots or AI agents. For a future or current practitioner of machine learning, it’s important to be able to recognize the signal in the noise so that you can tell world-changing developments from overhyped press releases. Our future is at stake, and it’s a future in which you have an active role to play: after reading this book, you’ll be one of those who develop the AI agents. So let’s tackle these questions: What has deep learning achieved so far? How significant is it? Where are we headed next? Should you believe the hype?
This chapter provides essential context around artificial intelligence, machine learning, and deep learning.
1.1. Artificial intelligence, machine learning, and deep learning
First, we need to define clearly what we’re talking about when we mention AI. What are artificial intelligence, machine learning, and deep learning (see figure 1.1)? How do they relate to each other?
Figure 1.1. Artificial intelligence, machine learning, and deep learning
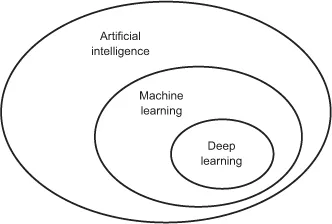
1.1.1. Artificial intelligence
Artificial intelligence was born in the 1950s, when a handful of pioneers from the nascent field of computer science started asking whether computers could be made to “think”—a question whose ramifications we’re still exploring today. A concise definition of the field would be as follows: the effort to automate intellectual tasks normally performed by humans. As such, AI is a general field that encompasses machine learning and deep learning, but that also includes many more approaches that don’t involve any learning. Early chess programs, for instance, only involved hardcoded rules crafted by programmers, and didn’t qualify as machine learning. For a fairly long time, many experts believed that human-level artificial intelligence could be achieved by having programmers handcraft a sufficiently large set of explicit rules for manipulating knowledge. This approach is known as symbolic AI, and it was the dominant paradigm in AI from the 1950s to the late 1980s. It reached its peak popularity during the expert systems boom of the 1980s.
Although symbolic AI proved suitable to solve well-defined, logical problems, such as playing chess, it turned out to be intractable to figure out explicit rules for solving more complex, fuzzy problems, such as image classification, speech recognition, and language translation. A new approach arose to take symbolic AI’s place: machine learning.
1.1.2. Machine learning
In Victorian England, Lady Ada Lovelace was a friend and collaborator of Charles Babbage, the inventor of the Analytical Engine: the first-known general-purpose, mechanical computer. Although visionary and far ahead of its time, the Analytical Engine wasn’t meant as a general-purpose computer when it was designed in the 1830s and 1840s, because the concept of general-purpose computation was yet to be invented. It was merely meant as a way to use mechanical operations to automate certain computations from the field of mathematical analysis—hence, the name Analytical Engine. In 1843, Ada Lovelace remarked on the invention, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.... Its province is to assist us in making available what we’re already acquainted with.”
This remark was later quoted by AI pioneer Alan Turing as “Lady Lovelace’s objection” in his landmark 1950 paper “Computing Machinery and Intelligence,”[1] which introduced the Turing test as well as key concepts that would come to shape AI. Turing was quoting Ada Lovelace while pondering whether general-purpose computers could be capable of learning and originality, and he came to the conclusion that they could.
1A. M. Turing, “Computing Machinery and Intelligence,” Mind 59, no. 236 (1950): 433-460.
Machine learning arises from this question: could a computer go beyond “what we know how to order it to perform” and learn on its own how to perform a specified task? Could a computer surprise us? Rather than programmers crafting data-processing rules by hand, could a computer automatically learn these rules by looking at data?
This question opens the door to a new programming paradigm. In classical programming, the paradigm of symbolic AI, humans input rules (a program) and data to be processed according to these rules, and out come answers (see figure 1.2). With machine learning, humans input data as well as the answers expected from the data, and out come the rules. These rules can then be applied to new data to produce original answers.
Figure 1.2. Machine learning: a new programming paradigm
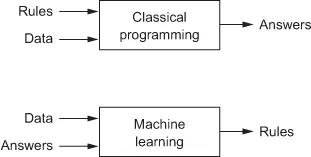
A machine-learning system is trained rather than explicitly programmed. It’s presented with many examples relevant to a task, and it finds statistical structure in these examples that eventually allows the system to come up with rules for automating the task. For instance, if you wished to automate the task of tagging your vacation pictures, you could present a machine-learning system with many examples of pictures already tagged by humans, and the system would learn statistical rules for associating specific pictures to specific tags.
Although machine learning only started to flourish in the 1990s, it has quickly become the most popular and most successful subfield of AI, a trend driven by the availability of faster hardware and larger datasets. Machine learning is tightly related to mathematical statistics, but it differs from statistics in several important ways. Unlike statistics, machine learning tends to deal with large, complex datasets (such as a dataset of millions of images, each consisting of tens of thousands of pixels) for which classical statistical analysis such as Bayesian analysis would be impractical. As a result, machine learning, and especially deep learning, exhibits comparatively little mathematical theory—maybe too little—and is engineering oriented. It’s a hands-on discipline in which ideas are proven empirically more often than theoretically.
1.1.3. Learning representations from data
To define deep learning and understand the difference between deep learning and other machine-learning approaches, first we need some idea of what machine--learning algorithms do. I just stated that machine learning discovers rules to execute a data-processing task, given examples of what’s expected. So, to do machine learning, we need three things:
- Input data points— For instance, if the task is speech recognition, these data points could be sound files of people speaking. If the task is image tagging, they could be pictures.
- Examples of the expected output— In a speech-recognition task, these could be human-generated transcripts of sound files. In an image task, expected outputs could be tags such as “dog,” “cat,” and so on.
- A way to measure whether the algorithm is doing a good job— This is necessary in order to determine the distance between the algorithm’s current output and its expected output. The measurement is used as a feedback signal to adjust the way the algorithm works. This adjustment step is what we call learning.
A machine-learning model transforms its input data into meaningful outputs, a process that is “learned” from exposure to known examples of inputs and outputs. Therefore, the central problem in machine learning and deep learning is to meaningfully transform data: in other words, to learn useful representations of the input data at hand—representations that get us closer to the expected output. Before we go any further: what’s a representation? At its core, it’s a different way to look at data—to represent or encode data. For instance, a color image can be encoded in the RGB format (red-green-blue) or in the HSV format (hue-saturation-value): these are two different representations of the same data. Some tasks that may be difficult with one representation can become easy with another. For example, the task “select all red pixels in the image” is simpler in the RGB format, whereas “make the image less saturated” is simpler in the HSV format. Machine-learning models are all about finding appropriate representations for their input data—transformations of the data that make it more amenable to the task at hand, such as a classification task.
Let’s make this concrete. Consider an x-axis, a y-axis, and some points represented by their coordinates in the (x, y) system, as shown in figure 1.3.
Figure 1.3. Some sample data
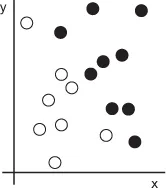
As you can see, we have a few white points and a few black points. Let’s say we want to develop an algorithm that can take the coordinates (x, y) of a point and output whether that point is likely to be black or to be white. In this case,
- The inputs are the coordinates of our points.
- The expected outputs are the colors of our points.
- A way to measure whether our algorithm is doing a good job could be, for instance, the percentage of points that are being correctly classified.
What we need here is a new representation of our data that cleanly separates the white points from the black points. One transformation we could use, among many other possibilities, would be a coordinate change, illustrated in figure 1.4.
Figure 1.4. Coordinate change
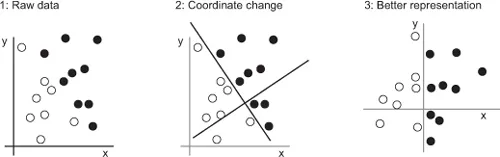
In this new coordinate system, the coordinates of our points can be said to be a new representation of our data. And it’s a good one! With this representation, the black/white classification problem can be expressed as a simple rule: “Black points are such that x > 0,” or “White points are such that x < 0.” This new representation basically solves the classification problem.
In this case, we defined the coordinate change by hand. But if instead we tried systematically searching for different possible coordinate changes, and used as feedback the percentage of points being correctly classified, then we would be doing machine learning. Learning, in the context of machine learning, describes an automatic search process for better representations.
All machine-learni...