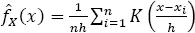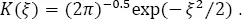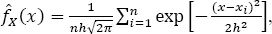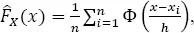1.1. Introduction
The basis of statistical seismology is the probabilistic distribution of earthquake parameters. Unfortunately, the models of probabilistic distributions of earthquake parameters are mostly unknown, and those which are thought to be known are often disproved by more thorough testing.
On the other hand, increasing quality and decreasing prices of seismic monitoring systems, increasing density of seismic networks and the development of event picking tools cause the current seismic catalogs to be large and rising. This situation opens up the area for model-free approaches to probabilistic estimation and statistical inferences, which to be accurate, require considerable sample sizes.
The kernel density estimation is a model-free estimation of probability functions of continuous random variables. The estimation is carried out solely from sample data.
There is no attempt here to comprehensively present the kernel density estimation method. A detailed description and the discussion of the method can be found in the textbooks by Silverman (1986), Wand and Jones (1995), Scott (2015) and in a multitude of high-level research papers. The method is also implemented in Matlab, R and Python, among others, and in many statistical packages. In this chapter, the author presents how this method has been applied to selected problems of seismology. This presentation begins with a short and simplified theoretical introduction. The kernel density estimation has been fast developing from both theoretical and practical sides; hence, the techniques presented here do not aspire to be optimal. There is plenty of space for future modifications and developments.
In the case of a univariate random variable X, and a constant kernel, the kernel estimator of the actual probability density function (PDF) of X, fX(x), takes the form:
where {xi}, i = 1,.., n is the sample data, K(•) is the kernel function, which is a PDF symmetric about zero, and h is the bandwidth, whose value decides how much smoothing has been applied to the sample data.
In the presented seismological applications of the kernel density estimation, we use the normal kernel function:
For this kernel function, the kernel estimates of PDF and the cumulative distribution function (CDF,
) are, respectively:
where Ф(·) is the CDF of standard normal distribution.
As it will follow, the kernel method is used, among others, to estimate the magnitude distribution, whose distribution is exponential-like or light-tailed. Because of that, the tail values are sparse in a sample. Such sparsity can result in spurious irregularities in the estimate on tails, if a constant bandwidth is used. We can alleviate this problem by using an adaptive kernel with variable bandwidth. Because the estimates of magnitude distribution functions serve in the probabilistic seismic hazard analysis (PSHA), the quality of the estimate...