Explore Machine Learning Techniques, Different Predictive Models, and its Applications
Key Features
? Extensive coverage of real examples on implementation and working of ML models.
? Includes different strategies used in Machine Learning by leading data scientists.
? Focuses on Machine Learning concepts and their evolution to algorithms.
Description
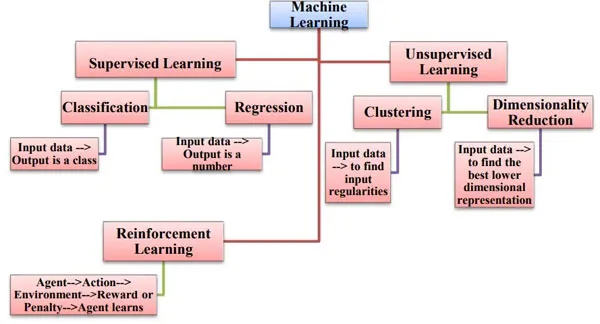
This book covers basic concepts of Machine Learning, various learning paradigms, different architectures and algorithms used in these paradigms.You will learn the power of ML models by exploring different predictive modeling techniques such as Regression, Clustering, and Classification. You will also get hands-on experience on methods and techniques such as Overfitting, Underfitting, Random Forest, Decision Trees, PCA, and Support Vector Machines. In this book real life examples with fully working of Python implementations are discussed in detail.At the end of the book you will learn about the unsupervised learning covering Hierarchical Clustering, K-means Clustering, Dimensionality Reduction, Anomaly detection, Principal Component Analysis.
What you will learn
? Learn to perform data engineering and analysis.
? Build prototype ML models and production ML models from scratch.
? Develop strong proficiency in using scikit-learn and Python.
? Get hands-on experience with Random Forest, Logistic Regression, SVM, PCA, and Neural Networks.
Who this book is for
This book is meant for beginners who want to gain knowledge about Machine Learning in detail. This book can also be used by Machine Learning users for a quick reference for fundamentals in Machine Learning. Readers should have basic knowledge of Python and Scikit-Learn before reading the book.
Table of Contents
1. Introduction to Machine Learning
2. Linear Regression
3. Classification Using Logistic Regression
4. Overfitting and Regularization
5. Feasibility of Learning
6. Support Vector Machine
7. Neural Network
8. Decision Trees
9. Unsupervised Learning
10. Theory of Generalization
11. Bias and Fairness in ML
About the Authors
Dr Deepti Chopra is working as an Assistant Professor (IT) at Lal Bahadur Shastri Institute of Management, Delhi. She has around 7 years of teaching experience. Her areas of interest include Natural Language Processing, Computational Linguistics, and Artificial Intelligence. She is the author of three books and has written several research papers in various international conferences and journals.