The world is on the verge of fully ushering in the fourth industrial revolution, of which artificial intelligence (AI) is the most important new general-purpose technology. Like the steam engine that led to the widespread commercial use of driving machineries in the industries during the first industrial revolution; the internal combustion engine that gave rise to cars, trucks, and airplanes; electricity that caused the second industrial revolution through the discovery of direct and alternating current; and the Internet, which led to the emergence of the information age, AI is a transformational technology. It will cause a paradigm shift in the way's problems are solved in every aspect of our lives, and, from it, innovative technologies will emerge. AI is the theory and development of machines that can imitate human intelligence in tasks such as visual perception, speech recognition, decision-making, and human language translation.
This book provides a complete overview on the deep learning applications and deep neural network architectures. It also gives an overview on most advanced future-looking fundamental research in deep learning application in artificial intelligence. Research overview includes reasoning approaches, problem solving, knowledge representation, planning, learning, natural language processing, perception, motion and manipulation, social intelligence and creativity. It will allow the reader to gain a deep and broad knowledge of the latest engineering technologies of AI and Deep Learning and is an excellent resource for academic research and industry applications.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Artificial Intelligence (AI) is everywhere at the moment, including virtual assistants, image recognition systems, search recommendation systems, and other applications. And there is a good chance that you are probably using one of the top AI applications during your daily life. Consequently, AI is a powerful and interesting tool that is getting more and more attention day by day.
There are many terms associated with AI, such as Machine Learning (ML), Neural Networks (NN), etc. So, we can think of AI as a super class that includes all of these subsets, and with the main purpose of making computer systems perform actions which will be considered intelligent [208, 194]. However, it is difficult to give a definition for computational intelligence because it is strongly associated with that period of time. While technology advances, the previous benchmarks that defined the term of intelligence become outdated. For example, the action of recognizing text through optical character recognition was described as intelligent a long time ago. This functionality is no longer considered to be intelligent for machines at this time, as this function is now taken for granted as a general feature for computing systems. Consequently, the demand for computer intelligence and AI is changing every year. Currently, the goals of AI include reasoning, learning, planning, perception, knowledge representation and creativity. There is already a lot of research work going on towards creating computing systems that will achieve these goals [45, 148, 146, 21, 192]. However, there is still a long way to go, and AI will continue to act as a technological innovator for the foreseeable future.
One of the more popular terms in recent times is Deep Learning (DL), which describes certain types of NNs and related algorithms that often process very raw input data through many layers of nonlinear transformations [64]. The DL associated algorithms are used not only for supervised learning problems, but also for unsupervised and reinforcement learning problems. In supervised learning, the model learns from a supervised labeled data set with guidance, whereas in unsupervised learning, the machine learns from the unlabeled input data set without any guidance. Compared to these two learning methods, during reinforcement learning, the machine interacts with its environment and learns by trial and error method [175]. For example, DL also excels in the field of unsupervised feature extraction for automatically deriving or constructing meaningful features of the input data that will be used for further learning. To better understand DL concepts, we will first review the idea behind NNs.
Artificial Neural Networks (ANNs) are computing systems that try to replicate the idea of biological neural networks in animal brains [223, 76]. Different parts of the brain are responsible for processing various pieces of information, and these parts of the brain are arranged hierarchically, so called in layers. Therefore, ANNs are trying to simulate this layered approach of processing information and making decisions. Such computational models are learning and improving their knowledge based on the given examples. In its simplest form, an ANN can only have three layers of neurons. The input layer is designed for entering the data set into the system. Then, the hidden layer processes the information, while at the output layer, the system decides what to do based on the processed data. However, ANNs can get much more complex than that, and include several hidden layers. The part of the broader family of ANN that is made up of more than three layers (multiple hidden layers) is called a Deep Neural Network (DNN), and this is what lies at the heart of DL (Fig. 1.1). Different layers of DNN are required to extract different features until they can recognize what they are looking for.
The DL learning system is self-learning as it progresses by filtering information through multiple hidden layers, similar to the human brain [64]. The DNN model consists of artificial neurons (represented by circles in Fig. 1.1), which are organized into layers that perform various transformations on their inputs. The number of neurons in the first input layer is defined by the input data set. The input layer passes the inputs to the first hidden layer, that performs mathematical computations on the input data. One of the difficulties when creating DNNs is determining the number of hidden layers and the number of neurons for each layer. One thing is clear: whether it be three layers or more, information flows from one layer to another, just like in the human brain. The connection between neurons (synapses) can transfer a signal from one neuron to another. These signals travel from the first (input) layer to the last (output) one, usually after passing a hidden layer consisting of units that transform the input into something that the output layer can use Fig. 1.1. These are excellent machine learning tools for finding patterns which are far too complex for a programmer to extract and teach the machine to recognize. At the end, the output layer returns back the calculated output data. The basic math, the main concepts (including neurons, weights, biases, synapses and functions that try to replicate the human brains) and how DNNs calculate the final results will be thoroughly described in Chapter 2.
As brain-inspired systems designed to replicate the way humans learn, NNs modify their own code to find the connection between input and output. Hence, AI has benefited greatly from the arrival of NNs and DL. So, how does DNN work in general? Humans learn from their everyday experiences. The tasks they do over and over again gradually become more efficient and the percentage of errors/mistakes decreases. Following the same principle, the NNs also require data for training, and more data should be used in advance to get accurate results. In general, there are three main sets of data that need to be divided when working with NNs. First, this is the so-called training set, which helps NN establish various weights between its nodes. Second is a validation set required for fine tuning Finally, the third is a test set to check if it can successfully turn input into desired output. Once this is done, the researchers who have trained the network can label the output, and then use back-propagation to correct any mistakes which have been made. After a while, the network will be able to carry out its own classification tasks without needing the help of researchers each time.
Figure1.1: The structure of deep neural networks.
All of these NNs come with their own complexities and use cases, which we will discuss in Chapter 3. In addition, choosing the correct NN for a task depends on the data set and the specific application for which it will be used. There are still many challenges for NNs that researchers are working on to address. One of the biggest issues is training time, which increases with the complexity of the task. Usually the computation time is higher due to the many training parameters NNs required. The next challenge is that NNs are black boxes, where the user feeds in data and receives answers. Thus, users are not involved in the decision-making process, which complicates the situation. There are also some challenges on the technical level, such as overfitting, which is the result of multiple abstraction layers.
Nowadays, NNs typically have from a few thousand to several million units with millions of connections. However, this number is still several orders of magnitude less than the number of neurons in the human brain, which means that these networks can perform many tasks at a level beyond that of humans. Thus, there is still a lot of work to be done to achieve all the goals of AI and to actually simulate the human brain.
1.2 Evolution: Where are We Now?
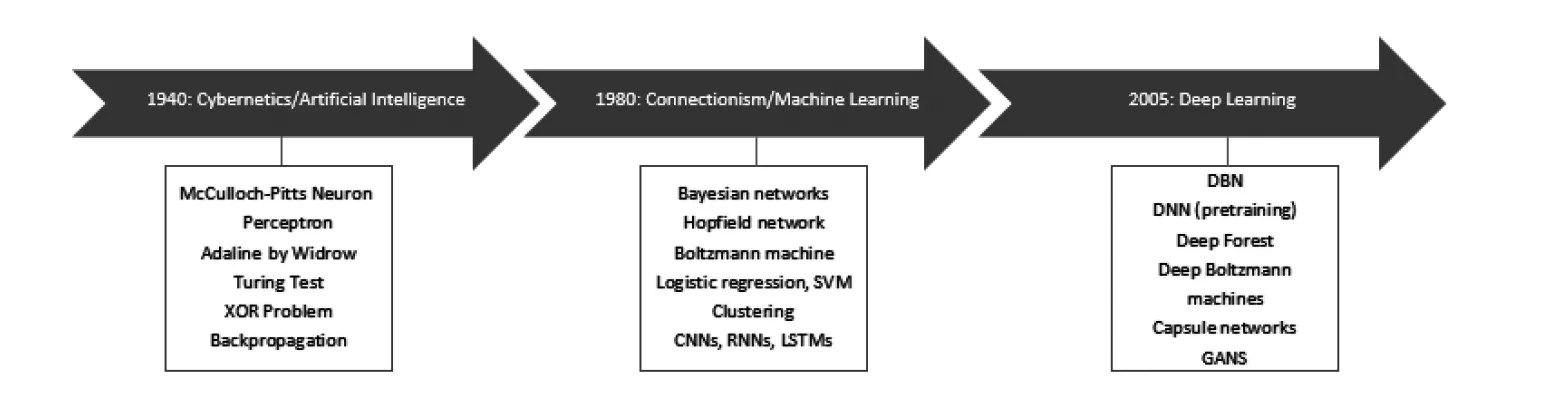
When we think of AI or NNs, most of us refer to 21st century inventions. To all our surprise, the concept of NNs actually dates back to the 1940s [72]. One of the reasons most of us think it is a new invention is that in the early stages, the approaches and algorithms were unpopular due to their various shortcomings However, it is important to note that some of the algorithms developed in those old times are still widely used today in different DL approaches.
In the early stages, researchers were trying to replicate human intelligence only for specific tasks, such as winning games. A bright example is the Deep Blue machine, developed by IBM to win a chess match against a world champion [25]. In such systems, in order to achieve better results in solving specific tasks, researchers introduced a number of rules that the computing system needed to follow. In the end, to win the game, the computing system made decisions based on already defined rules. At this early stage, advancements were made in the name of cybernetics based on the idea of biological learning [112]. Cybernetics has been started by the development of McCulloch-Pitts Neuron for simulating the biological neuron [133], followed by the Perceptron, developed by Frank Rosenblatt for learning weights automatically [169]. However, it has been proven that single-layer Perceptrons could not solve the seemingly simple XOR (exclusive OR) classification problem [135].
Figure1.2: : The timeline of AI, ML and DL.
In Fig. 1.2, we show a timeline of AI, ML and DL development, as well as the main inventions over these periods. AI research began as an academic discipline in its own right in 1956, inspired by the work of the renowned mathematician Alan Turing. In his seminal paper “Computing Machinery and Intelligence”, which was published in the philosophical journal “Mind” in 1950, Turing proposed the possibility of thinking machines [198]. In the test, if a human evaluator cannot determine whether is talking to a machine or to a human based on text conversations, then the machine has passed the test. In 1956 a conference took place at Dartmouth College, in Hanover, New Hampshire — the Dartmouth Summer Research Project on Artificial Intelligence - where the term “artificial intelligence” emerged [112]. Later, the Alan Turing test became widely used to measure the intelligence of the very first chatbots, such as ELIZA [209], and only in 2014 the first machine, Eugene Goostman, passed the test [180]. In the period of cybernetics, as with the Turing test, there were many inventions that are still used in modern approaches. For example, back-propagation techniques or the Adaline learning function developed by Bernard Widrow, which is similar to the stochastic gradient descent, currently used in modern approaches [210].
Connectionism became popular in the early 1980s when Parallel Distributed Processing started to be widely used. It was a first movement in cognitive science that tries to understand how the human brain works at the neural level [19]. This was a period when ML and NNs attracted the attention of researchers. It referred to the ability of computing systems to learn their next actions using large data sets instead of hard-coded rules. Hence, ML has allowed computers to learn on their own and make decisions based on their past experience. Various models were developed such as Long Short-Term Memories (LSTM), Convolutional Neural Networks (CNN), Support Vector Machines (SVM) or Boltzmann machines, which still remain key components of different advanced applications of ML and DL [31]. However, during connectionism, all these methods did not get wide usage and did not achieve the promised results due to a lack of computational resources.
Later, in 2006 the third wave of DL started, and it became possible due to the processing power of modern computers that can easily process large sets of input data. Actually, the expression DL was first used when talking about ANNs by Igor Aizenberg and colleagues around 2000 [4]. We can think of DL as a method for training machines with thousands, or even millions of artificial neurons. Until now, many different approaches have been invented to solve the problems encountered when training traditional neural networks, such as slow learning or the requirement of a big training data set. One of this new inventions is Deep Belief Networks (DBN), introduced by Geoffrey Hinton and used Greedy Layer-wise Training [82], with simple implementations were Boltzmann machines. Generative Adversarial Networks (GAN) enable models to solve unsupervised learning, which is more or less the ultimate goal of the AI community [65]. The advancement of DNNs also helps to overcome the shortcomings of the initial problems that were associated with rule-based solutions. Previously, a researcher would teach a computing system the rules, rather the machine learning them on its own. This was a limited solution that required researchers to constantly intervene in the process, and it was solved through the development of DNN. For example, compared to Deep Blue, AlphaGO won the world championship in Go by training and learning itself on a large data set of expert movements [204]. Consequently, the DL breakthrough has completely changed the development of AI, becoming part of our daily life. The Facebook social network, Google search engine and Youtube recommendation engine all use DL.
Hence, aided by the arrival of DNNs and the algorithms from the Connec-tionism period, AI has started to truly live up to its potential today. Currently, this renewed interest in DL is mainly associated with factors below:
Capabilities of modern computers,
Access to open-source libraries such as Keras, TensorFlow, PyTorch [202],
Available large data based on online services, which increases the accuracy for various models.
Although we are still in the early stages of AI and DL adoption, we have already seen significant impact across nearly every industry. Self-driving car...
Table of contents
Cover Page
Title Page
Copyright Page
Dedication
Foreword
Preface
Table of Contents
1. Introduction
2. Deep Learning Basics
3. Neural Network Structures
4. Top Applications of Deep Learning Across Industries
5. Discussions and Criticism
References
Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Deep Neural Network Applications by Hasmik Osipyan,Bosede Iyiade Edwards,Adrian David Cheok in PDF and/or ePUB format, as well as other popular books in Computer Science & Computer Science General. We have over 1.5 million books available in our catalogue for you to explore.