Build production-grade machine learning models with Amazon SageMaker Studio, the first integrated development environment in the cloud, using real-life machine learning examples and codeKey Features• Understand the ML lifecycle in the cloud and its development on Amazon SageMaker Studio• Learn to apply SageMaker features in SageMaker Studio for ML use cases• Scale and operationalize the ML lifecycle effectively using SageMaker StudioBook DescriptionAmazon SageMaker Studio is the first integrated development environment (IDE) for machine learning (ML) and is designed to integrate ML workflows: data preparation, feature engineering, statistical bias detection, automated machine learning (AutoML), training, hosting, ML explainability, monitoring, and MLOps in one environment. In this book, you'll start by exploring the features available in Amazon SageMaker Studio to analyze data, develop ML models, and productionize models to meet your goals. As you progress, you will learn how these features work together to address common challenges when building ML models in production. After that, you'll understand how to effectively scale and operationalize the ML life cycle using SageMaker Studio. By the end of this book, you'll have learned ML best practices regarding Amazon SageMaker Studio, as well as being able to improve productivity in the ML development life cycle and build and deploy models easily for your ML use cases.What you will learn• Explore the ML development life cycle in the cloud• Understand SageMaker Studio features and the user interface• Build a dataset with clicks and host a feature store for ML• Train ML models with ease and scale• Create ML models and solutions with little code• Host ML models in the cloud with optimal cloud resources• Ensure optimal model performance with model monitoring• Apply governance and operational excellence to ML projectsWho this book is forThis book is for data scientists and machine learning engineers who are looking to become well-versed with Amazon SageMaker Studio and gain hands-on machine learning experience to handle every step in the ML lifecycle, including building data as well as training and hosting models. Although basic knowledge of machine learning and data science is necessary, no previous knowledge of SageMaker Studio and cloud experience is required.

- 326 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Getting Started with Amazon SageMaker Studio
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Part 1 – Introduction to Machine Learning on Amazon SageMaker Studio
In this section, we will cover an introduction to machine learning (ML), the ML life cycle in the cloud, and Amazon SageMaker Studio. This section also includes a level set on the domain terminology in ML with example use cases.
This section comprises the following chapters:
- Chapter 1, Machine Learning and Its Life Cycle in the Cloud
- Chapter 2, Introducing Amazon SageMaker Studio
Chapter 1: Machine Learning and Its Life Cycle in the Cloud
Machine Learning (ML) is a technique that has been around for decades. It is hard to believe how ubiquitous ML is now in our daily life. It has also been a rocky road for the field of ML to become mainstream, until the recent major leap in computer technology. Today's computer hardware is faster, smaller, and smarter. Internet speeds are faster and more convenient. Storage is cheaper and smaller. Now, it is rather easy to collect, store, and process massive amounts of data with the technology we have now. We are able to create sizeable datasets that we were not able to before, train ML models using compute resources that were not available before, and make use of ML models in every corner of our lives.
For example, media streaming companies can now build ML recommendation engines at a global scale using their title collections and customer activity data on their websites to provide the most relevant content in real time in order to optimize the customer experience. The size of the data for both the titles and customer preferences and activity is on a scale that wasn't possible 20 years ago, considering how many of us are currently using a streaming service.
Training an ML model at this scale, using ML algorithms that are becoming increasingly more complex, requires a robust and scalable solution. After a model is trained, companies are able to serve the model at a global scale where millions of users visit the application from web and mobile devices at the same time.
Companies are also creating more and more models for each segment of customers or even one model for one customer. There is another dimension to this – companies are rolling out new models at a pace that would not have been possible to manage without a pipeline that trains, evaluates, tests, and deploys a new model automatically. Cloud computing has provided a perfect foundation for the streaming service provider to perform these ML activities to increase customer satisfaction.
If ML is something that interests you, or if you are already working in the field of ML in any capacity, this book is the right place for you. You will be learning all things ML, and how to build, train, host, and manage ML models in the cloud with actual use cases and datasets along with me throughout the book. I assume you come to this book with a good understanding of ML and cloud computing. The purpose of this first chapter is to set the level of the concepts and terminology of the two technologies, to define the ML life cycle that is going to be the core of this book, and to provide a crash course on Amazon Web Services and its core services, which will be mentioned throughout the book.
In this chapter, we will cover the following:
- Understanding ML and its life cycle
- Building ML in the cloud
- Exploring AWS essentials for ML
- Setting up AWS environment
Technical requirements
For this chapter, you will need a computer with an internet connection and a browser to perform the basic AWS account setup in order to run Amazon SageMaker setup and code samples in the following chapters.
Understanding ML and its life cycle
At its core, ML is a process that uses computer algorithms to automatically discover the underlying patterns and trends in a dataset (which is a collection of observations with features, also known as variables), make a prediction, obtain the error measure against a ground truth (if provided), and "learn" from the error with an optimization process in order to make a prediction next time. At the end of the process, an ML model is fitted or trained so that it can be used to apply the knowledge it learned to apply a decision based on the features of a new observation. The first part, generating a model, is called training, while the second part is called prediction or inference.
There are three basic types of ML algorithms based on the way the training process takes place – supervised learning, unsupervised learning, and reinforcement learning. A supervised learning algorithm is given a set of observations with a ground truth from the past. A ground truth is a key ingredient to train a supervised learning algorithm, as it drives how the model learns and makes future predictions – hence the "supervised" in the name, as the learning is supervised by the ground truth. Unsupervised learning, on the other hand, does not require a ground truth for the observations to learn how to apply the prediction. It finds patterns and relationships solely based on the features of the observations. However, a ground truth, if it exists, would still help us validate and understand the accuracy of the model in the case of unsupervised learning. Reinforcement learning, often abbreviated as RL, has quite a different learning paradigm compared to the previous two. RL consists of an agent interacting with an environment with a set of actions, and corresponding rewards and states. The learning is not guided by a ground truth, rather by optimizing cumulative rewards with actions. The trained model in the end would be able to perform actions autonomously in an environment that would achieve the best rewards.
An ML life cycle
Now we have a basic understanding of what ML is, we can go broader to see what a typical ML life cycle looks like, as illustrated in the following figure:
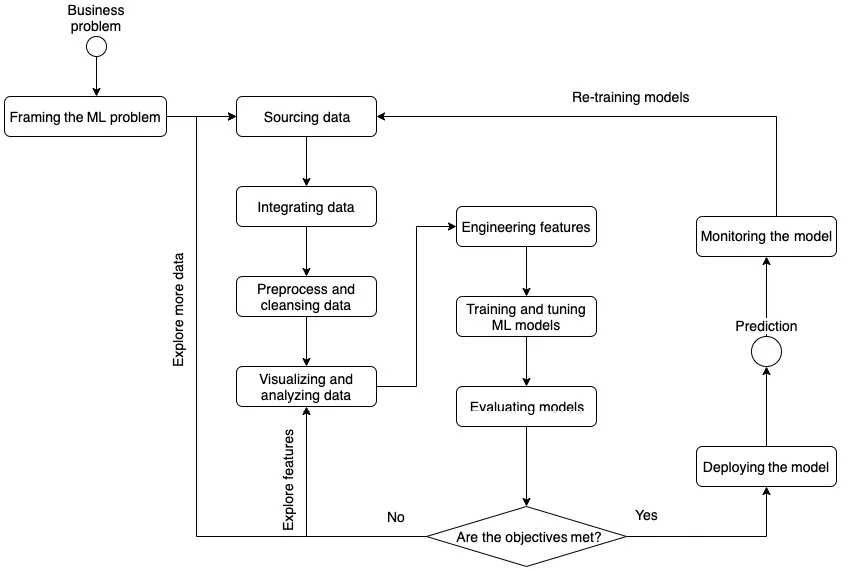
Figure 1.1 – The ML life cycle
Problem framing
The first step in a successful ML life cycle is framing the business problem into an ML problem. Business problems come in all shapes and forms. For example, "How do we increase sales of a newly released product?" and "How do we improve the QA Quality Assessment (QA) throughput on the assembly line?" Business problems such as these, usually qualitative, are not something ML can be directly applied to. But looking at the business problem statement, we should think about how it can be translated into an ML problem. We should ask questions like the following:
- "What are the key factors to the success of product sales?"
- "Who are the people that are most likely to purchase the product?"
- "What is the bottleneck in throughput in the assembly line?"
- "How do we know whether an item is defective? What differentiates a defective one from a normal one?"
By asking questions like these, we start to dig into the realm of pattern recognition, a process of recognizing patterns from the data at hand. Having the right questions that can be formulated into pattern recognition, we are a step closer to framing an ML problem. Then, we also need to understand what the key metric is to gauge the success of an approach, regardless of whether we use ML or other approaches. It is quite straightforward to measure, for example, daily product sales. We can also improve sales by targeting advertisements to the people that are mostly like to convert. Then, we get questions like the following:
- "How do we measure the conversion?"
- "What are the common characteristics of the consumers who have bought this product?"
More importantly, we need to find out whether there is even a target metric for us to predict! If there are targets, we can frame the problem as an ML problem, such as predicting future sales (supervised learning and regression), predicting whether a customer is going to buy a certain product or not (supervised learning and classification), or identifying defective items (supervised learning and classification). Questions that do not have a clear target to predict would fall into an unsupervised learning task in order to apply the pattern discovered in the data to future data points. Use cases where the target is dynamic and of high uncertainty, such as autonomous driving, robotic control, and stock price prediction, are good candidates for RL.
Data exploration and engineering
Sourcing data is the first step of a successful ML modeling journey. Once we have clearly defined both our b...
Table of contents
- Contributors
- Preface
- Part 1 – Introduction to Machine Learning on Amazon SageMaker Studio
- Chapter 1: Machine Learning and Its Life Cycle in the Cloud
- Chapter 2: Introducing Amazon SageMaker Studio
- Part 2 – End-to-End Machine Learning Life Cycle with SageMaker Studio
- Chapter 3: Data Preparation with SageMaker Data Wrangler
- Chapter 4: Building a Feature Repository with SageMaker Feature Store
- Chapter 5: Building and Training ML Models with SageMaker Studio IDE
- Chapter 6: Detecting ML Bias and Explaining Models with SageMaker Clarify
- Chapter 7: Hosting ML Models in the Cloud: Best Practices
- Chapter 8: Jumpstarting ML with SageMaker JumpStart and Autopilot
- Part 3 – The Production and Operation of Machine Learning with SageMaker Studio
- Chapter 9: Training ML Models at Scale in SageMaker Studio
- Chapter 10: Monitoring ML Models in Production with SageMaker Model Monitor
- Chapter 11: Operationalize ML Projects with SageMaker Projects, Pipelines, and Model Registry
- Other Books You May Enjoy
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Getting Started with Amazon SageMaker Studio by Michael Hsieh in PDF and/or ePUB format, as well as other popular books in Computer Science & Computer Science General. We have over 1.5 million books available in our catalogue for you to explore.