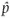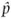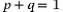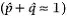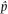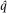This book aims to make population genetics approachable, logical and easily understood. To achieve these goals, the book's design emphasizes well explained introductions to key principles and predictions. These are augmented with case studies as well asillustrations along with introductions to classical hypotheses and debates.
Pedagogical features in the text include:
Interact boxes that guide readers step-by-step through computer simulations using public domain software.
Math boxes that fully explain mathematical derivations.
Methods boxes that give insight into the use of actual genetic data.
Numerous Problem boxes are integrated into the text to reinforce concepts as they are encountered.
Dedicated website at www.wiley.com/go/hamiltongenetics
This text also offers a highly accessible introduction to coalescent theory, the major conceptual advance in population genetics of the last two decades.
Preguntas frecuentes
¿Cómo cancelo mi suscripción?
Simplemente, dirígete a la sección ajustes de la cuenta y haz clic en «Cancelar suscripción». Así de sencillo. Después de cancelar tu suscripción, esta permanecerá activa el tiempo restante que hayas pagado. Obtén más información aquí.
¿Cómo descargo los libros?
Por el momento, todos nuestros libros ePub adaptables a dispositivos móviles se pueden descargar a través de la aplicación. La mayor parte de nuestros PDF también se puede descargar y ya estamos trabajando para que el resto también sea descargable. Obtén más información aquí.
¿En qué se diferencian los planes de precios?
Ambos planes te permiten acceder por completo a la biblioteca y a todas las funciones de Perlego. Las únicas diferencias son el precio y el período de suscripción: con el plan anual ahorrarás en torno a un 30 % en comparación con 12 meses de un plan mensual.
¿Qué es Perlego?
Somos un servicio de suscripción de libros de texto en línea que te permite acceder a toda una biblioteca en línea por menos de lo que cuesta un libro al mes. Con más de un millón de libros sobre más de 1000 categorías, ¡tenemos todo lo que necesitas! Obtén más información aquí.
¿Perlego ofrece la función de texto a voz?
Busca el símbolo de lectura en voz alta en tu próximo libro para ver si puedes escucharlo. La herramienta de lectura en voz alta lee el texto en voz alta por ti, resaltando el texto a medida que se lee. Puedes pausarla, acelerarla y ralentizarla. Obtén más información aquí.
¿Es Population Genetics un PDF/ePUB en línea?
Sí, puedes acceder a Population Genetics de Matthew B. Hamilton en formato PDF o ePUB, así como a otros libros populares de Biowissenschaften y Genetik & Genomik. Tenemos más de un millón de libros disponibles en nuestro catálogo para que explores.
All scientific fields possess a body of concepts that define their domain as well as a specialized vocabulary used to express these concepts precisely. Population genetics is no different and the entirety of this book is designed to introduce, explain, and demonstrate these concepts and their vocabulary. What may be unique about population genetics among the natural sciences is the way that its practitioners approach questions about the biological world. Population genetics is a dialog between predictions based on principles of Mendelian inheritance and results obtained from empirical measurement of genotype and allele frequencies that form the basis of hypothesis tests. Idealized predictions stemming from general principles form the basis of hypotheses that can be tested. At the same time, empirical patterns observed within and among populations require explanation through the comparison of various processes that might have caused a pattern. This first chapter will explore some of the ways in which population genetics approaches and defines problems that are relevant to the topics in all chapters. The chapter is also intended to give some insight into how to approach the study of population genetics.
1.1 Expectations
What do we expect to happen?
Expectations are the basis of understanding cause and effect.
In our everyday lives there are many things that we expect to occur or not to occur based on knowledge of our surroundings and past experience. For example, you probably do not expect to get hit by a meteorite walking to your next population genetics class. Why not? Meteorites do impact the surface of the Earth and on occasion strike something noticeable to people nearby. A few times in the distant past, in fact, large meteors have hit the Earth and left evidence like the Barringer Meteor crater in Arizona, USA. What influences your lack of concern? It is probably a combination of basic knowledge of the principles of physics that apply to meteors as well as your empirical observations of the frequency and location of meteor strikes. Basic physics tells us that a small meteor on a collision course with Earth is unlikely to hit the surface since most objects burn up from the friction they experience traveling through the Earth’s atmosphere. You might also reason that even if the object is big enough to pass through the atmosphere intact, and there are many fewer of these, then the Earth is a large place and just by chance the impact is unlikely to be even remotely near you. Finally, you have most probably never witnessed a large meteorite impact or even heard of one occurring during your lifetime. You have combined your knowledge of the physical world and your experience to arrive (perhaps unconsciously) at a prediction or an expectation: meteorite strikes are possible but are so infrequent that the risk of being struck on the way to class is minuscule. In this very same way, you have constructed models of many events and processes in your physical and social world and used the resulting predictions to make comparisons and decisions.
Expectation The expected value of a random variable, especially the average; a prediction or forecast.
The study of population genetics similarly revolves around constructing and testing expectations for genetic variation in populations of individual organisms. Expectations attempt to predict things like how much genetic variation is present in a population, how genetic variation in a population changes over time, and the pattern of genetic variation that might be left behind by a given biological process that acts over time or through space. Building these expectations involves the use of first principles or the set of very basic rules and assumptions that define how natural systems work at their lowest, most basic levels. A first principle in physics is the force of gravity. In population genetics, first principles are the very basic mechanisms of Mendelian particulate inheritance and processes such as mutation, mating patterns, gene flow, and natural selection that increase, decrease, and shape genetic variation. These foundational rules and processes are used and combined in population genetics with the ultimate goal of building a comprehensive set of predictions that can be applied to any species and any genetic system.
Empirical study in population genetics also plays a central role in constructing and evaluating predictions. In population genetics as in all sciences, empirical evidence is not just from informal experiences, but is drawn from intentional observations, cleverly constructed comparisons, and experiments. Genetic patterns observed in actual populations are compared with expected patterns to test models constructed using general principles and assumptions. For example, we could construct a mathematical or computer simulation model of random genetic drift (change in allele frequency due to sampling from finite populations) based on abstract principles of sampling from a finite population and biological reproduction. We could then compare the predictions of such a model to the observed change in allele frequency through time in a laboratory population of Drosophila melanogaster (fruit flies). If the change in allele frequency in the fruit fly population matched the change in allele frequency predicted using the model of genetic drift, then we could conclude that the model effectively summarizes the biological sampling processes that take place in fruit fly populations.
It is also possible to use well-tested and accepted model expectations as a basis to hypothesize what processes caused an observed pattern in a biological population. Again to use a Drosophila population as an example, we might ask whether an observed change in allele frequency over some generations in a wild population could be explained by genetic drift. If the observed allele frequency change is within the range of the predicted change in allele frequencies based on a model of genetic drift, then we have identified a possible cause of the observed pattern. Comparing expected and observed genetic patterns in populations often requires modifications to existing models or the construction of novel models in order to develop appropriate expectations. For example, a model of genetic drift constructed for Drosophila might naturally assume that all individuals in the population are diploid (individuals possess paired sets of homologous chromosomes). If we wanted to use that same model to predict genetic drift in a population of honey bees, we would have to account for the fact that in honey bee males are haploid (individuals possess single copies of each chromosome) while females are diploid. This change in reproductive biology could be taken into account by altering the assumptions of the model of genetic drift to make the prediction appropriate for honey bee populations. Note that without some modification, a single model of genetic drift would not accurately predict allele frequencies over time in both fruit flies and honey bees since their patterns of reproduction and chromosomal inheritance are different.
Parameters and parameter estimates
While developing the expectations of population genetics in this book, we will most often be working with idealized quantities. For example, allele frequency in a population is a fundamental quantity. For a genetic locus with two alleles, A and a, it is common to say that p equals the frequency of the A allele and q equals the frequency of the a allele. In mathematics, parameter is another term for an idealized quantity like an allele frequency. It is assumed that parameters have an exact value. Put another way, parameters are idealized quantities where the messy, real-life details of how to measure the quantities they represent are completely ignored.
Empirical population genetics measures quantities such as allele frequencies to give parameter estimates by sampling and then measuring the alleles and genotypes present in actual populations. All experiments, observations, and even simulations in population genetics produce parameter estimates of some sort. There is a subtle notational convention used to indicate an estimate, the hat or ˆ character above a variable. Estimates wear hats whereas parameters do not. Using allele frequency as an example, we would say
(pronounced “p hat”) equals the number of A alleles sampled divided by the total number of alleles sampled. Intuitively, we can see from the denominator in the expression for
that the allele frequency estimate will depend on the sample we gather to make the estimate.
In all populations a parameter has one true value. For the allele frequency p, knowing this true value would require examining the genotype of every individual and counting all A and a alleles to determine their frequency in the population. This task is impractical or impossible in most cases. Instead, we rely on an estimate of allele frequency,
, obtained from a sample of individuals from the population. Sampling leads to some uncertainty in parameter estimates because repeating the sampling and parameter estimate process would likely lead to a somewhat different parameter estimate each time. Quantifying this uncertainty is important to determine whether repeated sampling might change a parameter estimate by just a little or change it by a lot. When dealing with parameters, we might expect that
exactly if there are only two alleles with allele frequencies p and q. However, if we are dealing with estimates we might say the two allele frequency estimates should sum to approximately one
since each allele frequency is estimated with some error. The more uncertain the estimates of
and
, the less we should be surprised to find that their sum does not equal the expected value of one.
Parameter A variable or constant appearing in a mathematical expression; a value (usually unknown) used to represent a certain population characteristic; any factor that defines a system and determines or limits its performance.
Estimate An indication of the value of an unknown quantity based on observed data; an approximation of a true score, parameter, or value; a statistical estimate of the value of a parameter.
It could be said that statistics sits at the intersection of theoretical and empirical population genetics. Parameters and parameter estimates are fundamentally different things. Estimation requires effort to understand sampling variation and quantify sources of error and bias in samples and estimates. The distinction between parameters and estimates is critical when comparing actual populations with expectations to test hypotheses. When large, random samples can be taken, estimates are likely to have minimal error. However, there are many cases where estimates have a great deal of uncertainty, which limits the ability to evaluate expectations. There are also instances where very different processes may produce very similar expected results. In such cases it may be difficult or impossible to distinguish the different potential causes of a pattern due to the approximate nature of estimates. While this book focuses mostly on parameters, it is useful to bear in mind that testing or comparing expectations requires the use of parameter estimates and statistics that quantify sampling error. The Appendix provides a review of some basic statistics that are used in the text.
Inductive and deductive reasoning
Population genetics employs both inductive and deductive reasoning in an effort to understand the biological processes operating in actual populations as well as to elucidate the general processes that cause population genetic phenomena. The inductive approach to population genetics involves assembling measures of genetic variation (parameter estimates) from various populations to build up evidence that can be used to identify the underlying processes that produced the observed patterns. This approach is logically identical to that used by Isaac Newton, who used knowledge of how objects fall to the surface of the Earth as well as knowledge of the movement of planets to arrive at the general principles of gravity. Application of inductive reasoning requires detailed familiarity with the various empirical data types in population genetics, such as DNA sequences, along with the results of studies that report observed patterns of genetic variation. From this accumulated empirical information it is then possible to draw more general conclusions about the qualities and quantities of genetic variation in populations. Model organisms like D. melanogaster and Arabidopsis thaliana play a large role in population genetic conclusions reached by inductive reasoning. Because model organisms receive a large amount of scientific effort, to completely sequence their genomes for example, a great deal of available genetic data are accumulated for these species. Based on this evidence, many firm conclusions have been made about the population genetics of particular model species. Although model organisms provide very rich sources of empirical information, the number of species is limited by definition so that any generalizations may not apply universally to all species.
Deductive reasoning Using general principles to reach conclusions about specific instances.
Inductive reasoning Utilizing the knowledge of specific instances or cases to arrive at general principles.
The study of population genetics can also be approached using deductive reasoning. The actions of general processes such as genetic drift, mutation, and natural selection are represented by parameters in the mathematical equations that make up population genetic models. These models can then be used to make predictions about the quantity of genetic variation and patterns of genetic variation in space and time. Such population genetic models make general predictions about things like rates of change in allele frequency, the eventual equilibrium of allele or genotype frequencies, and the net outcome of several processes operating at the same time. These predictions are very general in that they apply to any population of any species since the predictions arose from general principles in the first place. At the same time, such general predictions may not be directly applicable to a specific population because the general principles and assumptions used to make the prediction are not specific enough to match an actual population.
Historically, the field of population genetics has developed from an interplay between arguments and evidence developed using both inductive and deductive reasoning approaches. Nonetheless, most of the major ideas in population genetics can be first approached with deductive reasoning by learning and understanding the expectations that arise from the principles of Mendelian heredity. This book stresses the process of deductive reasoning to arrive at these fundamental predictions. Empirical evidence related to expectations is included to illustrate predictions and also to demonstrate hypothesis tests that result from expectations. Because the body of empirical results in population genetics is very large, readers should resist the temptation to generalize too much from the limited number of empirical studies that are presented. Detailed reviews of particular areas of population genetics, many of which are cited in the Further reading sections at the end of each chapter, are a better source for comprehensive summaries of empirical studies.
In the next chapter we will start by building expectations for the frequencies of diploid genotypes based on the foundation of particulate inheritance: that alleles are passed unaltered from parents to offspring. There is ample support for particulate inheritance both from molecular biology, which identifies DNA as the hereditary molecule, and from allele and genotype frequencies that can be observed in actual populations. The general principle of particulate inheritance has been used to formulate a wide array of expectations about allele and genotype frequencies in populations.
1.2 Theory and assumptions
What is a theory and what are assumptions?
How can theories be useful with so many assumptions?
In colloquial usage, the word theory refers to something that is known with uncertainty, or a quantity that is approximate. On a day you are running late leaving work you might say, “In theory, I am supposed to be home at 6:00 pm.” In science, theory has a very different meaning. Theory is the accumulation of expectations and observations that have withstood tests and critical scrutiny and are accepted by at least some practitioners of a scientific field. Theory is the collection of all of the expectations developed for specific cases or individual biological processes that together form a more comprehensive set of general principles. The combination of Darwin’s hypothesis of natural selection with the laws of Mendelian particulate inheritance is often called the modern synthesis of evolutionary biology since it is a comprehensive theory to explain the causes of evolutionary change. The modern synthesis can offer causal explanations for biological phenomena ranging from antibiotic resistance in bacteria to the behavior of elephants to the rate of DNA sequence change as well as make predictions to guide animal and plant breeders. In all of the modern synthesis, population genetics plays a central role.
It is common for the uninitiated to ask the question “what good is theory if it is based on so many assumptions?” A body of theory is a useful tool to articulate assumptions and generate testable predictions. Theory that generates many testable predictions about the world also offers many opportunities to falsify its predictions and assumptions. Since hypotheses cannot be proven directly, but alternative hypotheses can be disproven, the generation of plausible, testable alternative hypotheses is a requirement for scientific inquiry. Strong theories are able to make accurate predictions, offer causal explanations for diverse observations, and generate alternative hypotheses based on revised assumptions.
The words theory and assumption can seem abstract, but you should not be intimidated by them. Theories are just collections of expectations, each with a set of assumptions that place bounds on the prediction being made. If you understand what motivates an expectation, its predictions, and its assumptions, then you understand theory. Most expectations in population genetics will have at least a few, and often many, assumptions used to define and bound the situation. For example, we might assume something about the size of a population or the absence of mutation, or that all genotypes are diploid with two alleles. This is a way of limiting the prediction to appropriate circumstances and also a way of defining which quantities and conditions can vary and which are fixed. Each of these assumptions can influence the generality of an expectation. Each assumption can also be relaxed or altered to see how strongly it influences the expectation. To return to the example in the last section, if one day meteorites were falling around us with regularity we would be forced to call into question some of the basic assumptions originally used to formulate our expectation that meteorite strikes should be rare events. In this way, assumptions are useful tools to ask “what if … ?” as part of the process of developing a prediction. If our initial “what if … ?” conditions are badly off the mark, then the resulting prediction will probably also be poor.
In population genetics, as in much of science where theory and expectations are involved, empirical data and model expectations are routinely compared. Imagine observing a set of genotype frequencies in a biological popul...