Learn AWS Serverless Computing
A beginner's guide to using AWS Lambda, Amazon API Gateway, and services from Amazon Web Services
Scott Patterson
- 382 páginas
- English
- ePUB (apto para móviles)
- Disponible en iOS y Android
Learn AWS Serverless Computing
A beginner's guide to using AWS Lambda, Amazon API Gateway, and services from Amazon Web Services
Scott Patterson
Información del libro
Build, deploy, test, and run cloud-native serverless applications using AWS Lambda and other popular AWS services
Key Features
- Learn how to write, run, and deploy serverless applications in Amazon Web Services
- Make the most of AWS Lambda functions to build scalable and cost-efficient systems
- Build and deploy serverless applications with Amazon API Gateway and AWS Lambda functions
Book Description
Serverless computing is a way to run your code without having to provision or manage servers. Amazon Web Services provides serverless services that you can use to build and deploy cloud-native applications. Starting with the basics of AWS Lambda, this book takes you through combining Lambda with other services from AWS, such as Amazon API Gateway, Amazon DynamoDB, and Amazon Step Functions.
You'll learn how to write, run, and test Lambda functions using examples in Node.js, Java, Python, and C# before you move on to developing and deploying serverless APIs efficiently using the Serverless Framework. In the concluding chapters, you'll discover tips and best practices for leveraging Serverless Framework to increase your development productivity.
By the end of this book, you'll have become well-versed in building, securing, and running serverless applications using Amazon API Gateway and AWS Lambda without having to manage any servers.
What you will learn
- Understand the core concepts of serverless computing in AWS
- Create your own AWS Lambda functions and build serverless APIs using Amazon API Gateway
- Explore best practices for developing serverless applications at scale using Serverless Framework
- Discover the DevOps patterns in a modern CI/CD pipeline with AWS CodePipeline
- Build serverless data processing jobs to extract, transform, and load data
- Enforce resource tagging policies with continuous compliance and AWS Config
- Create chatbots with natural language understanding to perform automated tasks
Who this book is for
This AWS book is for cloud architects and developers who want to build and deploy serverless applications using AWS Lambda. A basic understanding of AWS is required to get the most out of this book.
Preguntas frecuentes
Información
Section 1: Why We're Here
- Chapter 1, The Evolution of Compute
- Chapter 2, Event-Driven Applications
The Evolution of Compute
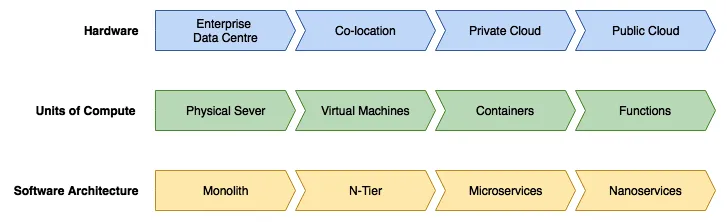
- Understanding enterprise data centers
- Exploring the units of compute
- Understanding software architectures
- Predicting what comes next
Understanding enterprise data centers
- The physical data center
- Colocating our gear
- Cloud born
The physical data center
Colocating our gear
Cloud born
Exploring the units of compute
- Physical servers: Scale at the physical server layer
- Virtual machines: Density efficiencies achieved by virtualizing the hardware
- Containers: Better density with faster start times
- Functions: Best density by abstracting the runtime
Physical servers – scale at the physical server layer
- Securing a capital expenditure budget from finance or the Project Management Office (PMO)
- Procuring hardware from a vendor
- Capacity planning to confirm that there is space for the new hardware
- Updates to the colocation agreement with the hosting provider
- Scheduling engineers to travel to the site
- Licensing considerations for new software being installed
Virtual machines – density efficiencies achieved by virtualizing the hardware