
eBook - ePub
Logical Database Design Principles
John Garmany, Jeff Walker, Terry Clark
This is a test
Compartir libro
- 200 páginas
- English
- ePUB (apto para móviles)
- Disponible en iOS y Android
eBook - ePub
Logical Database Design Principles
John Garmany, Jeff Walker, Terry Clark
Detalles del libro
Vista previa del libro
Índice
Citas
Información del libro
Until now, almost all books on logical database design focused exclusively on relational design. However, modern database management systems have added powerful features that have driven a movement away from truly normalized database design. Logical Database Design Principles reflects these recent changes. The book begins by covering traditional lo
Preguntas frecuentes
¿Cómo cancelo mi suscripción?
¿Cómo descargo los libros?
Por el momento, todos nuestros libros ePub adaptables a dispositivos móviles se pueden descargar a través de la aplicación. La mayor parte de nuestros PDF también se puede descargar y ya estamos trabajando para que el resto también sea descargable. Obtén más información aquí.
¿En qué se diferencian los planes de precios?
Ambos planes te permiten acceder por completo a la biblioteca y a todas las funciones de Perlego. Las únicas diferencias son el precio y el período de suscripción: con el plan anual ahorrarás en torno a un 30 % en comparación con 12 meses de un plan mensual.
¿Qué es Perlego?
Somos un servicio de suscripción de libros de texto en línea que te permite acceder a toda una biblioteca en línea por menos de lo que cuesta un libro al mes. Con más de un millón de libros sobre más de 1000 categorías, ¡tenemos todo lo que necesitas! Obtén más información aquí.
¿Perlego ofrece la función de texto a voz?
Busca el símbolo de lectura en voz alta en tu próximo libro para ver si puedes escucharlo. La herramienta de lectura en voz alta lee el texto en voz alta por ti, resaltando el texto a medida que se lee. Puedes pausarla, acelerarla y ralentizarla. Obtén más información aquí.
¿Es Logical Database Design Principles un PDF/ePUB en línea?
Sí, puedes acceder a Logical Database Design Principles de John Garmany, Jeff Walker, Terry Clark en formato PDF o ePUB, así como a otros libros populares de Informatique y Bases de données. Tenemos más de un millón de libros disponibles en nuestro catálogo para que explores.
Información
1
INTRODUCTION TO LOGICAL DATABASE DESIGN
The goal in this chapter is to define logical databases, identify the elements and structures of logical design, and describe the steps used to create that design. It sounds simple enough, but it is a lofty goal that requires more than memorizing a definition and learning the elements of logical database design. Success depends on the application of critical thinking as well as analytical and interpersonal skills.
UNDERSTANDING A DATABASE
Before starting the process of designing a logical database, we need to understand what a database is and what some of the design approaches are that distinguish one database type from another. The simplest definition of a database is a collection of data items stored for later retrieval. Notice that there is no mention of computers or database management systems. That is because databases have been around much longer than both computers and database management systems. When the first caveman etched charcoal on the cave to track the passage of time, the first database was born. In this example, the data was stored as marks on the wall and the data retrieved by looking at the wall. As technology evolved, the marks moved from the wall to a notebook, then to a filing cabinet, and later to data files in a directory on a computer. Once computers made the scene, we discovered different approaches to optimize and manage the database.
DATABASE ARCHITECTURES
Prior to 1969, common database architectures were based on hierarchical and network systems. We review these approaches to establish a point of comparison to better understand relational databases. The discussion is a brief one because, for all intents and purposes, these approaches are considered obsolete. This does not mean you will not find them in use, because legacy systems used by companies with high transaction rates and where data resides on mainframes still exist. Just understand that most new database systems are designed for a relational or object-relational database.
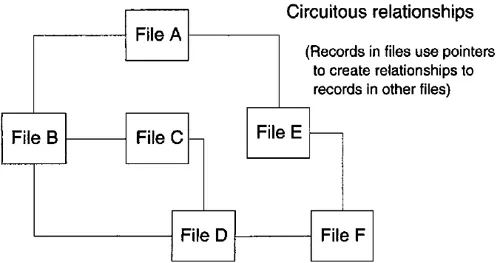
Figure 1.1 Network database model.
A network database system as depicted in Figure 1.1 organizes files in a manner that associates each file with n number of other files. This approach uses pointers to create a relationship between records in one file and records in another file. The network approach provides more flexibility than the hierarchical approach and allows a database designer to optimize the database using detailed control and data organization. Record types can be organized using hashing algorithms or are located near another related record type (an early form of clustering). Do not worry about these advanced terms now; they are discussed in subsequent chapters. The drawback to the network approach involves performance and overhead. Overhead is the storage and code maintenance of the database that is required to implement the relationships. Additional drawbacks include the need for significant programming skills, database design knowledge, time, plus topic-specific expertise.
Notice in Figure 1.1 that the network database model creates circuitous relationships. Each box in the diagram represents a file. The redundancy is obvious, in that each file is related to multiple files. This occurs because records in one file use pointers to records in another file.
A hierarchical database system as depicted in Figure 1.2 organizes files in a top-down, branching tree architecture similar to a company’s organization model. This approach associates files in a parent/child relationship. By its nature, this architecture is limited to associations derived from the top or root file and flowed down the branches. This approach has limited flexibility, as each relationship depends on the file above it. A parent record can have multiple child records, but each child record can have only one parent. The relationships are based on address pointers.
So what are some of the characteristics of both the hierarchical and network database approaches?:
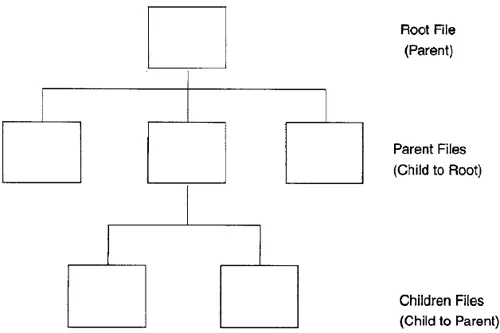
Figure 1.2 Hierarchical database model.
- They use pointers.
- Their architecture uses redundancy to create relationships and optimization.
- They evolved over time, almost on a trial and error basis.
- Models were developed after the fact to explain and improve them, but not as part of the original design and theory.
The fact that hierarchical and network models were developed after those databases were implemented is significant. It underscores the contributions made by Dr. Edgar F.Codd, considered by most as the “father of the relational database.” When he published his “Derivability, Redundancy and Consistency of Relations Stored in Large Data Banks” as an IBM Research Report in 1969, he introduced science into database management. He was the first to offer a theoretical explanation or model of data.
RELATIONAL DATABASES
OK, so what is a relational database? As depicted in Figure 1.3, it is a data model in which the data is stored in tables (also referred to as entities). Each table has rows (also referred to as records or tuples) and columns (also referred to as attributes). Each row in a table has a unique identifier (UID), which is referred to as a primary key (PK). Cross-reference links between tables can be defined by creating a FOREIGN KEY (FK) in one table that references a primary key in another table. When defined in this manner, the link or relationship provides referential integrity. That is, data must exist in the referenced table before it can be placed in the referencing table. This aspect is further discussed in subsequent chapters.
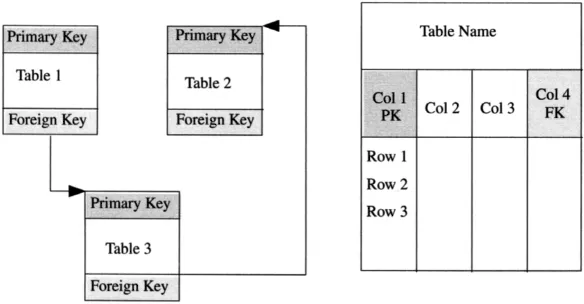
Figure 1.3 Relational database.
What really distinguishes a relational database from the network and hierarchical databases is that relationships are defined using the UID of one table and joining them with the UID of another table. Pointers are not used. Data redundancy is reduced via a process called normalization.
Finally, data can be accessed using Structured Query Language (SQL). Using a relational database, we can update our database definition. A database is a shared collection of logically related data items needed by an enterprise and stored on a server or distributed over several computers where data can be retrieved based on user needs.
CREATING THE DATABASE
Now knowing the database types, we could seclude ourselves in an office and create a relational database using SQL to build the tables and relationships between them. Unfortunately, this approach will result in poor performance, inefficiencies, and a database that does not meet the needs of the organization. What is needed is a methodology to discover the organization’s requirements, define a specification, design a database, implement that database design, and, finally, maintain that database. Fortunately, there is a methodology; it is known as the System Development Life Cycle (SDLC).
SYSTEM DEVELOPMENT LIFE CYCLE (SDLC)
Designing a database requires an understanding of the Systems Development Life Cycle (SDLC), which is comprised of several phases: systems planning, systems analysis, systems design, systems implementation, and systems operations and support. The planning phase would be conducted by a systems analyst. It would include an investigation of the existing systems in the enterprise to determine how well the operations are performing as well as a feasibility study to assess the economic impact of the project and time constraints. If the planning phase returns a positive recommendation, the systems analysis phase would begin. In this phase, a systems analyst would identify business processes that must be done in the new system. Findings would be documented and logical models developed for the enterprise, data, processes, and objects. The end product would be a complete requirements document for the new system, along with costs, schedules, and benefits. The systems design phase would then translate the requirements into a specification that identified all required inputs, outputs, processes, and controls. The systems implementation phase would be next, and the specification identified in the design phase would be built. Developers write the programs and scripts and document the system. Trainers train users and DBAs (database administrators) implement the system in a production schema. Finally, in the systems operation and support phase, the IT department would maintain the system and provide fixes and enhancements as they are identified.
SYSTEMS PLANNING: ASSESSMENT AND FEASIBILITY
The phases of the SDLC can be better understood by focusing on the elements that are directly involved in the development of a logical database.
For our purposes, assume that the systems planning phase has ended and the systems analyst has recommended that we proceed with the project to design a new database system. Further assume that a feasibility study has been completed and management has approved the creation of a new database. Inherent in management’s approval is a schedule, identification of available resources, and description of the work scope.
The approval is important because it defines what work is to be done, when that work is to be completed, and what resources will be used. The work scope will become the basis for “selling off’ the database. That means documenting and demonstrating that the finished product does what is described in the scope of work. Without such a document, work could continue forever as enhancements and changes are folded into the project without assessing the impact and receiving management’s approval.

Figure 1.4 System development life cycle (SDLC).
The SDLC phase that truly begins the logical database design is system analysis: the collection and analysis of data and processes an organization uses to conduct its business. This phase uses critical thinking, analytical, and interpersonal skills to identify the data and processes into a meaningful requirements document.
Figure 1.4 graphically illustrates the elements of the SDLC (with corresponding skill sets) needed to create a logical database. The methodology steps through the process, emphasizing data collection and the resulting requirements checklist, analysis and modeling of the logical design, documentation of the requirements into a specification, prototyping a database, and production with its maintenance and enhancements. An important element of the SDLC is feedback and ongoing validation or testing. Take a look at the SDLC as it applies to logical database design.
SYSTEM ANALYSIS: REQUIREMENTS
The analysis and collection phase begins with identifying the requirements. This task uses communication techniques and interpersonal skills that will uncover an enterprise’s processes and data needs. What makes this task so difficult is that requirements must be ferreted out. A designer cannot just automate whatever policy and procedures have been documented. Formal policies and procedures tend to obscure an organization’s actual or informal processes. Furthermore, there is a tendency for an organization to continue working a particular way because that is the way that particular organization has been doing it for many years. Using investigative techniques, interviews, and questionnaires, a designer or analyst will identify management, user, and process requirements. The investigation may follow the SDLC or utilize newer techniques such as Joint Application Design (JAD).
JAD is similar to an SDLC group interview for data collection. It differs because the SDLC group interview is primarily a homogeneous group (e.g., the accounting department). JAD requires all key personnel representing all disciplines, including system types, and they meet at an offsite location. Their goal is to shorten the process by gathering more data quickly and utilizing CASE tools to structure their effort. Another, more radical approach is referred to as business process reengineering (BPR). This approach recognizes that some organizations may require more than tweaking or enhan...