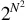Computer Vision: Principles, Algorithms, Applications, Learning (previously entitled Computer and Machine Vision) clearly and systematically presents the basic methodology of computer vision, covering the essential elements of the theory while emphasizing algorithmic and practical design constraints. This fully revised fifth edition has brought in more of the concepts and applications of computer vision, making it a very comprehensive and up-to-date text suitable for undergraduate and graduate students, researchers and R&D engineers working in this vibrant subject.
See an interview with the author explaining his approach to teaching and learning computer vision - http://scitechconnect.elsevier.com/computer-vision/
Three new chapters on Machine Learning emphasise the way the subject has been developing; Two chapters cover Basic Classification Concepts and Probabilistic Models; and the The third covers the principles of Deep Learning Networks and shows their impact on computer vision, reflected in a new chapter Face Detection and Recognition.
A new chapter on Object Segmentation and Shape Models reflects the methodology of machine learning and gives practical demonstrations of its application.
In-depth discussions have been included on geometric transformations, the EM algorithm, boosting, semantic segmentation, face frontalisation, RNNs and other key topics.
Examples and applications—including the location of biscuits, foreign bodies, faces, eyes, road lanes, surveillance, vehicles and pedestrians—give the 'ins and outs' of developing real-world vision systems, showing the realities of practical implementation.
Necessary mathematics and essential theory are made approachable by careful explanations and well-illustrated examples.
The 'recent developments' sections included in each chapter aim to bring students and practitioners up to date with this fast-moving subject.
Tailored programming examples—code, methods, illustrations, tasks, hints and solutions (mainly involving MATLAB and C++)
Preguntas frecuentes
¿Cómo cancelo mi suscripción?
Simplemente, dirígete a la sección ajustes de la cuenta y haz clic en «Cancelar suscripción». Así de sencillo. Después de cancelar tu suscripción, esta permanecerá activa el tiempo restante que hayas pagado. Obtén más información aquí.
¿Cómo descargo los libros?
Por el momento, todos nuestros libros ePub adaptables a dispositivos móviles se pueden descargar a través de la aplicación. La mayor parte de nuestros PDF también se puede descargar y ya estamos trabajando para que el resto también sea descargable. Obtén más información aquí.
¿En qué se diferencian los planes de precios?
Ambos planes te permiten acceder por completo a la biblioteca y a todas las funciones de Perlego. Las únicas diferencias son el precio y el período de suscripción: con el plan anual ahorrarás en torno a un 30 % en comparación con 12 meses de un plan mensual.
¿Qué es Perlego?
Somos un servicio de suscripción de libros de texto en línea que te permite acceder a toda una biblioteca en línea por menos de lo que cuesta un libro al mes. Con más de un millón de libros sobre más de 1000 categorías, ¡tenemos todo lo que necesitas! Obtén más información aquí.
¿Perlego ofrece la función de texto a voz?
Busca el símbolo de lectura en voz alta en tu próximo libro para ver si puedes escucharlo. La herramienta de lectura en voz alta lee el texto en voz alta por ti, resaltando el texto a medida que se lee. Puedes pausarla, acelerarla y ralentizarla. Obtén más información aquí.
¿Es Computer Vision un PDF/ePUB en línea?
Sí, puedes acceder a Computer Vision de E. R. Davies en formato PDF o ePUB, así como a otros libros populares de Informatik y Digitale Medien. Tenemos más de un millón de libros disponibles en nuestro catálogo para que explores.
This chapter introduces the subject of computer vision. It shows how recognition may be performed partly by image processing, although abstract pattern recognition methods are usually needed to complete the task. Important in this process is normalization of the image content to reduce variability so that statistical pattern recognizers such as the nearest neighbor algorithm can carry out their task with limited training requirements and low error rates. It extends the discussion by introducing machine learning and the recently prominent deep learning networks. This chapter also discusses the various applications of vision, contrasting automated visual inspection, and surveillance.
Keywords
Computer vision; process of recognition; nearest neighbor algorithm; template matching; image preprocessing; need for normalization; machine learning; deep learning networks; automated visual inspection; surveillance
1.1 Introduction—Man and His Senses
Of the five senses—vision, hearing, smell, taste, and touch—vision is undoubtedly the one that man has come to depend upon above all others, and indeed the one that provides most of the data he receives. Not only do the input pathways from the eyes provide megabits of information at each glance but also the data rates for continuous viewing probably exceed 10 Mbps. However, much of this information is redundant and is compressed by the various layers of the visual cortex, so that the higher centers of the brain have to interpret abstractly only a small fraction of the data. Nonetheless, the amount of information the higher centers receive from the eyes must be at least two orders of magnitude greater than all the information they obtain from the other senses.
Another feature of the human visual system is the ease with which interpretation is carried out. We see a scene as it is—trees in a landscape, books on a desk, widgets in a factory. No obvious deductions are needed and no overt effort is required to interpret each scene; in addition, answers are effectively immediate and are normally available within a tenth of a second. Just now and again some doubt arises—e.g., a wire cube might be “seen” correctly or inside out. This and a host of other optical illusions are well known, although for the most part we can regard them as curiosities—irrelevant freaks of nature. Somewhat surprisingly, illusions are quite important, since they reflect hidden assumptions that the brain is making in its struggle with the huge amounts of complex visual data it is receiving. We have to pass by this story here (although it resurfaces now and again in various parts of this book). However, the important point is that we are for the most part unaware of the complexities of vision. Seeing is not a simple process: it is just that vision has evolved over millions of years, and there was no particular advantage in evolution giving us any indication of the difficulties of the task (if anything, to have done so would have cluttered our minds with irrelevant information and slowed our reaction times).
In the present-day and age, man is trying to get machines to do much of his work for him. For simple mechanistic tasks this is not particularly difficult, but for more complex tasks the machine must be given the sense of vision. Efforts have been made to achieve this, sometimes in modest ways, for well over 40 years. At first, schemes were devised for reading, for interpreting chromosome images, and so on; but when such schemes were confronted with rigorous practical tests, the problems often turned out to be more difficult. Generally, researchers react to finding that apparent “trivia” are getting in the way by intensifying their efforts and applying great ingenuity, and this was certainly so with early efforts at vision algorithm design. However, it soon became plain that the task really is a complex one, in which numerous fundamental problems confront the researcher, and the ease with which the eye can interpret scenes turned out to be highly deceptive.
Of course, one of the ways in which the human visual system gains over the machine is that the brain possesses more than 1010 cells (or neurons), some of which have well over 10,000 contacts (or synapses) with other neurons. If each neuron acts as a type of microprocessor, then we have an immense computer in which all the processing elements can operate concurrently. Taking the largest single man-made computer to contain several hundred million rather modest processing elements, the majority of the visual and mental processing tasks that the eye–brain system can perform in a flash have no chance of being performed by present-day man-made systems. Added to these problems of scale, there is the problem of how to organize such a large processing system and also how to program it. Clearly, the eye–brain system is partly hard-wired by evolution but there is also an interesting capability to program it dynamically by training during active use. This need for a large parallel processing system with the attendant complex control problems shows that computer vision must indeed be one of the most difficult intellectual problems to tackle.
So what are the problems involved in vision that make it apparently so easy for the eye, yet so difficult for the machine? In the next few sections an attempt is made to answer this question.
1.2 The Nature of Vision
1.2.1 The Process of Recognition
This section illustrates the intrinsic difficulties of implementing computer vision, starting with an extremely simple example—that of character recognition. Consider the set of patterns shown in Fig. 1.1A. Each pattern can be considered as a set of 25 bits of information, together with an associated class indicating its interpretation. In each case imagine a computer learning the patterns and their classes by rote. Then any new pattern may be classified (or “recognized”) by comparing it with this previously learnt “training set,” and assigning it to the class of the nearest pattern in the training set. Clearly, test pattern (1) (Fig. 1.1B) will be allotted to class U on this basis. Chapter 13, Basic Classification Concepts, shows that this method is a simple form of the nearest neighbor approach to pattern recognition.
Figure 1.1 Some simple 25-bit patterns and their recognition classes used to illustrate some of the basic problems of recognition: (A) training set patterns (for which the known classes are indicated); (B) test patterns.
The scheme outlined above seems straightforward and is indeed highly effective, even being able to cope with situations where distortions of the test patterns occur or where noise is present: this is illustrated by test patterns (2) and (3). However, this approach is not always foolproof. First, there are situations where distortions or noise is excessive, so errors of interpretation arise. Second, there are situations where patterns are not badly distorted or subject to obvious noise, yet are misinterpreted: this seems much more serious, since it indicates an unexpected limitation of the technique rather than a reasonable result of noise or distortion. In particular, these problems arise where the test pattern is displaced or misorientated relative to the appropriate training set pattern, as with test pattern (6).
As will be seen in Chapter 13, Basic Classification Concepts, there is a powerful principle that indicates why the unlikely limitation given above can arise: it is simply that there are insufficient training set patterns, and that those that are present are insufficiently representative of what will arise in practical situations. Unfortunately, this presents a major difficulty, since providing enough training set patterns incurs a serious storage problem and an even more serious search problem when patterns are tested. Furthermore, it is easy to see that these problems are exacerbated as patterns become larger and more real (obviously, the examples of Fig. 1.1 are far from having enough resolution even to display normal type-fonts). In fact, a “combinatorial explosion” takes place: this is normally taken to mean that one or more parameters produce fast-varying (often exponential) effects, which “explode” as the parameters increase by modest amounts. Forgetting for the moment that the patterns of Fig. 1.1 have familiar shapes, let us temporarily regard them as random bit patterns. Now the number of bits in these N×N patterns is N2, and the number of possible patterns of this size is
: even in a case where N=20, remembering all these patterns and their interpretations would be impossible on any practical machine, and searching systematically through them would take impracticably long (involving times of the order of the age of the universe). Thus it is not only impracticable to consider such brute force means of solving the recognition problem, but is also effectively impossible theoretically. These considerations show that other means are required to tackle the problem.
1.2.2 Tackling the Recognition Problem
An obvious means of tackling the recognition problem is to standardize the images in some way. Clearly, normalizing the position and orientation of any 2D picture object would help considerably: indeed this would reduce the number of degrees of freedom by three. Methods for achieving this involve centralizing the objects—arranging that their centroids are at the center of the normalized image—and making their major axes (e.g., deduced by moment calculations) vertical or horizontal. Next, we can make use of the order that is known to be present in the image—and here it may be noted that very few patterns of real interest are indistinguishable from random dot patterns. This approach can be taken further: if patterns are to be nonrandom, isolated noise points may be eliminated. Ultimately, all these methods help by making the test pattern closer to a restricted set of training set patterns (although care must also be taken to process the training set patterns initially so that they are representative of the processed test patterns).
It is useful to consider character recognition further. Here we can make additional use of what is known about the structure of characters—namely, that they consist of limbs of roughly constant width. In that case the width carries no useful information, so the patterns can be thinned to stick figures (called skeletons—see Chapter 8: Binary Shape Analysis); then, hopefully, there is an even greater chance that the test patterns will be similar to appropriate training set patterns (Fig. 1.2). This process can be regarded as another instance of reducing the number of degrees of freedom in the image, and hence of helping to minimize the combinatorial explosion—or, from a practical point of view, to minimize the size of the training set necessary for effective recognition.
Figure 1.2 Use of thinning to regularize character shapes. Here character shapes of different limb widths—or even varying limb widths—are reduced to stick figures or skeletons. Thus irrelevant information is removed and at the same time recognition is facilitated.
Next, consider a rather different way of looking at the problem. Recognition is necessarily a problem of discrimination—i.e., of discriminating between patterns of different classes. However, in practice, considering the natural variation of patterns, including the effects of noise and distortions (or even the effects of breakages or occlusions), there is also a problem of generalizing over patterns of the same class. In practical problems there is a tension between the need to discriminate and the need to generalize. Nor is this a fixed situation. Even for the character recognition task, some classes are so close to others (n’s and h’s will be similar) that less generalization is possible than in other cases. On the other hand, extreme forms of generalization arise when, for example, an A is to be recognized as an A whether it is a capital or small letter, or in italic, bold, suffix, or other form of font—even if it is handwritten. The variability is determined largely by the training set initially provided. What we emphasize here, however, is that generalization is as necessary a prerequisite to successful recognition as is discrimination.
At this point it is worth considering more carefully the means whereby generalization was achieved in the examples cited above. First, objects were positioned and orientated appropriately; second, they were cleaned of noise spots; and third, they were thinned to skeleton figures (although the latter process is relevant only for certain tasks such as character recognition). In the last case, we are generalizing over characters ...