![]()
Chapter 1
Software Process for Multiphysics Multicomponent Codes
Anshu Dubey, Katie Antypas, Ethan Coon, and Katherine Riley
1.1 Introduction
1.2 Lifecycle
1.2.1 Development Cycle
1.2.2 Verification and Validation
1.2.3 Maintenance and Extensions
1.2.4 Performance Portability
1.2.5 Using Scientific Software
Key Insights
1.3 Domain Challenges
Key Insights
1.4 Institutional and Cultural Challenges
Key Insights
1.5 Case Studies
1.5.1 FLASH
1.5.1.1 Code Design
1.5.1.2 Verification and Validation
1.5.1.3 Software Process
1.5.1.4 Policies
1.5.2 Amanzi/ATS
1.5.2.1 Multiphysics Management through Arcos
1.5.2.2 Code Reuse and Extensibility
1.5.2.3 Testing
1.5.2.4 Performance Portability
Key Insights
1.6 Generalization
Key Insights
1.7 Additional Future Considerations
Acknowledgments
1.1 Introduction
Computational science and engineering communities develop complex applications to solve scientific and engineering challenges, but these communities have a mixed record of using software engineering best practices [43,296]. Many codes developed by scientific communities adopt standard software practices when the size and complexity of an application become too unwieldy to continue without them [30]. The driving force behind adoption is usually the realization that without using software engineering practices, the development, verification, and maintenance of applications can become intractable. As more codes cross the threshold into increasing complexity, software engineering processes are being adopted from practices derived outside the scientific and engineering domain. Yet the state of the art for software engineering practices in scientific codes often lags behind that in the commercial software space [16, 36, 52]. There are many reasons: lack of incentives, support, and funding; a reward system favoring scientific results over software development; limited understanding of how software engineering should be promoted to communities that have their own specific needs and sociology [22, 35].
Some software engineering practices have been better accepted than others among the developers of scientific codes. The ones that are used often include repositories for code version control, licensing process, regular testing, documentation, release and distribution policies, and contribution policies [21, 22, 30, 32]. Less accepted practices include code review, code deprecation, and adoption of specific practices from development methodologies such as Agile [9]. Software best practices that may be effective in commercial software development environments are not always suited for scientific environments, partly because of sociology and partly because of technical challenges. Sociology manifests itself as suspicion of too rigid a process or not seeing the point of adopting a practice. The technical challenges arise from the nature of problems being addressed by these codes. For example, multiphysics and multicomponent codes that run on large high-performance computing (HPC) platforms put a large premium on performance. In our experience, good performance is most often achieved by sacrificing some of the modularity in software architecture (e.g. [28]). Similarly lateral interactions in physics get in the way of encapsulations (see Sections 1.3 and 1.4 for more examples and details).
This chapter elaborates on the challenges and how they were addressed in FLASH [26, 33] and Amanzi [41], two codes with very different development timeframe, and therefore very different development paths. FLASH, whose development began in the late 1990s, is among the first generation of codes that adopted a software process. This was in the era when the advantages of software engineering were almost unknown in the scientific world. Amanzi is from the “enlightened” era (by scientific software standards) where a minimal set of software practices are adopted by most code projects intending long term use. A study of software engineering of these codes from different eras of scientific software development highlight how these practices and the communities have evolved.
FLASH was originally designed for computational astrophysics. It has been almost continuously under production and development since 2000, with three major revisions. It has exploited an extensible framework to expand its reach and is now a community code for over half a dozen scientific communities. The adoption of software engineering practices has grown with each version change and expansion of capabilities. The adopted practices themselves have evolved to meet the needs of the developers at different stages of development. Amanzi, on the other hand, started in 2012 and has developed from the ground up in C++ using relatively modern software engineering practices. It still has one major target community but is also designed with extensibility as an objective. Many other similarities and some differences are described later in the chapter. In particular, we address the issues related to software architecture and modularization, design of a testing regime, unique documentation needs and challenges, and the tension between intellectual property management and open science.
The next few sections outline the challenges that are either unique to, or are more dominant in scientific software than elsewhere. Section 1.2 outlines the possible lifecycle of a scientific code, followed by domain specific technical challenges in Section 1.3. Section 1.4 describes the technical and sociological challenges posed by the institutions where such codes are usually developed. Section 1.5 presents a case study of FLASH and Amanzi developments. Sections 1.6 and 1.7 present general observations and additional considerations for adapting the codes for the more challenging platforms expected in the future.
1.2 Lifecycle
Scientific software is designed to model phenomena in the physical world. The term physical includes chemical and biological systems since physical processes are also the underlying building blocks for these systems. A phenomenon may be microscopic (e.g. protein folding) or it can have extremely large or multiple scales (e.g. supernovae explosions). The physical characteristics of the system being studied translate to mathematical models that describe their essential features. These equations are discretized so that numerical algorithms can be used to solve them. One or more parts of this process may themselves be subjects of active research. Therefore the simulation software development requires diverse expertise and adds many stages in the development and lifecycle that may not be encountered elsewhere.
1.2.1 Development Cycle
For scientific simulations, modeling begins with equations that describe the general class of behavior to be studied. For example, the Navier–Stokes equations describe the flow of compressible and incompressible fluids, and Van der Waals equations describe interactions among molecules in a material. More than one set of equations may be involved if all behaviors of interest are not adequately captured by one set. In translating the model from mathematical representation to computational representation two processes go on simultaneously, discretization and approximation. One can argue that discretization is, by definition, an approximation because it is in effect sampling continuous behavior where information is lost in the sampling interval. This loss manifests itself as error terms in the discretized equations, but error terms are not the only approximations. Depending on the level of understanding of specific subphenomena and available compute resources, scientists also use their judgment to make other approximations. Sometimes, in order to focus on a particular behavior, a term in an equation may be simplified or even dropped. At other times some physical details may be dropped from the model because they are not understood well enough by the scientists. Or the model itself may be an approximation.
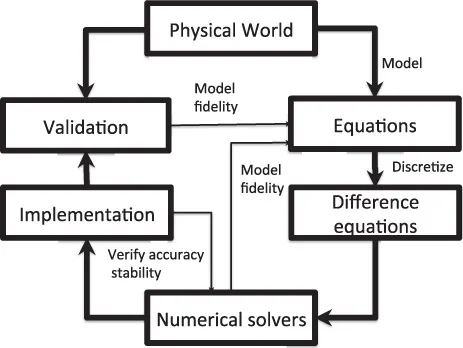
The next stage in developing the code is finding appropriate numerical methods for each of the models. Sometimes existing methods can be used without modification, but more often customization or new method development is needed. A method’s applicability to the model may need to be validated if the method is new or significantly modified. Unless a reliable implementation is already available as third-party software (stand-alone or in a library), the method has to be implemented and verified. At this stage the development of a scientific code begins to resemble that of general software. The numerical algorithms are specified, the semantics are understood, and they need to be translated into executable code. Even then, however, differences exist because scientific code developers work iteratively [51] and requirement specifications evolve through the development cycle. Figure 1.1 gives an example of the development cycle of a multiphysics application modeled by using partial differential equations.
1.2.2 Verification and Validation
The terms verification and validation are often used interchangeably, but to many scientific domains they have specific meaning. In their narrow definition, validation ensures that the mathematical model correctly defines the physical phenomena, while verification makes sure that the implementation of the model is correct. In other words, scientists validate a model against observations or experiments from the physical world, while developers verify the model by other forms of testing [46]. Other definitions give broader scope to verification and validation (e.g. [50]). For example, validation of a numerical method may be constructed through code-to-code comparisons, and its order can be validated through convergence studies. Similarly, the implementation of a solver can be validated against an analytically obtained solution for some model if the same solver can be applied and the analytical solution is also known [45]. Irrespective of specific definitions, correctness must be assured at all the stages from modeling to implementation.
The process of deriving a model involves many degrees of freedom as discussed earlier, therefore, the scientific experts carefully calibrate model validation. Similarly, in addition to correctness, applied mathematicians verify numerical methods for stability, accuracy, and order of convergence. Many numerical methods are themselves objects of ongoing research, so their implementation may need modifications from time to time. Whenever such modifications happen, the entire gamut of verification and validation needs to be applied again. This represents a particular challenge in scientific software where no amount of specification is enough to hand the implementation over to software engineers or developers who do not have domain or math knowledge. A close collaboration among various experts is necessary because the process has to be iterative, with scientific judgment applied at every iteration.
One other unique verification challenge in scientific software is caused by finite machine precision of floating-point numbers. Any change in compilers, optimization levels, and even order of operations can cause numerical drift in the solutions [40]. Especially in applications that have a large range of scales, differentiating between a legitimate bug and a numerical drift can be difficult [155]. Therefore, relying on bitwise reproducibility of the solution is rarely a sufficient method for verifying the continued correctness of an application’s behavior. Robust diagnostics (such as statistics or conservation of physical quantities) need to be built into the verification process. This issue is discussed in greater detail in Chapter 4.
Testing of scientific software needs to reflect the layered complexity of the codes. The first line of attack is to develop unit tests that isolate testing of individual components. In scientific codes, however, often dependencies exist between different components of the code that cannot be meaningfully isolated, making unit testing more difficult. In these cases, testing should be performed with a minimal possible combination of components. In effect, these minimally combined tests behave like unit tests because they focus on possible defects in a narrow section of the code. In addition, multicomponent scientific software should test various permutations and combination of components in different ways. Configuring tests in this manner can help verify that the configurations of interest are within the accuracy and stability constraints (see Section 1.5.1.2 for an example of testsuite configuration for FLASH).
1.2.3 Maintenance and Extensions
In a simplified view of the software lifecycle, there is a design and development phase, followed by a production and maintenance phase. Even in well-engineered codes this simplified view is usually applicable only to infrastructure and APIs. The numerical algorithms and solvers can be in a continually evolving state reflecting the advances in their respective fields. The development of scientific software is usually responding to an immediate scientific need, so the codes get employed in production as soon as they have a minimal set of capabilities for some simulation. Similarly, the development of computational modules almost never stops through the code lifecycle because new findings in science and math almost continuously place new demands on the code. The additions are incremental when they incorporate new findings into an existing feature; and they can be substantial when new capabilities are added. The need for new capabilities may arise from greater model fidelity or from trying to simulate a more complex model. Sometimes a code designed for one scientific field may have enough in common with another field that capabilities may be added to enable it for the new field.
Irrespective of the cause, coexistence of development and production/maintenance phases is a constant challenge to the code teams. It becomes acute when the code needs to undergo major version changes. The former can be managed with some repository discipline in the team coupled with a robust testing regime. The latter is a much bigger challenge where the plan has to concern itself with questions such as how much backward compatibility is suitable, how much code can go offline, and how to reconcile ongoing development in code sections that are substantially different between versions. FLASH’s example in Section 1.5.1.3 describes a couple of strategies that met the conflicting needs of developers and production users in both scenarios. Both required cooperation and buy-in from all the stakeholders to be successful.
1.2.4 Performance Portability
Performance portability...