![]()
1 What is data engineering?
This chapter covers
-
What is data engineering?
-
What do data engineers do?
-
How does Microsoft define data engineering?
-
What tools does Azure provide for data engineering?
Data collection is on the rise. More and more systems are generating more and more data every day.1
More than 30,000 gigabytes of data are generated every second, and the rate of data creation is only accelerating.
--Nathan Marz
Increased connectivity has led to increased sophistication and user interaction in software systems. New deployments of connected “smart” electronics also rely on increased connectivity. In response, businesses now collect and store data from all aspects of their products. This has led to an enormous increase in compute and storage infrastructure. Writing for Gartner, Mark Beyer defines “Big Data.”2
Big Data is high volume, high velocity, and/or high variety information assets that require new forms of processing to enable enhanced decision making, insight discovery, and process optimization.
--Mark A. Beyer
The scale of data collection and processing requires a change in strategy.
Businesses are challenged to find experienced engineers and programmers to develop the systems and processes to handle this data. The new role of data engineer has evolved to fill this need. The data engineer manages this data collection. Collecting, preparing, and querying of this mountain of data using Azure services is the subject of this book. The reader will be able to build working data analytics systems in Azure after completing the book.
1.1 What is data engineering?
Data engineering is the practice of building data storage and processing systems. Robert Chang, in his “A Beginner’s Guide to Data Engineering,” describes the work as designing, building, and maintaining data warehouses.3 Data engineering creates scalable systems which allow analysts and data scientists to extract meaningful information from the data.
Collecting data seems like a simple activity. Take reporting website traffic. A single user, during a site in a web browser, requests a page. A simple site might respond with an HTML file, a CSS file, and an image. This example could represent one, three, or four events.
-
What if there is a page redirect? That is another event.
-
What if we want to log the time taken to query a database?
-
What if we retrieve some items from cache but find they are missing?
All of these are commonly logged data points today.
Now add more user interaction, like a comparison page with multiple sliders. Each move of the slider logs a value. Tracking user mouse movement returns hundreds of coordinates. Consider a connected sensor with a 100 Hz sample rate. It can easily record over eight million measurements a day. When you start to scale to thousands and tens of thousands of simultaneous events, every point in the pipeline must be optimized for speed until the data comes to rest.
1.2 What do data engineers do?
Data engineers build storage and processing systems that can grow to handle these high volume, high velocity data flows. They plan for variation and volume. They manage systems that provide business value by answering questions with data.
Most businesses have multiple sources generating data. Manufacturing companies track the output of the machines, employees, and their shipping departments. Software companies track their user actions, software bugs per release, and developer output per day. Service companies check number of sales calls, time to complete tasks, usage of parts stores, and cost per lead. Some of this is small scale; some of it is large scale.
Analysts and managers might operate on narrow data sets, but large enterprises increasingly want to find efficiencies across divisions, or find root causes behind multi-faceted systems failures. In order to extract value from these disparate sources of data, engineers build large-scale storage systems as a single data repository. A software company may implement centralized error logging. The service company may integrate their CRM, billing, and finance systems. Engineers need to support the ingestion pipeline, storage backbone, and reporting services across multiple groups of stakeholders.
The first step in data consolidation is often a large relational database. Analysts review reports, CSV files, and even Excel spreadsheets in an attempt to get clean and consistent data. Often developers or database administrators prepare scripts to import the data into databases. In the best case, experienced database administrators define common schema, and plan partitioning and indexing. The database enters production. Data collection commences in earnest.
Typical systems based on storing data in relational databases have problems with scale. A single database instance, the simplest implementation, always becomes a bottleneck given increased usage. There are a finite amount of CPU cores and drive space available on a single database instance. Scaling up can only go so far before I/O bottlenecks prevent meeting response time targets. Distributing the database tables across multiple servers, or sharding, can enable greater throughput and storage, at the cost of greater complexity. Even with multiple shards, database queries under load display more and more latency. Eventually query latency grows too large to satisfy the requirements of the application.
The open source community answered the challenge of building web-scale data systems. Hadoop makes it easy to access vast disk storage. Spark provides a fast and highly available logging endpoint. NoSQL databases give users access to large stores of data quickly. Languages like Python and R make deep dives into huge flat files possible. Analysts and data scientists write algorithms and complex queries to draw conclusions from the data. But this new environment still requires system administrators to build and maintain servers in their data center.
1.3 How does Microsoft define data engineering?
Using these new open source tools looks quite different from the traditional database-centric model. In his landmark book, Nathan Marz coined a new term: Lambda architecture. He defined this as a “general-purpose approach to implementing an arbitrary function on an arbitrary data set and having the function return its results with low latency” (Marz, p.7)4. The goals of Lambda architecture address many of the inherent weaknesses of the database-centric model.
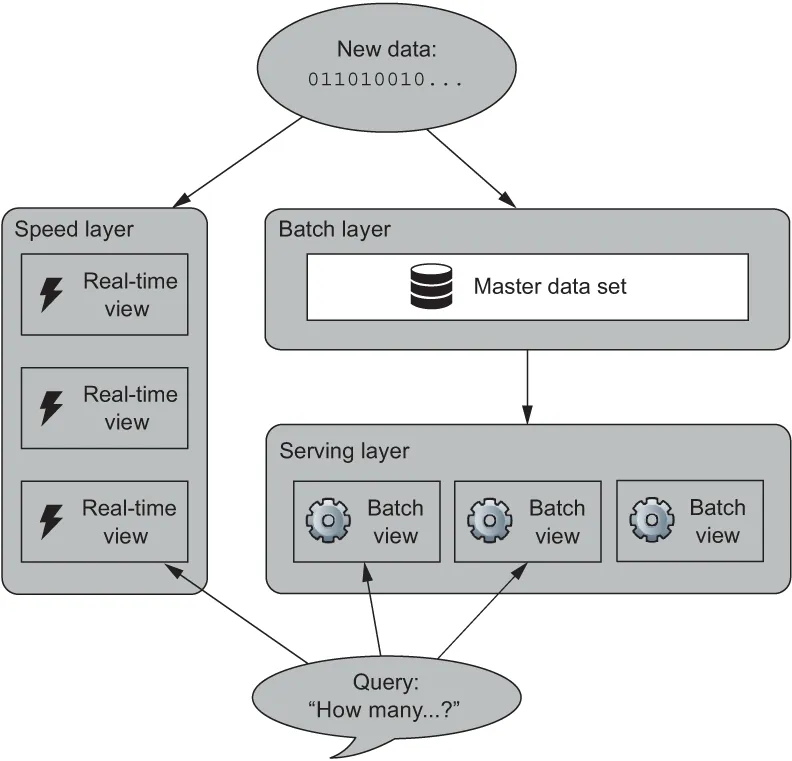
Figure 1.1 shows a general view of the new approach to saving and querying data. Data flows into both the Speed layer and the Batch layer. The Speed layer prepares data views of the most recent period in real time. The Serving layer delivers data views over the entire period, updated at regular intervals. Queries get data from the Speed layer, Serving layer, or both, depending on the time period queried.
Figure 1.1 Lambda analytics system, showing logical layers of processing based on query latency
Figure 1.2 describes an analytics system using a Lambda architecture. Data flows through the system from acquisition to retrieval via two paths: batch and stream. All data lands in long term storage, with scheduled and ad hoc queries generating refined data sets from the raw data. This is the batch process. Data with short time windows for retrieval run through an immediate query process, generating refined data in near-real time. This is the stream process.
-
Data is generated by applications, devices, or servers.
-
Each new piece of data is saved to long-term file storage.
-
New data is also sent to a str...