Jagdish Chandra Patni, Hitesh Kumar Sharma, Ravi Tomar, Avita Katal
This is a test
This is a test
Compartir libro
229 páginas
English
ePUB (apto para móviles)
Disponible en iOS y Android
eBook - ePub
Database Management System
An Evolutionary Approach
Jagdish Chandra Patni, Hitesh Kumar Sharma, Ravi Tomar, Avita Katal
Detalles del libro
Vista previa del libro
Índice
Citas
Información del libro
A database management system (DBMS) is a collection of programs that enable users to create and maintain a database; it also consists of a collection of interrelated data and a set of programs to access that data. Hence, a DBMS is a general-purpose software system that facilitates the processes of defining, constructing, and manipulating databases for various applications.
The primary goal of a DBMS is to provide an environment that is both convenient and efficient to use in retrieving and storing database information. It is an interface between the user of application programs, on the one hand, and the database, on the other.
The objective of Database Management System: An Evolutionary Approach, is to enable the learner to
grasp a basic understanding of a DBMS, its need, and its terminologies
discern the difference between the traditional file-based systems and a DBMS
code while learning to grasp theory in a practical way
study provided examples and case studies for better comprehension
This book is intended to give under- and postgraduate students a fundamental background in DBMSs. The book follows an evolutionary learning approach that emphasizes the basic concepts and builds a strong foundation to learn more advanced topics including normalizations, normal forms, PL/SQL, transactions, concurrency control, etc.
This book also gives detailed knowledge with a focus on entity-relationship (ER) diagrams and their reductions into tables, with sufficient SQL codes for a more practical understanding.
Preguntas frecuentes
¿Cómo cancelo mi suscripción?
Simplemente, dirígete a la sección ajustes de la cuenta y haz clic en «Cancelar suscripción». Así de sencillo. Después de cancelar tu suscripción, esta permanecerá activa el tiempo restante que hayas pagado. Obtén más información aquí.
¿Cómo descargo los libros?
Por el momento, todos nuestros libros ePub adaptables a dispositivos móviles se pueden descargar a través de la aplicación. La mayor parte de nuestros PDF también se puede descargar y ya estamos trabajando para que el resto también sea descargable. Obtén más información aquí.
¿En qué se diferencian los planes de precios?
Ambos planes te permiten acceder por completo a la biblioteca y a todas las funciones de Perlego. Las únicas diferencias son el precio y el período de suscripción: con el plan anual ahorrarás en torno a un 30 % en comparación con 12 meses de un plan mensual.
¿Qué es Perlego?
Somos un servicio de suscripción de libros de texto en línea que te permite acceder a toda una biblioteca en línea por menos de lo que cuesta un libro al mes. Con más de un millón de libros sobre más de 1000 categorías, ¡tenemos todo lo que necesitas! Obtén más información aquí.
¿Perlego ofrece la función de texto a voz?
Busca el símbolo de lectura en voz alta en tu próximo libro para ver si puedes escucharlo. La herramienta de lectura en voz alta lee el texto en voz alta por ti, resaltando el texto a medida que se lee. Puedes pausarla, acelerarla y ralentizarla. Obtén más información aquí.
¿Es Database Management System un PDF/ePUB en línea?
Sí, puedes acceder a Database Management System de Jagdish Chandra Patni, Hitesh Kumar Sharma, Ravi Tomar, Avita Katal en formato PDF o ePUB, así como a otros libros populares de Informatique y Sciences générales de l'informatique. Tenemos más de un millón de libros disponibles en nuestro catálogo para que explores.
Data is defined as raw bits or pieces of information that lack context. It doesn’t lead to any learning until processed. Data can be quantitative or qualitative in nature. Quantitative data is generally numerical, whereas qualitative data is descriptive in nature.
Quantitative data is the result of a measurement, count, or some other mathematical calculation. Data when brought to the context gives information, which can be further aggregated and analyzed to help us make decisions, and thus gain knowledge. For example, quantitative data such as 20, 30, 40, and 60 does not mean anything to us until we add context to it saying that this data is the number of students for specific classes. Thus, now it becomes information that can be used to set certain rules, policies, etc. in a university.
The main goal of the information system is to convert data into information in order to generate knowledge and thus further help in decision-making. Databases are designed for such purposes.
A database is defined as an organized collection of related information. All data stored in a database is related. For example, a student database should not hold information about airline reservation systems. The general-purpose software package that manages the data stored in a database is called a database management system (DBMS).
In the early years of computer generation, punch cards were used for data input and output and even for data storage. Databases came along much later. The first computer programs were developed in the 1950s [1]. At that time, computers were nothing but giant machines or, we can say, calculators that computed the results. The data was considered to be non-important or just as a leftover of the processing information, but as computers started being available commercially, this data, which was considered to be non-important, is now being used by business people for real-world purposes.
The integrated database system, the first DBMS, was designed in the 1960s by Charles W. Bachman [2]. IBM also at that time created a database system called IMS. Both these databases were considered as the predecessor of navigational databases (records/objects are found by following references from other objects). These databases became possible because of the advent of disks in contrast to magnetic tape and punched cards which were being used previously. The data access in such systems was possible only sequentially.
With time, the speed and flexibility of computers increased, and this led to the advent of many general-purpose database systems. This required a standardization, which led to the formation of the Database Task Group by Bachman who took responsibility for the standardization and design of a database. The group presented the “CODASYL approach” standard in 1971 [3]. The approach was complicated and required manual intervention as well as training. The records here could be accessed/searched through
Primary key (CALC key),
Moving relationships from one record to another (sets), and
Scanning the records in sequential order.
This approach became less popular over time because of its complex nature. Many easier systems came onto the market.
Edgar Codd, an employee of IBM, came up with a new idea for storing data and processing of large databases with his paper titled “A Relational Model of Data for Large Shared Data Banks” [4]. Unhappy with the searching mechanism of CODASYL and IMS of IBM, he used a table with fixed length records unlike in CODASYL where records were stored in a linked-list form. Michael Stonebraker and Eugene Wong from UC Berkeley showed interest and researched relational database systems under a project called INGRES in 1974 [5]. The project demonstrated that the model is practical as well as efficient. They worked with QUEL query language, and it led to the creation of systems such as Ingres Corp., MS SQL Server, Sybase, Wang’s PACE, and Britton-Lee. Another relational database system prototype was created by IBM called System R, which used SEQUEL query language and contributed to the development of SQL/DS, DB2, Allbase, Oracle, and NonStop SQL. IBM came up with SQL in 1974 (SQL became ANSI and OSI standards in 1986 and 1987), which replaced QUEL and many more functional query languages.
P. Chen introduced a new database model in 1976, which focused on data application rather than on logical table structure and was called entity-relationship model [6].
The success of relational database models boosted the database market, while the popularity of network and hierarchical database models slumped. IBM DB2 was the flagship product, and other products such as PARADOX, RBASE 5000, RIM, Dbase III and IV, OS/2 Database Manager, and Watcom SQL were also developed. Application development client tools were also released in the early 1990s along with the creation of object database management systems. Tools released include Oracle Developer, PowerBuilder, and VB. In the late 1990s, increase in the use of Internet database resulted in the release of many Internet database connectors such as Front Page, Active Server Pages, Java Servlets, Dream Weaver, ColdFusion, Enterprise Java Beans, and Oracle Developer 2000. Some open-source solutions provided for the Internet included CGI, GCC, MySQL, and Apache.
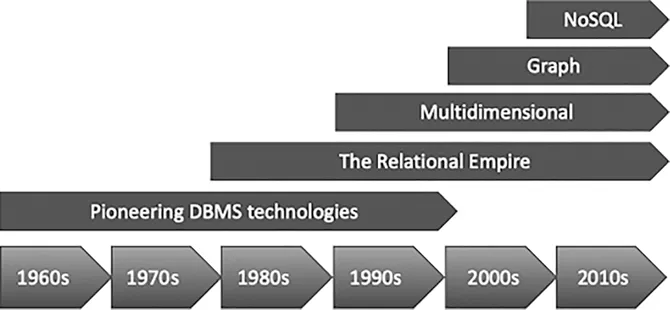
Relational database management systems (RDBMSs) though were efficient to store as well as process structured data. But with the passage of time and increased use of Internet for social media, unstructured data (such as photos, music, and videos) became more common. A RDBMS was not designed to handle such schema-less and nonrelational data. In addition, Structured Query Language also known as NoSQL came into the picture for catering to the needs of fast processing of unstructured data. It is a nonrelational data model and uses a distributed database system. It can handle structured as well as unstructured data. Although they have become very popular nowadays because of their high flexibility, scalability, lower costs, and capability to handle all kinds of data, they have some disadvantages associated too, one being that they are highly resource-intensive, that is, they require a high amount of RAM and CPU, and they lack tech support too (Figure 1.1).
FIGURE1.1 Evolution of database systems.
1.2 Data and Information
1.2.1 Data
In Section 1.1, we discussed data in general; data in the context of database is defined as an individual entity or a set of entities stored. The data stored in a database is generally organized in the form of rows and columns. Let’s take an example of a bank database, which has customer details, including their name, address, and telephone number. These attributes or columns of the bank database are simply data as they are not contributing to something that can help us make any or obtain any kind of important information.
The database data has the following features/characteristics associated with it:
Shared: Since the data in a database will be used to derive some information for the users, it should be shareable among users as well as applications.
Persistence: The data in the database resides permanently meaning that even if the process that generated the data or used it ends, the data still exists in the storage beyond the scope of the process creating or using it.
Integrity: Data stored in a database should be correct with respect to the real world.
Security: Data stored in a database should not be accessed by unauthorized users.
Consistency: The values stored in a database corresponding to the real world should also be consistent to the relation of those values.
Nonredundancy: No two data items should represent the same world entity.
Independence: The data representation at internal, conceptual, or external level should be independent of each other. Change in one level should not affect the other.
1.2.2 Information
In today’s age of information explosion, where we are being bombarded with too much data, information forms a very important resource, which provides a competitive edge to the organizations and businesses who are capable of processing it and using it to make decisions for surviving and excelling in the competitive market. As said by William Pollard, “Information is a source of learning. But unless it is organized, processed, and available to the right people in a format for decision-making, it is a burden, not a benefit” [7]. Refined data is information. The existing high-end systems have made it possible to manipulate and modify data. Information systems using such machines can thus work in different domains, for example, they can be used for building recommendation systems, engineering calculations, medical diagnosis, etc.
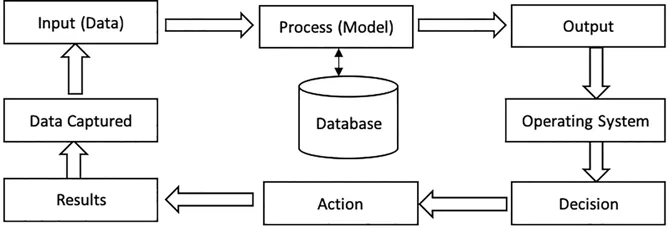
Information consists of data, images, text, documents, and voice. Data is processed through models to get information. The information generated reaches the recipient well in time and is used further for making decisions. These decisions can trigger other events and actions that generate large amounts of scattered data, which is captured again and sent as an input, and thus the cycle continues (Figure 1.2).
FIGURE1.2 Information cycle.
People are overloaded with misinformation. Thus, quality information is required. Quality information means accurate, timely, and relevant information.
Accuracy: Accuracy of information refers to the veracity of it. It means there should be no manipulated or distorted information. It should clearly convey the meaning of the data it is based on.
Timeliness: The information must reach the recipient within the needed time frame. The information may be of no use if it arrives late.
Relevancy: Relevancy of the information means that the information which may be relevant for one user may not be relevant for another even though it might have been accurate as well as timely. For example: A person who wants to know the configuration of the computer model may get the answer as “The price for the model is Rs 40,000”. Though the information is correct and timely, it is of no use.
1.3 Database
Database, in general, is defined as a collection of related data. This stored data has some relation or mapping to real-world scenarios, or we can say that it has some universe of discourse (miniworld). In addition, the stored data is coherent and not randomly arranged in nature, holding some implicit information. The stored data has some values, which are entered or fetched from it intended for use by a set of users or applications.
The basic purpose of having a database is to operate on a large amount of stored data in order to provide information out from it. Dynamic websites on the World Wide Web make use of databases. Booking hotel rooms from some trip planning websites is one such example.
A database can be of any size or complexity. If we consider the database of students in a department, it may consist of a few hundred records of different attributes/columns such as name, address, and roll no. But when we consider the university to be the miniworld of this database, this data may have thousands of entries, and then if the miniworld changes to universities in a country, the number of entries may be in lakhs.
The IRCTC system for booking rail tickets is one such example of database where millions of users try to book, cancel, or check the status of the tickets and trains. This system is used to book on average 5 lakh tickets per day; around 1.2 lakh people can use this IRCTC site at one time, and in a year, 31 crore tickets are booked [8]. IRCTC has generated higher revenue than commerce giants Flipkart and Amazon India. Thus, the database size and complexity very much depend on the miniworld it is being used in.
1.4 Need for a Database
A database can be defined as a collection of data, which is designed to be used by different people. The question which will come to our mind again and again is why we need a database when we already have the data for an organization stored in disks and tapes in the form of files. The question itself has ...