Computer Science
Unsupervised Learning
Unsupervised learning is a type of machine learning where the model is trained on unlabeled data, without specific guidance or feedback. The goal is to find hidden patterns or structures within the data, such as clustering similar data points or dimensionality reduction. This approach is useful for exploring and understanding complex datasets without predefined categories or labels.
Written by Perlego with AI-assistance
Related key terms
1 of 5
11 Key excerpts on "Unsupervised Learning"
 eBook - ePub
eBook - ePubMachine Learning
Master Supervised and Unsupervised Learning Algorithms with Real Examples (English Edition)
- Dr Ruchi Doshi, , Ritesh Kumar Jain, (Authors)
- 2021(Publication Date)
- BPB Publications(Publisher)
HAPTER 3Unsupervised Learning
U nsupervised learning is an ML technique that deals with unlabeled data. This unlabeled data is used by Unsupervised Learning algorithms to discover patterns of correlated data and information. These algorithms don’t require any supervision, instead, it works on its techniques to discover the patterns. As compared to other learning methods, Unsupervised Learning methods are more unpredictable. Moreover, as compared to supervised learning, Unsupervised Learning performs more complex tasks, that includes: neural network, anomaly detection, clustering, and so on.Structure
In this chapter, you will learn the following topics:- Unsupervised Learning
- Clustering
- Hierarchical clustering
- K-mean clustering
- Probabilistic clustering
- Apriori Algorithm
- Association rule mining
- Gaussian Mixture Model (GMM)
- FP-Growth Algorithm
Objectives
After reading this chapter, you will be able to understand the concepts of various algorithms of Unsupervised Learning techniques. Knowledge of these algorithms will help you to analyze, evaluate, and group the unlabeled data items using various clustering techniques.Unsupervised Learning
This is a powerful machine learning technique. In this technique, the designed model doesn’t require any observation or supervision to process the unlabeled data. Instead, this technique accepts unlabeled data items and discovers new patterns of information that were previously unknown or undetected. We can understand this technique with the help of its working process that is shown in Figure 3.1 .Working of Unsupervised Learning
It is easy to understand the working of Unsupervised Learning through the following steps:- An Unsupervised Learning model accepts unlabeled raw data items as input. Unlike supervised learning, it doesn’t require any training, testing, and labeled output data.
 eBook - PDF
eBook - PDF- Sourabh Pal(Author)
- 2023(Publication Date)
- Arcler Press(Publisher)
The inputs to each of the training sets are incorrectly categorized. This is a serious problem. This can result in issues if the implemented method is dominant enough to remember “special situations” that are not fit for the general principles of the algorithm in question. Overfitting can occur as a result of this. It is quite difficult to discover algorithms that are both powerful enough just to absorb complex functions and vigorous enough to yield outcomes that are generalizable over a wide range of situations (Figure 6.4) (Hopfield, 1982; Timothy, 1998). Figure 6.4. Schematic illustration of machine learning supervise procedure. Source: https://www.intechopen.com/books/new-advances-in-machine-learn- ing/types-of-machine-learning-algorithms. Machine Learning Algorithms 147 6.3. Unsupervised Learning This strategy appears to be considerably more difficult: the purpose of this approach is to teach the computer how to do a task without our assistance. Unsupervised Learning can be accomplished in two ways. The first way entails training the agent by implementing a reward system that shows achievement rather than by offering unambiguous categorizations. Because the purpose is to make decisions that will enhance the rewards rather than to produce a classification, this form of training is usually appropriate for the decision issue frame. This strategy is well-suited to the actual world, where agents may be rewarded for certain activities and chastised for others (LeCun et al., 1989; Bilmes, 1998; Alpaydm, 1999). Unsupervised Learning is a type of supportive learning in which the agent’s behaviors are based on previous punishments and rewards deprived of necessarily learning information about the direct ways in which they affect the real environment. This knowledge is useless in the sense that once the agent has been accustomed to the reward function, he or she knows exactly what action to take without having to think about it. eBook - PDF
eBook - PDFMachine Learning with Neural Networks
An Introduction for Scientists and Engineers
- Bernhard Mehlig(Author)
- 2021(Publication Date)
- Cambridge University Press(Publisher)
Part III Learning without Labels Chapters 5 to 9 describe supervised learning of labelled data with neural networks. The network is trained to reproduce the correct labels (targets) for each input pat- tern. The analysis of unlabelled data requires different methods. Machine learning can be applied with success to large data sets of high-dimensional unlabelled data. The machine can for instance mark patterns that are typical for the given distribu- tion, or detect outliers. Other tasks are to detect similarity, to find clusters in the data (Figure 10.1), and to determine non-linear, low-dimensional representations of high-dimensional data. More recently, such Unsupervised Learning algorithms have been used to generate synthetic data, patterns that resemble those in a certain data set. One possible application is data-set augmentation for supervised learning. Learning without labels is called Unsupervised Learning, because there are no tar- gets that tell the network whether it has learnt correctly or not. There is no obvious function to fit, or dynamics to learn. Instead, the network organises the input data in relevant ways. This requires redundancy in the input data [1]. It is sometimes said that Unsupervised Learning corresponds to learning without a teacher, implying that the network itself discovers suitable ways of organising the input data. This is inaccurate, because unsupervised networks usually operate with a pre-determined learning rule, like Hopfield networks. Figure 10.1 Supervised learning finds decision boundaries for labelled data, like in the binary classification problem shown on the left. Unsupervised Learning can find clusters in the input data (right) 178 Learning without Labels Part III of this book is organised as follows: Chapter 10 describes unsupervised- learning algorithms, starting with unsupervised Hebbian learning to detect famil- iarity and similarity of input patterns (Sections 10.1 and 10.2). eBook - ePub
eBook - ePubEssentials of Deep Learning and AI
Experience Unsupervised Learning, Autoencoders, Feature Engineering, and Time Series Analysis with TensorFlow, Keras, and scikit-learn
- Shashidhar Soppin, B N Chandrashekar, Dr. Manjunath Ramachandra, Shashidhar Soppin, B N Chandrashekar, Dr. Manjunath Ramachandra(Authors)
- 2021(Publication Date)
- BPB Publications(Publisher)
HAPTER 3System Analysis with Machine Learning/Un-Supervised Learning
W e might have encountered questions such as “why Unsupervised Learning? ”, “what is it all about? ”, and “how different it is as compared to the supervised learning algorithms and methods? ”.In real-world scenarios, many times labeled data may not be available. Data patterns and data format is also not well defined and available to us. In these cases, we go for the Unsupervised Learning mechanisms and algorithms to solve the mystery.The Fashion-MNIST dataset is an example mapped to the labeled classes and can easily be a reference for the supervised learning algorithms. But this same data set can be used without the “labels ” for Unsupervised Learning mechanisms and algorithms.As explained in the earlier section, machine learning is defined as one of the branches of computer science in which the algorithms learn from the data or data sets available to them. Most of the machine learning algorithms are designed based on these algorithms and data sets. These predominant algorithms work on labeled data. But there are some algorithms that work without the labeled data. Using unlabeled data, the system can extract the patterns and use them for interpretation. Using unlabeled data is a bit challenging and tricky as compared to simply labeled data sets. Classifying these into groups of similar character or similar nature without the labels is one of the methods used.
- Sachi Nandan Mohanty, Jyotir Moy Chatterjee, Monika Mangla, Suneeta Satpathy, Sirisha Potluri(Authors)
- 2021(Publication Date)
- Wiley-Scrivener(Publisher)
For CIOs and CISOs concerned over safekeeping, agreement and success SLAs, it is really hard to distinguish that ever-raising dimensions and variations of data, and it is not persuasively believable aimed at an officer or level a line-up of administrators and data scientists to crack these encounters [12]. Luckily, machine learning here can help with unsupervised algorithms.A division of deep learning and machine learning observations might be appointed to achieve this [14]. Approximately talking, machine/deep learning methods can be confidential as also Unsupervised Learning, supervised learning, or strengthening learning:- The supervised learning contains the learning from the data that is by now “labeled” which is the arrangement and “result” for each data idea is recognized in advance [15].
- Equally, the Unsupervised Learning, such as the k-means clustering will be used as soon as the data is “unlabeled” which is an alternative way of maxim that the data is unsystematic [16].
- The machine learning depends on the part of rules or restraints distinct upon a system to regulate a best-known strategy to achieve an objective.
A prime for what method was be determined for which issue is being resolved is the key frame work done alongside of machine learning [17]. As an example, could be supervised learning device such as an arbitrary jungle can be used to create a frontline or baseline, for what institutes “normal” behavior for an organization [18], by seeing through applicable characteristics, then that uses that front or baseline to examine irregularities which are been lose from that baseline. Such type arrangement may be uses for perceiving threat fears for an organization [19]. That is mainly appropriate in classifying error occurrences and threats which would be slowly evolving into the nature and would not encode the data once at on one occasion which can be rather progressively being over the time [20].Though, as an initial in the training in which the data is used in typical recreation named as unlabeled, there interpreted supervised learning methods somehow are useless [21]. While in case of Unsupervised Learning might appear as a normal and appropriate fit which is a substitute method that can possibly will results the further precise methods of models includes a pre-processing action to allocate labels to unlabeled data in such a move that make it functioning for the supervised learning [22]. Alternative motivating phase of engagement of data is using the deep learning method is to classify, tag, and mask the PII data as earlier discussed [23]. Making them consistent expressive and static ideology of data may be used for that purpose, by means of deep learning allows understanding for the precise formats (Even tradition PII types [24]) which is used in an association. Convolutional Neural Networks (CNNs) have been positively used for the image processing, thus discovering the usage for PII acquiescence is another interesting opportunity to get the information [25]. eBook - PDF
eBook - PDF- Rex Porbasas Flejoles(Author)
- 2019(Publication Date)
- Arcler Press(Publisher)
For example, when the computer programs which learned through the Unsupervised Learning became robust than the finest human chess players, the predictable wisdom in the game (backgammon) was spun on its head. These programs learned certain principles which shocked the backgammon specialists and performed far better than the backgammon programs taught on the pre-classified examples. Clustering is another type of Unsupervised Learning. In this kind of learning the objective is to find the resemblances in training data, not to maximize the utility function (Xu & Jordan, 1996; Mitra et al., 2008). Now here the supposition is that the clusters found will match sensibly well with the intuitive classification. For example, the clustering individuals which are based on demographics may outcome in the clustering of the wealthy in one set and of the poor in the other set. Though the algorithm won’t assign names to these clusters it can create them and then by using these Types of Machine Learning Algorithms 85 clusters can allocate new examples into one of the clusters (Herlihy, 1998; Gregan ‐ Paxton et al., 2005). Described above is the data-driven approach which performs well when sufficient data is available for example social information sifting algorithms, used by Amazon.com to recommend books (Stewart & Brown, 2004; Sakamoto et al., 2008). These algorithms are based on the principle of discovering analogous sets of people and allocating new consumers to groups. In the case of social information filtering information about the other fellows of a cluster is adequate for the algorithm to create meaningful results. In the rest of the cases, the clusters are simply a beneficial tool for an expert analyst. Unfortunately, the Unsupervised Learning also faces this problem of overfitting.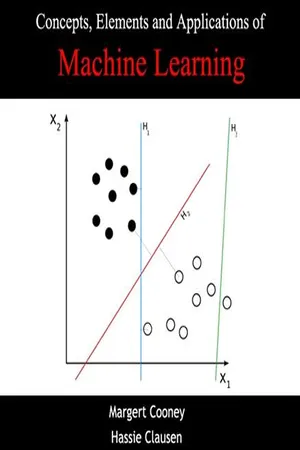 No longer available |Learn more
No longer available |Learn more- (Author)
- 2014(Publication Date)
- College Publishing House(Publisher)
____________________ WORLD TECHNOLOGIES ____________________ Chapter 3 Types of Machine Learning Machine learning algorithms are organized into a taxonomy, based on the desired outcome of the algorithm. Unsupervised Learning In machine learning, Unsupervised Learning is a class of problems in which one seeks to determine how the data are organized. Many methods employed here are based on data mining methods used to preprocess data. It is distinguished from supervised learning (and reinforcement learning) in that the learner is given only unlabeled examples. Unsupervised Learning is closely related to the problem of density estimation in statistics. However Unsupervised Learning also encompasses many other techniques that seek to summarize and explain key features of the data. One form of Unsupervised Learning is clustering. Another example is blind source separation based on Independent Component Analysis (ICA). Among neural network models, the Self-organizing map (SOM) and Adaptive resonance theory (ART) are commonly used Unsupervised Learning algorithms. The SOM is a topographic organization in which nearby locations in the map represent inputs with similar properties. The ART model allows the number of clusters to vary with problem size and lets the user control the degree of similarity between members of the same clusters by means of a user-defined constant called the vigilance parameter. ART networks are also used for many pattern recognition tasks, such as automatic target recognition and seismic signal processing. The first version of ART was ART1, developed by Carpenter and Grossberg(1988). ____________________ WORLD TECHNOLOGIES ____________________ Semi-supervised learning In computer science, semi-supervised learning is a class of machine learning techniques that make use of both labeled and unlabeled data for training - typically a small amount of labeled data with a large amount of unlabeled data. eBook - PDF
eBook - PDF- A. Engel, C. Van den Broeck(Authors)
- 2001(Publication Date)
- Cambridge University Press(Publisher)
8 Unsupervised Learning In the preceding chapters we investigated in detail the scenario of a student perceptron learning from a teacher perceptron. This is a typical example of what is commonly referred to as supervised learning. But we all gratefully acknowledge that learning from examples does not always require the presence of a teacher! However, what is it that can be learned besides some specific classification of examples provided by a teacher? The key observation is that learning from unclas-sified examples is possible if their distribution has some underlying structure . The main issue in Unsupervised Learning is then to extract these intrinsic features from a set of examples alone. This problem is central to many pattern recognition and data compression tasks with a variety of important applications [110]. Far from attempting to review the many existing approaches to Unsupervised Learning, we will show in the present chapter how statistical mechanics methods in-troduced before can be applied to some special scenarios of Unsupervised Learning closely related to the teacher–student perceptron problem. This will illustrate on the one hand how statistical mechanics can be used for the analysis of unsupervised situations, while on the other hand we will gain new understanding of the supervised problem by reformulating it as a special case of an unsupervised one. 8.1 Supervised versus Unsupervised Learning Consider a set of p examples drawn at random from some probability distribution P . The aim of Unsupervised Learning is to extract information on P on the basis of the examples. For simplicity, and in order to preserve the continuity with the supervised problems discussed so far, we assume that the examples may be represented by N -dimensional vectors ξ = { ξ i , i = 1 , . . ., N } lying on the surface of the N -sphere, i.e. ξ 2 = N . We will restrict ourselves to the study of data point distributions with very weak structure only. eBook - ePub
eBook - ePub50 Algorithms Every Programmer Should Know
An unbeatable arsenal of algorithmic solutions for real-world problems
- Imran Ahmad(Author)
- 2023(Publication Date)
- Packt Publishing(Publisher)
: ). It also gives us the support of each of the rules in our input dataset.Summary
In this chapter, we looked at various unsupervised machine learning techniques. We looked at the circumstances in which it is a good idea to try to reduce the dimensionality of the problem we are trying to solve and the different methods of doing this. We also studied the practical examples where unsupervised machine learning techniques can be very helpful, including market basket analysis.In the next chapter, we will look at the various supervised learning techniques. We will start with linear regression and then we will look at more sophisticated supervised machine learning techniques, such as decision-tree-based algorithms, SVM, and XGBoost. We will also study the Naive Bayes algorithm, which is best suited for unstructured textual data.Learn more on Discord
To join the Discord community for this book – where you can share feedback, ask questions to the author, and learn about new releases – follow the QR code below: https://packt.link/WHLel eBook - PDF
eBook - PDF- Walter W. Piegorsch, Richard A. Levine, Hao Helen Zhang, Thomas C. M. Lee, Walter W. Piegorsch, Richard A. Levine, Hao Helen Zhang, Thomas C. M. Lee(Authors)
- 2022(Publication Date)
- Wiley(Publisher)
183 Part III Statistical Learning 185 10 Supervised Learning Weibin Mo and Yufeng Liu University of North Carolina at Chapel Hill, Chapel Hill, NC, USA 1 Introduction Supervised learning is an important type of machine learning problems which focuses on the learning task using training data with both covariates and response variables. Super-vised learning problems are commonly seen in practice. In finance, the future price of a stock can be forecast by the historical stock prices and many macroeconomic factors. The forecasting of the future stock price can help with the buy and sell decisions or the valuation of the underlying assets. In medicine, the patient’s illness can be predicted by the patient’s characteristics, symptoms, clinical test results, and the medical treatments received. The predictive model can help the physician to diagnose illness and decide whether to intro-duce a treatment therapy for a given patient. In a context-based recommender system, the contextual information such as time, location, and social connection can be used to predict the recipient’s feedback, which can help to improve the effectiveness of the recommender. These applications involve the covariate–response data, also known as the input–output data. A common goal of these applications is to find a model that predicts the response from the covariates [1]. In contrast to the supervised learning problem, an Unsupervised Learning task does not involve the response variable, and the goals are typically related to dimension reduction or discovering useful patterns [2]. In this chapter, we mainly focus on supervised learning and specifically consider tech-niques that can be formulated as the optimization of “loss + penalty.” In particular, the loss term keeps the fidelity of the resulting model to the data, while the penalty term penalizing the complexity can prevent the fitted model from overfitting [3]. eBook - PDF
eBook - PDFArchives, Access and Artificial Intelligence
Working with Born-Digital and Digitized Archival Collections
- Lise Jaillant(Author)
- 2022(Publication Date)
- Bielefeld University Press(Publisher)
Ways to qualify the output of machine learning will be a key issue, due to the influence o f the technology not only on scholarly work with documents (as data), but also due to the embeddedness of machine learning in the algorithms of our daily life. Quantification of results using statistical tech-niques, such as the F1-score (a comparison of an algorithm’s recall and precision) or percentages of correctly identified characters (if we think about text recognition), is one indication of the capability of an algorithm, but it doesn’t show problems, un-certainties, or bias induced by the approach. F1-scores, for example, tell us about the quality and quantity of intended results, but say nothing about unintended consequences due to any imprecisions. To highlight the dif ferences among machine learning approaches, I will pro-vide two examples that use dif ferent types of machine learning (supervised and unsupervised) and deal with questions for which machine learning yields impres-sive results. For the unsupervised approach, I will look at topic modeling, and for the supervised counterpart, the application of deep learning to the recognition of handwritten documents. The aim is only to introduce briefly the two approaches from a rather theoretical point of view, not to provide a how-to guide for the two methods. 14 3. Topic Modeling: Unsupervised Clustering One of the main advantages computers have over humans is their ability to count and compare extremely quickly. With topic modeling, scholars use these two traits and try to apply them to text. The algorithms used for topic modeling work in two directions: First, they count the appearance of strings (called “tokens”) in textual entities (e.g. a letter or a document). The expected term for “token” might instead be “word,” but since this term is polysemic and could mean a string of characters (a token) or the semantic meaning of the string (in a sense the lemmatized token), we will use token instead.
Index pages curate the most relevant extracts from our library of academic textbooks. They’ve been created using an in-house natural language model (NLM), each adding context and meaning to key research topics.