1 Introduction to microarray technology
Jon L. Hobman, Antony Jones, and Chrystala Constantinidou
‘Man is a tool-using animal...Without tools he is nothing, with tools he is all’ – Thomas Carlyle (1795–1881)
‘The mechanic who wishes to do his work well, must first sharpen his tools.’ – Analects of Confucius 15: 9
1.1 Introduction to the technology and its applications
1.1.1 Microarrays as research tools
Large-scale DNA sequencing projects and the completion of increasing numbers of genome sequences is having a major impact on biological research. The ‘post-genomic era’ is characterized by exploitation of genomic DNA sequence data as a research resource, and the use of high throughput experimental methods to study organism-wide events and interactions. These technical advances combined with increasing amounts of available genomic data have started to influence the direction that biological research is taking. Until quite recently, there has been a concentration on the reductive (‘bottom up’) view of understanding how an organism grows, adapts to changing conditions, or interacts with other organisms. This has been achieved by research groups studying single genes or regulons, or by determining the structure and function of small numbers of proteins, or by studying interactions between small numbers of cellular components. The use of the data generated in these experiments has led us to an understanding of how many cellular components work, and how some of these components interact with each other. However, in much the same way that understanding what a component in a radio does, or what happens when that component part of that radio is damaged or removed, does not lead to an understanding of how the radio works, we are faced with similar problems in describing how organisms work by looking at their components in isolation (Lazebnik, 2002). Now, there is a momentum towards the whole organism view of biology (Twyman, 2004a), using the holistic (‘top down’) approach of trying to understand how an organism works in its entirety and how the networks of physical and functional interactions occur between gene promoters, proteins, and noncoding RNAs (Brasch et al., 2004). Attempts to understand the whole organism have led to the emergence of systems biology as a new cross-disciplinary research area, which encompasses experimental research, systems and control theory, bioinformatics, and theoretical and computational model building and prediction.
The development of appropriate technologies (experimental research tools) that exploit genomic data is playing a major role in the development of whole organism studies, and will begin to allow us to dissect networks of gene regulation (transcriptomics), understand protein production patterns and interactions with other proteins (proteomics), study the interactions of small molecules with proteins (chemical genomics), and start to catalog the small molecules and metabolites found in cells during normal and abnormal function (metabolomics).
One of the most important research tools used in transcriptomics and proteomics studies is the ‘array’, which is a powerful, high-throughput, massively parallel-assay format used for studying interactions between biological molecules. Arrays are a good example of how an advance in technology has allowed researchers to test hypotheses and interrogate organisms on a scale which prior to the development of this technology would have been impossible.
1.1.2 Arrays and microarrays
The use of ordered arrangements or ‘arrays’ of spatially addressed molecules in parallel assays is becoming an increasingly popular technology for studying interactions between biological molecules. These assays are commonly referred to as arrays, and by extension assays that have been miniaturized to a small format are called microarrays. The biological materials used in these arrays can be nucleic acids, proteins or carbohydrates, whilst arrays of chemicals and other small molecules have also been made. These materials are most commonly deposited on the surface of a planar solid substrate in an ordered arrangement so that each positional coordinate where material has been deposited contains material that represents a single gene or protein or other molecule. The most widely used solid substrates for arrays are nylon or nitrocellulose membranes, glass slides or silicon/quartz materials.
For DNA arrays, as the numbers of different nucleic acid molecules that are printed on arrays has become larger, so that the array represents the whole genome of the organism, and each spot on the array represents a single gene, the imperative has been to miniaturize the array format. There are two drivers for miniaturization: the first is simply so that all of the features (e.g. spots of DNA, each representing one gene) could be fitted onto a conveniently sized solid substrate, and the second is to use smaller and smaller amounts of biological material on the arrays, because high throughput methods of sample preparation tend to be restricted in the amount of biological material that can be purified using them. Concomitant with miniaturization of the array there has also been a trend towards decreasing the amount of biological material (e.g. RNA) used in the array experiments, as the less material that needs to be used, the easier it is to extract and purify it, and the more economical it is in terms of reagent costs.
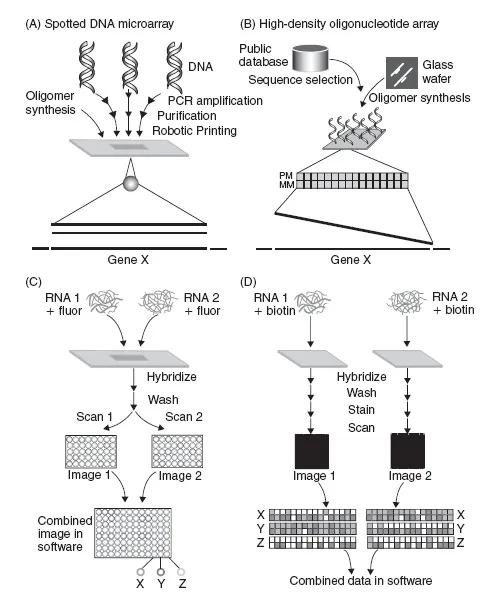
There are several widely established formats that are used for DNA microarrays. These array types fall into two categories: those that are constructed within laboratories, and those that are produced under industrial manufacturing conditions by commercial companies. The first type, developed by the Pat Brown lab at Stanford University (Schena et al., 1995, 1996; DeRisi et al., 1997; Heller et al., 1997) is the so-called ‘home brew’ or ‘roll your own’ glass slide microarrays, which are produced in-house, often in a core facility. The most popular technology for printing in-house arrays appears from anecdotal evidence to be contact printing, which is used by a large number of university research laboratories, and will be covered in some detail in this section (Figure 1A). The second format is the manufactured array, of which the best known is the Affymetrix GeneChip™ format, which is discussed in more detail in Section 1.4 (Figure 1B). In addition to these two well-known array formats there are other formats offered by commercial companies, such as Agilent, Nimblegen, Oxford Gene Technology, Xeotron, Combimatrix, Febit, and Nanogen. Each of these formats is more or less related in concept to the spotted array or Affymetrix formats. Agilent technologies (http://www.chem.agilent.com/Scripts/PCol.asp?lPage=494) have developed a method for depositing long oligonucleotides (60-mers) on to glass slides, using ink jet printing (Hughes et al., 2001). This printing method is also used by Oxford Gene Technology (OGT) to create arrays (http://www.ogt.co.uk/). OGT is a company created by Professor E.M. Southern, which owns fundamental European and US patents on microarray technology. Nanogen (http://www.nanogen.com/) have developed a method of electronically addressing oligonucleotides to positions on a chip, and enhancing hybridization by using electronic pulsing (Edman et al., 1997; Sosnowski et al., 1997; Heller et al., 1999, 2000). Nimblegen (http://www.nimblegen.com/technology/) use a proprietary maskless array synthesizer (MAS) technology, to synthesize high density arrays, using photodeposition chemistry for oligonucleotide synthesis on a solid support. This system uses a digital micromirror device (DMD) in which an array of small aluminum mirrors are used to pattern over 750 000 pixels of light. The DMD creates ‘virtual masks’ at specific positions on a microarray chip that protects these regions from UV light that is shone over the array surface. In positions on which the UV light shines, it deprotects the oligonucleotide strand already synthesized, allowing the addition of a new nucleotide to the lengthening oligonucleotide (Nuwaysir et al., 2002; Albert et al., 2003). Nimblegen uses short oligonucleotide (25-mer) technology in their arrays, and are producing high density tiling arrays for resequencing and ChIP-chip experiments (see Section 1.1.4). Xeotron (who have recently been acquired by Invitrogen http://www.invitrogen.com/content.cfm?pageid=10620) use a proprietary platform technology for synthesis of DNA microarrays. The arrays are made by in situ parallel combinatorial synthesis of oligonucleotides in three-dimensional nano-chambers. The process of oligonucleotide synthesis uses photogenerated acids to deprotect oligonucleotide capping, and uses digital projection photolithography to direct deprotection and parallel chemical synthesis (Gao et al., 2001; Venkatasubbarao, 2004). This method has also been used to produce peptide arrays and can be used for other syntheses. Combimatrix (http://www.combimatrix.com/) uses a different technology to generate the acids used to detritylate capped oligonucleotides during in situ phosphoramidite synthesis. Rather than using light-directed acid generation, Combimatrix uses a specially modified ‘CMOS’ semiconductor to direct synthesis of DNA in response to a digital command. Each feature on the array is a microelectrode, which can selectively electrochemically generate acid, during oligonucleotide synthesis using phosphoramidite chemistry. Febit (http://www.febit.de/index.htm) market an all-in-one machine that synthesizes oligonucleotide arrays using maskless light activated synthesis of microarrays controlled by a digital projector, hybridizes the fabricated arrays, and analyzes the data. New microarray technologies such as nonplanar DNA microarrays made by companies such as Illumina (http://www.illumina.com), PharmaSeq (http://www.pharmaseq.com), and SmartBead Technologies (http://www.smartbead.com) are constantly evolving, and a recent review of the state of the art and future prospects indicates that the evolution of the technology is proceeding rapidly (Venkatasubbarao, 2004).
Figure 1.1
Expression analysis experiments using spotted glass DNA microarrays, and Affymetrix DNA microarrays. (A) Spotted glass microarrays are produced by the robotic spotting of PCR products, cDNAs, clone libraries or long oligonucleotides onto coated glass slides. Each feature (spot) on the array corresponds to a contiguous gene fragment of 40–70 nucleotides for oligonucleotide arrays, to several hundred nucleotides for PCR products. (B) Affymetrix high-density oligonucleotide arrays are manufactured using light directed in situ oligonucleotide synthesis. Each gene from the organism is generally represented by ten or more 25-mer oligonucleotides, which are designed to be a perfect match (PM) or a mismatch (MM) to the gene sequence. (C) For spotted arrays, gene expression profiling experiments commonly involve the conversion of RNA or mRNA to cDNA and labeling of the cDNA with a fluorescent dye for two samples. These are cohybridized to the probes on the array, which is then scanned to detect both fluorophores. The spots X, Y, and Z at the bottom of the image represent (X) increased levels of mRNA for gene X in sample 1, (Y) increased levels of mRNA for gene Y in sample 2, and (Z) similar levels of mRNA of gene Z in both samples. (D) During Affymetrix GeneChip transcription experiments, cRNA is biotinylated, and hybridized to the GeneChip. The GeneChip is then stained with avidin conjugated to a fluorophore, and scanned with a laser scanner. Results show: (X) Increased levels of expression of genes in sample 1, (Y) Increased levels of gene expression for sample 2, and (Z) similar gene expression levels for both samples. Reprinted from Harrington et al. (2000) Curr Opin Microbiol 3: 285–291, with permission from Elsevier. (A color version of this figure is available at the book’s website, www.garlandscience.com/9780415378536)
Aside from differences in the method of array manufacture (deposition of prepared material versus in situ synthesis) the major differences between DNA array types is the nucleic acid material that is deposited onto the solid surface. Early-spotted DNA arrays deposited PCR products amplified from genes or open reading frames (ORFs), or spotted plasmid preparations from gene libraries, cDNAs, or expressed sequence tag clones (ESTs). As more complete genome sequences have been deciphered, complete genome sequence data is being used for the design of the materials deposited on the arrays. Primer design software can be used to design PCR primers to amplify regions from each gene from a sequenced genome for arraying (see http://colibase.bham.ac.uk/ as an example of a website that integrates genome analysis and primer design software tools), and PCR arrays have the advantage that they will represent both the sense and antisense strands of DNA. Single stranded oligonucleotide arrays by their nature can only be sense or antisense arrays, so their design requires careful thought because transcriptomics experiments use labeled complementary DNA (cDNA) made from mRNA to hybridize onto the array, so sense oligonucleotide arrays will hybridize to these cDNAs, but antisense ones will not. Genome sequence data and bioinformatics techniques have been used in the rational design and chemical synthesis of long oligonucleotides (40–100-mer) to represent genes on arrays, so that each has a matched melting temperature and length, which is claimed to improve the reliability of hybridization signals. Both of these two ‘longmer’ methods rely on a single, long nucleotide fragment to represent each gene or ORF on the array. The alternative strategy employed for DNA arrays (such as Affymetrix and Nimblegen arrays) has been the use of multiple short oligonucleotides (generally 25-mer) on an array to represent a gene. The use of high density oligonucleotide arrays such as these to ‘tile’ across a genome so that intergenic regions as well as ORFs and genes are represented by multiple oligonucleotides, has led to greater flexibility in the experiments that can be performed on these arrays, whic...