
eBook - ePub
Bioinformatics
Genes, Proteins and Computers
Christine Orengo, David Jones, Janet Thornton, Christine Orengo, David Jones, Janet Thornton
This is a test
Condividi libro
- 320 pagine
- English
- ePUB (disponibile sull'app)
- Disponibile su iOS e Android
eBook - ePub
Bioinformatics
Genes, Proteins and Computers
Christine Orengo, David Jones, Janet Thornton, Christine Orengo, David Jones, Janet Thornton
Dettagli del libro
Anteprima del libro
Indice dei contenuti
Citazioni
Informazioni sul libro
Bioinformatics, the use of computers to address biological questions, has become an essential tool in biological research. It is one of the critical keys needed to unlock the information encoded in the flood of data generated by genome, protein structure, transcriptome and proteome research.
Bioinformatics: Genes, Proteins & Computers covers both the more traditional approaches to bioinformatics, including gene and protein sequence analysis and structure prediction, and more recent technologies such as datamining of transcriptomic and proteomic data to provide insights on cellular mechanisms and the causes of disease.
Domande frequenti
Come faccio ad annullare l'abbonamento?
È semplicissimo: basta accedere alla sezione Account nelle Impostazioni e cliccare su "Annulla abbonamento". Dopo la cancellazione, l'abbonamento rimarrà attivo per il periodo rimanente già pagato. Per maggiori informazioni, clicca qui
È possibile scaricare libri? Se sì, come?
Al momento è possibile scaricare tramite l'app tutti i nostri libri ePub mobile-friendly. Anche la maggior parte dei nostri PDF è scaricabile e stiamo lavorando per rendere disponibile quanto prima il download di tutti gli altri file. Per maggiori informazioni, clicca qui
Che differenza c'è tra i piani?
Entrambi i piani ti danno accesso illimitato alla libreria e a tutte le funzionalità di Perlego. Le uniche differenze sono il prezzo e il periodo di abbonamento: con il piano annuale risparmierai circa il 30% rispetto a 12 rate con quello mensile.
Cos'è Perlego?
Perlego è un servizio di abbonamento a testi accademici, che ti permette di accedere a un'intera libreria online a un prezzo inferiore rispetto a quello che pagheresti per acquistare un singolo libro al mese. Con oltre 1 milione di testi suddivisi in più di 1.000 categorie, troverai sicuramente ciò che fa per te! Per maggiori informazioni, clicca qui.
Perlego supporta la sintesi vocale?
Cerca l'icona Sintesi vocale nel prossimo libro che leggerai per verificare se è possibile riprodurre l'audio. Questo strumento permette di leggere il testo a voce alta, evidenziandolo man mano che la lettura procede. Puoi aumentare o diminuire la velocità della sintesi vocale, oppure sospendere la riproduzione. Per maggiori informazioni, clicca qui.
Bioinformatics è disponibile online in formato PDF/ePub?
Sì, puoi accedere a Bioinformatics di Christine Orengo, David Jones, Janet Thornton, Christine Orengo, David Jones, Janet Thornton in formato PDF e/o ePub, così come ad altri libri molto apprezzati nelle sezioni relative a Sciences biologiques e Biotechnologie. Scopri oltre 1 milione di libri disponibili nel nostro catalogo.
Informazioni
1
Molecular evolution
Concepts
• Information is a measure of order that can be applied to any structure or system. It quantifies the instructions needed to produce a certain organization and can be expressed in bits. Large biomolecules have very high information content.
• The concept of the gene has undergone many changes. New concepts are emerging that define genes as functional units whose action is dependent on biological context.
• Multigene and multidomain families have arisen by gene duplication in genomes. Complete and partial gene duplication can occur by unequal crossing over, unequal sister chromatid exchange and transposition.
• Sequences or protein structures are homologous if they are related by evolutionary divergence from a common ancestor. Homology cannot be directly observed, but must be inferred from sequence or structural similarity.
1.1
Molecular evolution is a fundamental part of bioinformatics
Molecular evolution is a fundamental part of bioinformatics
Genomes are dynamic molecular entities that evolve over time due to the cumulative effects of mutation, recombination, and selection. Before we address bioinformatics techniques for analysis of evolutionary relationships between biological sequences, and between protein structures, in later chapters, we will first survey these mechanisms that form the basis of genome evolution.
1.1.1
A brief history of the gene
A brief history of the gene
The systematic study of the laws of heredity began with the work of Gregor Mendel (1822–1884). In 1865, Mendel who was an Augustinian monk living in Brno, then part of the Austro-Hungarian Empire, published a paper describing the results of plant-breeding experiments that he had begun in the gardens of his monastery almost a decade earlier. Mendel’s work received little attention during his lifetime, but when his paper was rediscovered by biologists in 1900, a scientific revolution ensued. The key concept of the Mendelian revolution is that heredity is mediated by discrete units that can combine and dissociate in mathematically predictable ways.
Mendel had studied physics and plant physiology at the University of Vienna, where he was also introduced to the new science of statistics. His experimental methods show the mental habits of a physicist, and in looking for mathematical patterns of inheritance, he became the first mathematical biologist. He set out to arrange in a statistically accurate way the results of deliberate crosses between varieties of sweet pea plants with characteristics that could be easily identified. His elegant experiments led to a clear distinction between genotype (the hereditary make-up of an organism) and phenotype (the organism’s physical and behavioral characteristics), and his results on the pattern of inheritance have become known as Mendel’s law.
Mendel was the first to refer to hypothetical ‘factors’ that act as discrete units of heredity and are responsible for particular phenotypic traits. The rediscovery of his work at the beginning of the 20th century prompted a search for the cellular and molecular basis of heredity. The existence of ‘germ plasm’ was postulated, a material substance in eggs and sperm that in some way carried heritable traits from parent to offspring. While the molecular basis of hereditary factors—protein versus nucleic acid—remained in dispute until the mid-20th century, their cellular basis in chromosomes was soon discovered. In 1909, W.Johannsen coined the word gene to denote hypothetical particles that are carried on chromosomes and mediate inheritance.
In sexually reproducing diploid organisms, such as Mendel’s pea plants and the fruit fly Drosophila melanogaster used in the breeding experiments of early Mendelians, the pattern of inheritance of some phenotypic traits could be explained by postulating a pair of genes underlying each trait—a pair of alleles occupying a locus on a chromosome. It was recognized early on that a single trait might be caused by several genes (polygenic traits) and that a single gene may have several effects (pleiotropy).
It is important to realize that ‘gene’ was an abstract concept to Mendel, and the Mendelian biologists of the first half of the 20th century. The founders of genetics, not having any knowledge of the biochemical basis of heredity, had to infer the characteristics of genes by observing the phenotypic outcomes of their breeding experiments. They developed a theoretical framework based on sound mathematics, now called classical genetics, that worked extremely well and is still useful today for the interpretation of the data obtained by the new molecular genetics.
Molecular genetics seeks to elucidate the chemical nature of the hereditary material and its cellular environment. At the beginning of the 1950s, it finally became clear that DNA was the critical ingredient of the genes. Rosalind Franklin (1920–1958), a crystallographer working at King’s College in London, conducted a careful analysis of DNA using X-ray diffraction which indicated that the macromolecule possessed a double-stranded helical geometry. In 1953, James Watson and Francis Crick produced a successful model of the molecular structure of DNA based on her data by employing the molecular-model building method pioneered by Linus Pauling (1901–1994).
It was clear as soon as the structure of DNA was elucidated that its central role depends on the fact that it can be both replicated and read. This has given rise to the concept of genetic information being encoded in DNA (see section 1.1.2). This idea is often expressed by metaphors that conceive of a gene as a ‘word’ and a genome, the total genetic material of a species, as a linguistic ‘text’ written in DNA code.
Over the ensuing five decades, rapidly accumulating knowledge on the fine structure of DNA and its functional organization has led to many critical adjustments and refinements in our understanding of the complex roles of genetic material in the cell. These discoveries all highlight the crucial contributions of the cellular environment in regulating the effects of DNA sequences on an organism’s phenotype. The causal chain between DNA and phenotype is indirect, different cellular environments link identical DNA sequences to quite different phenotypic outcomes. One of the outcomes of the Human Genome Project is a significantly expanded view of the role of the genome within the integrated functioning of cellular systems.
The concept of the gene has undergone a profound transformation in recent years (Figure 1.1). For molecular biology, the traditional definition of gene action, originating from George Beadle’s one gene-one enzyme hypothesis (1941) led to the concept of the gene as a stretch of DNA that codes for a single polypeptide chain. But even ignoring the fact that open reading frames might overlap, the relationship between DNA sequences and protein chains is many-to-many, not one-to-one. Now, the essential contributions of alternative splicing, RNA editing and post-translational modifications to the synthesis of the actual gene product have become recognized, and with them the limitations of the classic gene concept.
The gene as a unit of function can no longer be taken to be identical with the gene as a unit of intergenerational transmission of molecular information. New concepts are emerging that place emphasis on a functional perspective and define genes as ‘segments of DNA that function as functional units’, ‘loci of cotranscribed exons’ or, along similar lines, ‘distinct transcription units or parts of transcription units that can be translated to generate one or a set of related amino acid sequences’. Another less widely adopted, yet, from a functional perspective, valid definition has recently been proposed by Eva Neumann-Held which states that a gene ‘is a process that regularly results, at some stage in development, in the production of a particular protein.’ This process centrally involves a linear sequence of DNA, some parts of which correspond to the protein via the genetic code. However, the concept of gene-as-process could also include such entities as coding regions for transcription factors that bind to its regulatory sequences, coding regions for RNA editing and splicing factors, the regulatory dynamics of the cell as a whole and the signals determining the specific nature of the final transcript, and beyond that, the final protein product. In conclusion, diverse interpretations of the concept of the gene exist and the meaning in which the term is applied can only be made clear by careful definition. At the very least, inclusion or exclusion of introns, regulatory regions and promoters need to be made explicit when we speak of a gene from the perspective of molecular biology.
1.1.2
What is information?
What is information?
Biological, or genetic, information is a fundamental concept of bioinformatics. Yet what exactly is information? In physics, it is understood as a measure of order that can be applied to any structure or system. The term ‘information’ is derived from the Latin informare, which means to ‘form’, to ‘shape’, to ‘organize’. The word ‘order’ has its roots in textile weaving; it stems from the Latin ordiri, to ‘lay the warp’. Information theory, pioneered by Claude Shannon, is concerned with information as a universal measure that can be applied equally to the order contained in a hand of playing cards, a musical score, a DNA or protein sequence, or a galaxy.
Information quantifies the instructions needed to produce a certain organization. Several ways to achieve this can be envisaged, but a particularly parsimonious one is in terms of binary choices. Following this approach, we compute information inherent in any given arrangement of matter from the number of ‘yes’ and ‘no’ choices that must be made to arrive at a particular arrangement among all equally possible ones (Figure 1.2). In his book The Touchstone of Life (1999), Werner Loewenstein illustrates this with the following thought experiment. Suppose you are playing bridge and are dealt a hand of 13 cards. There are about 635×109 different hands of 13 cards that can occur in this case, so the probability that you would be dealt this hand of cards is about 1 in 635×109—a large number of choices would need to be made to produce this exact hand. In other words, a particular hand of 13 cards contains a large amount of information.
Order refers to the structural arrangement of a system, something that is easy to understand in the case of a warp for weaving cloth but is much harder to grasp in the case of macromolecular structures. We can often immediately see whether an everyday structure is orderly or disorderly—but this intuitive notion does not go beyond simple architectural or periodic features. The intuition breaks down when we deal with macromolecules, like DNA, RNA and proteins. The probability for spontaneous assembly of such molecules is extremely low, and their structural specifications require enormous amounts of information since the number of ways they can be assembled as linear array of their constituent building blocks, nucleotides and amino acids, is astronomical. Like being dealt a particular hand during a bridge game, the synthesis of a particular biological sequence is very unlikely—its information content is therefore very high.
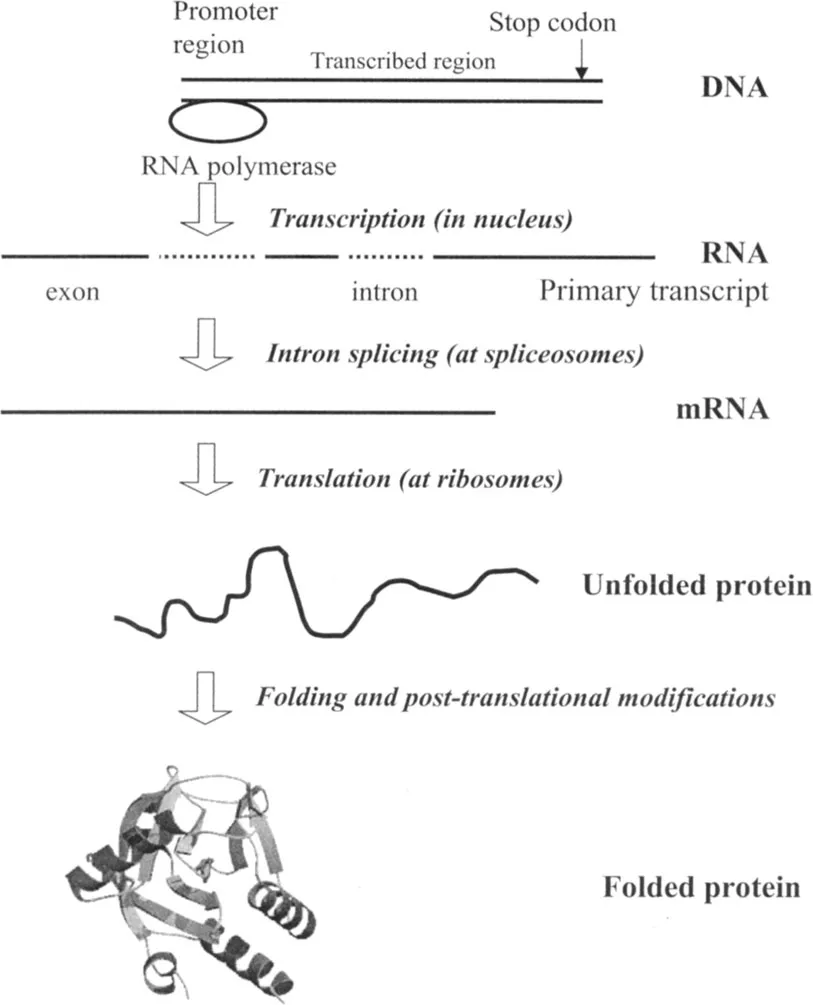
Figure 1.1
From gene to folded protein
The large molecules in living organisms offer the most striking example of information density in the universe. In human DNA, roughly 3 × 109 nucleotides are strung together on the scaffold of the phosphate backbone in an aperiodic, yet perfectly determined, sequence. Disregarding spontaneous somatic mutations, all the DNA molecules of an individual display the same sequence. We are not yet able to precisely calculate the information inherent in the human genome, but we can get an idea of its huge information storing capacity with a simple calculation. The positions along the linear DNA sequence, that can be occupied by one of the four types of DNA bases, represent the elements of stored information (Figure 1.2). So, with 3×109 positions and four possible choices for each position, there are 43,000,000,000 possible states. The number of possibilities is greater than the estimated number of particles in the universe.
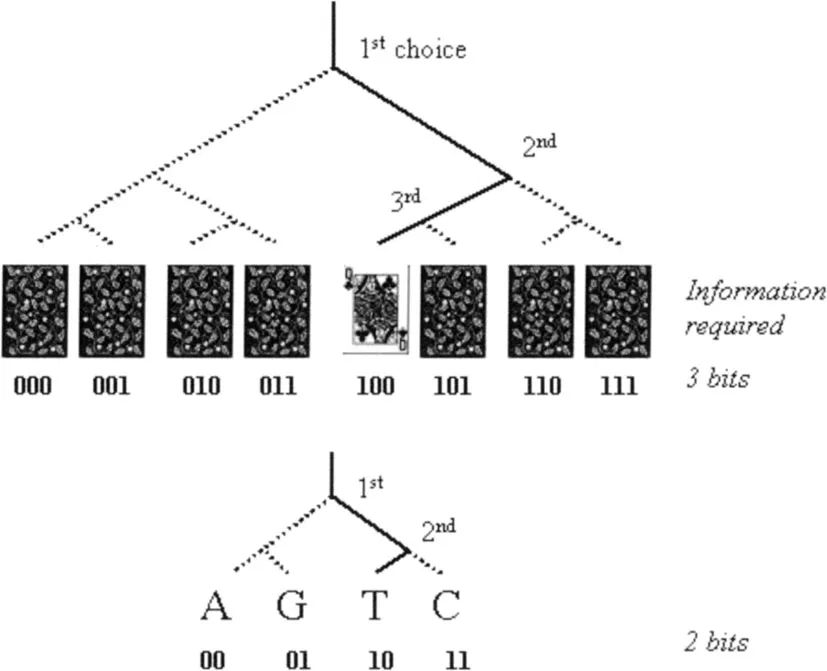
Figure 1.2
What is information? Picking a particular playing card from a pack of eight cards requires 3 yes/no choices (binary choices of 0 or 1). The information required can be quantified as ‘3 bits’. Likewise, picking one nucleotide among all four equally likely ones (A, G, T, C) requires 2 choices (2 bits).
Charles Darwin pointed out in Origin of Species how natural selection could gradually accumulate information about biological structures through the processes of random genotypic variation, natural selection and differential reproduction. What Darwin did not know was exactly how this information is stored, passed on to offspring and modified during evolution—this is the subject of the study of molecular evolution.
1.1.3
Molecular evolution
Molecular evolution
This section provides an overview of the processes giving rise to the dynamics of evolutionary change at the molecular level. It primarily focuses on biological mechanisms relevant to the evolution of genomic sequences encoding polypeptide chains.
1.1.3.1
The algorithmic nature of molecular evolution
The algorithmic nature of molecular evolution
In his theory of evolution, Darwin identified three major features of the process that occur in an endlessly repeating cycle: generation of heritable variation by random mutation at the level of the genotype, natural selection acting on the phenotype, and differential reproductive success. Darwin discovered the power of cumulative algorithmic selection, although he lacked the te...