Development of high-throughput technologies in molecular biology during the last two decades has contributed to the production of tremendous amounts of data. Microarray and RNA sequencing are two such widely used high-throughput technologies for simultaneously monitoring the expression patterns of thousands of genes. Data produced from such experiments are voluminous (both in dimensionality and numbers of instances) and evolving in nature. Analysis of huge amounts of data toward the identification of interesting patterns that are relevant for a given biological question requires high-performance computational infrastructure as well as efficient machine learning algorithms. Cross-communication of ideas between biologists and computer scientists remains a big challenge.
Gene Expression Data Analysis: A Statistical and Machine Learning Perspective has been written with a multidisciplinary audience in mind. The book discusses gene expression data analysis from molecular biology, machine learning, and statistical perspectives. Readers will be able to acquire both theoretical and practical knowledge of methods for identifying novel patterns of high biological significance. To measure the effectiveness of such algorithms, we discuss statistical and biological performance metrics that can be used in real life or in a simulated environment. This book discusses a large number of benchmark algorithms, tools, systems, and repositories that are commonly used in analyzing gene expression data and validating results. This book will benefit students, researchers, and practitioners in biology, medicine, and computer science by enabling them to acquire in-depth knowledge in statistical and machine-learning-based methods for analyzing gene expression data.
Key Features:
An introduction to the Central Dogma of molecular biology and information flow in biological systems
A systematic overview of the methods for generating gene expression data
Background knowledge on statistical modeling and machine learning techniques
Detailed methodology of analyzing gene expression data with an example case study
Clustering methods for finding co-expression patterns from microarray, bulkRNA, and scRNA data
A large number of practical tools, systems, and repositories that are useful for computational biologists to create, analyze, and validate biologically relevant gene expression patterns
Suitable for multidisciplinary researchers and practitioners in computer science and biological sciences
Domande frequenti
Come faccio ad annullare l'abbonamento?
È semplicissimo: basta accedere alla sezione Account nelle Impostazioni e cliccare su "Annulla abbonamento". Dopo la cancellazione, l'abbonamento rimarrà attivo per il periodo rimanente già pagato. Per maggiori informazioni, clicca qui
È possibile scaricare libri? Se sì, come?
Al momento è possibile scaricare tramite l'app tutti i nostri libri ePub mobile-friendly. Anche la maggior parte dei nostri PDF è scaricabile e stiamo lavorando per rendere disponibile quanto prima il download di tutti gli altri file. Per maggiori informazioni, clicca qui
Che differenza c'è tra i piani?
Entrambi i piani ti danno accesso illimitato alla libreria e a tutte le funzionalità di Perlego. Le uniche differenze sono il prezzo e il periodo di abbonamento: con il piano annuale risparmierai circa il 30% rispetto a 12 rate con quello mensile.
Cos'è Perlego?
Perlego è un servizio di abbonamento a testi accademici, che ti permette di accedere a un'intera libreria online a un prezzo inferiore rispetto a quello che pagheresti per acquistare un singolo libro al mese. Con oltre 1 milione di testi suddivisi in più di 1.000 categorie, troverai sicuramente ciò che fa per te! Per maggiori informazioni, clicca qui.
Perlego supporta la sintesi vocale?
Cerca l'icona Sintesi vocale nel prossimo libro che leggerai per verificare se è possibile riprodurre l'audio. Questo strumento permette di leggere il testo a voce alta, evidenziandolo man mano che la lettura procede. Puoi aumentare o diminuire la velocità della sintesi vocale, oppure sospendere la riproduzione. Per maggiori informazioni, clicca qui.
Gene Expression Data Analysis è disponibile online in formato PDF/ePub?
Sì, puoi accedere a Gene Expression Data Analysis di Pankaj Barah, Dhruba Kumar Bhattacharyya, Jugal Kumar Kalita in formato PDF e/o ePub, così come ad altri libri molto apprezzati nelle sezioni relative a Computer Science e Computer Science General. Scopri oltre 1 milione di libri disponibili nel nostro catalogo.
An exciting area of significant scientific and technological innovation of recent times is bioinformaticsThe science of collecting and analysing complex biological data. The field integrates diverse disciplines, including computer science and informatics, biology, statistics, applied mathematics and artificial intelligence to provide solutions to crucial biological problems at the molecular level. With the help of machine learning techniques and statistical methods, it has become possible to organize, analyze and interpret voluminous biological data with an eye to uncovering interesting patterns of great consequence. One major area within bioinformatics is analysis of geneBasic physical and functional unit of heredity expression data of disparate kinds such as microarrays, gene ontologies, protein-protein interactions and various flavors of genomeAll the genetic material of an organism sequence data or combinations. The genome provides only static information whereas gene expressionExpression of a gene into its functional products data analysis produced from the microarray and sequencing technologies provide dynamic information about cellBasic structural and functional unit of an organism function. The measurement of the activity (expression) of thousands of genes at once so as to create a global picture of cellular function is known as gene expression profiling. Analysis and interpretation of such gene expression data using appropriate machine learning or statistical methods can help extract intrinsic patterns or knowledge, which may be of use towards uncovering causes of critical diseases.
Bio-medical science has been battling against many deadly diseases including cancer for many years, and grand successes have been promised but have been limited, in general. The number of humans affected by such deadly diseases is increasing day by day. Early detection and treatment using modern medical technology has been beneficial in combating the scourge of such diseases and increasing survival rates. Machine learning is an exciting area of research and practice, which has been applied successfully in bioinformatics to uncover many interesting, yet previously unknown patterns towards identification of biomarker genes for such critical diseases.
1.2 Central Dogma
Genes are the primary factors that control traits of various characteristics in an organism. These characteristics may be associated with certain diseases or normal development processes. There are two major phases associated with the pathways through which genes control characteristics of an organism. In the first phase, genetic codeThe sequence of nucleotides in deoxyribonucleic acid (DNA) and ribonucleic acid (RNA) that determines the amino acid sequence of proteins is transferred from genes to proteinsLarge biomolecules, or macromolecules, that are an essential part of living organisms, especially as structural components of body tissues through a phenomenon called the Central DogmaThe scientific concept of a gene being transcripted to an mRNA which is in turn translated to protein.
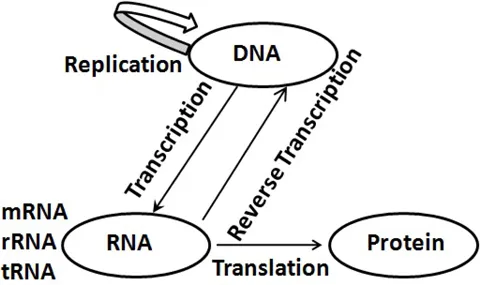
The Central Dogma of Molecular Biology describes the formation of a protein molecule inside a living organism, as shown in Figure 1.1. The double-stranded DNAA coiled double helix molecule composed of two polynucleotide chains that carry genetic instructions molecule is partially unzipped and an enzymeProteins that act as biological catalysts in living organisms called RNAHigh-molecular-weight compound involved in cellular protein synthesis that replaces DNA as a carrier of genetic codes in some viruses polymerase copies the gene's nucleotidesOrganic molecule of a nucleoside and phosphate that act as monomers of nucleic acid polymers one by one into an RNA molecule, called the messenger RNA or mRNAMessenger RNA is a single-stranded molecule of RNA that consists of the sequence of a gene. This process is called transcription. The mRNA is a small, single-stranded sequence of nucleotides which moves out of the nucleusThe cell organelle where DNA replication and transcription takes place. Outside the nucleus, another set of proteins reads the sequence of the mRNA and gathers free floating amino acids to fuse them into a chain. The nucleotide sequence of the mRNA determines the order in which an amino acid is incorporated into the growing protein. The process of translating the mRNA sequence into a protein sequence is called translation.
Figure1.1:Central Dogma: An illustration.
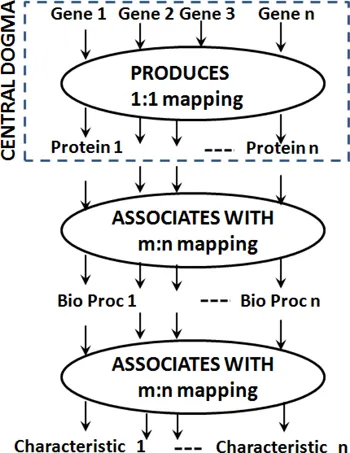
The Central Dogma explains the biological process that results in the flow of genetic information into proteins from the information encoded in nucleotide sequences of DNA segments or genes. A protein is a biological macromolecule associated with almost all biological processes, typically governing the traits of various phenotypicExpression of genes in an observable and measurable way and non-phenotypic characteristics in an organism. Hence, as shown in Figure 1.2, genes are the keys that drive protein structure and all biological processes, and thus traits of various characteristics in an organism.
Figure1.2:Flow of control from genes to traits in an organism.
1.3 Measuring Gene Expression
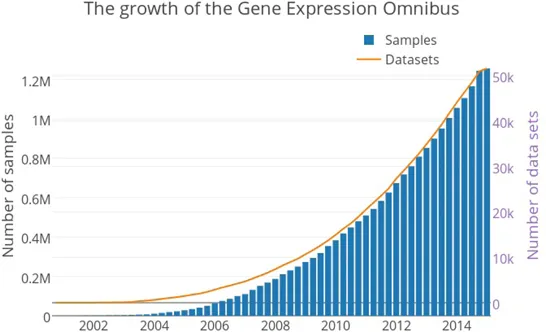
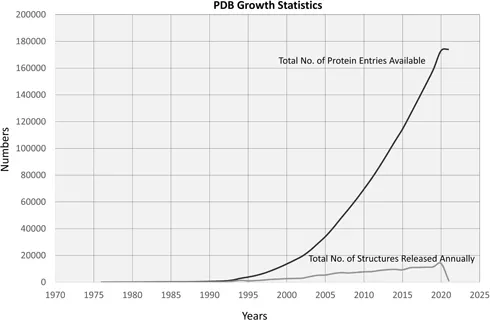
The magnitude of expression of a gene depends on a number of factors, including inter-gene regulatory relationships. The expression level of a gene is a major determinant of the presence of the corresponding governed characteristics in an organism. A number of technologies developed, including revolutionary microarray and sequencing technologies, help determine the expression levels of thousands of genes in a single experiment. Gene expression data generated by these technologies provide an ample resource from which useful biological knowledge can be extracted. Computational analysis of such data can be of great use to biologists. Figure 1.3 shows the exponential growth in the quantity of gene expression data collected over a period of ten years 1. Figure 1.4 is another example, showing the growth of protein data over a period of ten years 2.
Figure1.3:Growth statistics of gene expression data.
Figure1.4:Growth statistics of protein data.
Using appropriate microarray or sequencing technology, it is possible to simultaneously examine the expression levels of thousands of genes across developmental stages, clinical conditions or time points. The real-valued gene expression data are obtained in the form of a matrix where the rows refer to the genes and the columns represent the conditions, stages or time points. Genes, which are the primary repository of biological information, help the growth and maintenance of an organism's cells. Required activities include construction and regulation of proteins as well as other molecules that determine the growth and functioning of the living organism, and ultimately to the transfer of genetic traits to the next generation.
RNA-Seq is a recent and a robust sequencing technology to measure the expression levels of nucleotide sequences corresponding to genes [147]. Determination of how nucleotides are strung together in a DNA molecule is called DNA sequencing. The term next-generation sequencing refers to a number of modern advanced high-throughput DNA sequencing techniques [293]. Pyrosequencing [14], DNA colony sequencing [216], massively parallel signature sequencing [68], illumina sequencing [418], DNA nanoball160,000 to 200,000-bp-long single-stranded replicated DNA fragments made of the original library DNA molecules sequencing [444], and heliscope-single-molecule sequencing [334] are some examples of this family of techniques. In RNA-Seq technology, mRNA molecules are sequenced to short nucleotide base sequences. These sequences are then aligned with known nucleotide sequences corresponding to genes to determine expression levels of the genes.
1.4 Representation of Gene Expression Data
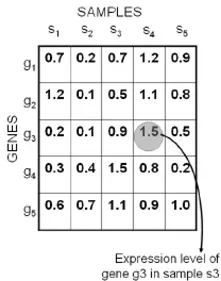
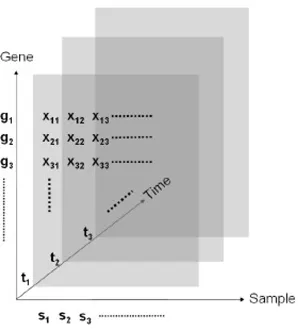
The widespread use of the technologies mentioned above has led to generation of an enormous amount of gene expression data that are witnesses to numerous biological phenomena in living organisms. Various types of gene expression data correspond to how measurements are carried out and represented. If expression levels of genes are detected in multiple samples collected from different organisms, a two-dimensional gene expression dataset is produced where rows correspond to genes and columns correspond to samples or vice versa [329]. Certain expression datasets store expression levels of genes in one or more samples at various time points. Such specialized gene expression data are called time-series gene expression data [270]. A special form of time series gene expression data contains expression levels of multiple samples at multiple time points to form a three-dimensional structure. Such data are called gene sample time (GST) expression data [269]. Figure 1.5 presents the structure of a two-dimensional gene expression dataset, whereas three-dimensional GST expression is shown in Figure 1.6. There are numerous online repositories that store and maintain ever-growing gene expression datasets. ArrayTrackA tool for managing, analyzing and interpreting microarray gene expression data. It was created by Dr. Weida Tong, director of the Division of Biostatistics and Bioinformatics, FDA (USA) [407], ArrayExpressOne of the major public repositories for functional genomic datasets at EBI and Gene Expression Omnibus-NCBI [66] are three very widely used repositories of gene expression data.
Figure1.5:2-D gene expression data.
Figure1.6:3-D gene expression data.
_________________________
1http://www.ncbi.nlm.nih.gov/geo/
2http://www.rcsb.org/
1.5 Gene Expression Data Analysis: Applications
Gene expression data witness biological phenomena taking place in an organism and hence, they represent a raw resource from which ample biological knowledge can potentially be unearthed. Proper analysis of such data extracts information about underlying biological phenomena. Some problems that can be addressed by gene expression data analysis are briefly discussed below.