
Cloud-Native Applications in Java
Ajay Mahajan, Munish Kumar Gupta, Shyam Sundar
- English
- ePUB (disponibile sull'app)
- Disponibile su iOS e Android
Cloud-Native Applications in Java
Ajay Mahajan, Munish Kumar Gupta, Shyam Sundar
Informazioni sul libro
Highly available microservice-based web apps for Cloud with JavaAbout This Book• Take advantage of the simplicity of Spring to build a full-fledged application• Let your applications run faster while generating smaller cloud service bills• Integrate your application with various tools such as Docker and ElasticSearch and use specific tools in Azure and AWSWho This Book Is ForJava developers who want to build secure, resilient, robust and scalable applications that are targeted for cloud based deployment, will find this book helpful. Some knowledge of Java, Spring, web programming and public cloud providers (AWS, Azure) should be sufficient to get you through the book.What You Will Learn• See the benefits of the cloud environment when it comes to variability, provisioning, and tooling support• Understand the architecture patterns and considerations when developing on the cloud• Find out how to perform cloud-native techniques/patterns for request routing, RESTful service creation, Event Sourcing, and more• Create Docker containers for microservices and set up continuous integration using Jenkins• Monitor and troubleshoot an application deployed in the cloud environment• Explore tools such as Docker and Kubernetes for containerization and the ELK stack for log aggregation and visualization• Use AWS and Azure specific tools to design, develop, deploy, and manage applications• Migrate from monolithic architectures to a cloud native deploymentIn DetailBusinesses today are evolving so rapidly that they are resorting to the elasticity of the cloud to provide a platform to build and deploy their highly scalable applications. This means developers now are faced with the challenge of building build applications that are native to the cloud. For this, they need to be aware of the environment, tools, and resources they're coding against.If you're a Java developer who wants to build secure, resilient, robust, and scalable applications that are targeted for cloud-based deployment, this is the book for you. It will be your one stop guide to building cloud-native applications in Java Spring that are hosted in On-prem or cloud providers - AWS and AzureThe book begins by explaining the driving factors for cloud adoption and shows you how cloud deployment is different from regular application deployment on a standard data centre. You will learn about design patterns specific to applications running in the cloud and find out how you can build a microservice in Java Spring using REST APIsYou will then take a deep dive into the lifecycle of building, testing, and deploying applications with maximum automation to reduce the deployment cycle time. Gradually, you will move on to configuring the AWS and Azure platforms and working with their APIs to deploy your application. Finally, you'll take a look at API design concerns and their best practices. You'll also learn how to migrate an existing monolithic application into distributed cloud native applications.By the end, you will understand how to build and monitor a scalable, resilient, and robust cloud native application that is always available and fault tolerant.Style and approachFilled with examples, this book will build you an entire cloud-native application through its course and will stop at each point and explain in depth the functioning and design considerations that will make a robust, highly available application
Domande frequenti
Informazioni
Extending Your Cloud-Native Application
- Accessing data: Service access to data across various resources
- Caching: Options to do caching and their considerations
- Applying CQRS: Enable us to have different data models to service different requests
- Error handling: How to recover, what return codes to send, and implementation of patterns such as a circuit breaker
- Validations: Ensuring that the data is clean before being processed
- Keeping two models of CQRS in sync: For data consistency
- Event driven and asynchronous updates: How it scales the architecture and decouples it at the same time
Implementing the get services
- You would store a product in a product table with a fixed number of columns.
- You would then index the category so that the queries against it can run quickly.
Simple product table
- Maven POM: Including POM dependencies:
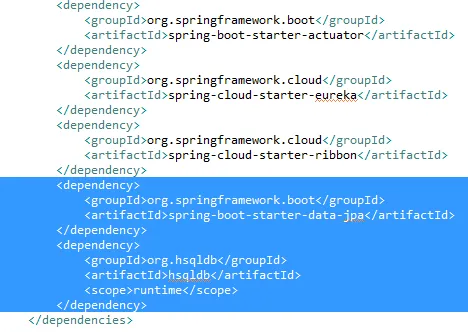
- Entity: As per the JPA, we will start using the concept of entity. We already have a domain object named Product from our previous project. Refactor it to put in an entity package. Then, add the notations of @Entity, @Id, and @Column, as shown in the following Product.java file:
package com.mycompany.product.entity ; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; @Entity public class Product { @Id @GeneratedValue(strategy=GenerationType.AUTO) private int id ; @Column(nullable = false) private String name ; @Column(nullable = false) private int catId ; - Repository: Spring Data provides a repository, which is like a DAO class and provides methods to do Create, Read, Update, and Delete (CRUD) operations on the data. A lot of standard operations are already provided in the CrudRepository interface. We will be using only the query operations from now on.
In our case, since our domain entity is Product, the repository will be ProductRepository, which extends Spring's CrudRepository, and manages the Product entity. During extension, the entity and the data type of the primary key needs to be specified using generics, as shown in the following ProductRepository.java file:
package com.mycompany.product.dao; import java.util.List; import org.springframework.data.repository.CrudRepository; import com.mycompany.product.entity.Product; public interface ProductRepository extends CrudRepository<Product, Integer> { List<Product> findByCatId(int catId); } - Changing the service: In Chapter 2, Writing Your First Cloud-Native Application, our product service was returning dummy hard-coded data. Let's change it to something useful that goes against the database. We achieve this by using the ProductRepository interface that we defined earlier, and injecting it through @Autowiring annotation into our ProductService class, as shown in the following ProductService.java file:
@RestController public class ProductService { @Autowired ProductRepository prodRepo ; @RequestMapping("/product/{id}") Product getProduct(@PathVariable("id") int id) { return prodRepo.findOne(id); } @RequestMapping("/products") List<Product> getProductsForCategory(@RequestParam("id") int id) { return prodRepo.findByCatId(id); } } - Schema definition: For now, we will leave the schema creation to the hibernate capability to auto generate a script. Since we do want to see what script got created, let's enable logging for the classes as follows in the application.properties file:
logging.level.org.hibernate.tool.hbm2ddl=DEBUG logging.level.org.hibernate.SQL=DEBUG
- ...