Benoy Antony, Konstantin Boudnik, Cheryl Adams, Branky Shao, Cazen Lee, Kai Sasaki
This is a test
This is a test
Condividi libro
English
ePUB (disponibile sull'app)
Disponibile su iOS e Android
eBook - ePub
Professional Hadoop
Benoy Antony, Konstantin Boudnik, Cheryl Adams, Branky Shao, Cazen Lee, Kai Sasaki
Dettagli del libro
Anteprima del libro
Indice dei contenuti
Citazioni
Informazioni sul libro
The professional's one-stop guide to this open-source, Java-based big data framework
Professional Hadoop is the complete reference and resource for experienced developers looking to employ Apache Hadoop in real-world settings. Written by an expert team of certified Hadoop developers, committers, and Summit speakers, this book details every key aspect of Hadoop technology to enable optimal processing of large data sets. Designed expressly for the professional developer, this book skips over the basics of database development to get you acquainted with the framework's processes and capabilities right away. The discussion covers each key Hadoop component individually, culminating in a sample application that brings all of the pieces together to illustrate the cooperation and interplay that make Hadoop a major big data solution. Coverage includes everything from storage and security to computing and user experience, with expert guidance on integrating other software and more.
Hadoop is quickly reaching significant market usage, and more and more developers are being called upon to develop big data solutions using the Hadoop framework. This book covers the process from beginning to end, providing a crash course for professionals needing to learn and apply Hadoop quickly.
Configure storage, UE, and in-memory computing
Integrate Hadoop with other programs including Kafka and Storm
Master the fundamentals of Apache Big Top and Ignite
Build robust data security with expert tips and advice
Hadoop's popularity is largely due to its accessibility. Open-source and written in Java, the framework offers almost no barrier to entry for experienced database developers already familiar with the skills and requirements real-world programming entails. Professional Hadoop gives you the practical information and framework-specific skills you need quickly.
Domande frequenti
Come faccio ad annullare l'abbonamento?
È semplicissimo: basta accedere alla sezione Account nelle Impostazioni e cliccare su "Annulla abbonamento". Dopo la cancellazione, l'abbonamento rimarrà attivo per il periodo rimanente già pagato. Per maggiori informazioni, clicca qui
È possibile scaricare libri? Se sì, come?
Al momento è possibile scaricare tramite l'app tutti i nostri libri ePub mobile-friendly. Anche la maggior parte dei nostri PDF è scaricabile e stiamo lavorando per rendere disponibile quanto prima il download di tutti gli altri file. Per maggiori informazioni, clicca qui
Che differenza c'è tra i piani?
Entrambi i piani ti danno accesso illimitato alla libreria e a tutte le funzionalità di Perlego. Le uniche differenze sono il prezzo e il periodo di abbonamento: con il piano annuale risparmierai circa il 30% rispetto a 12 rate con quello mensile.
Cos'è Perlego?
Perlego è un servizio di abbonamento a testi accademici, che ti permette di accedere a un'intera libreria online a un prezzo inferiore rispetto a quello che pagheresti per acquistare un singolo libro al mese. Con oltre 1 milione di testi suddivisi in più di 1.000 categorie, troverai sicuramente ciò che fa per te! Per maggiori informazioni, clicca qui.
Perlego supporta la sintesi vocale?
Cerca l'icona Sintesi vocale nel prossimo libro che leggerai per verificare se è possibile riprodurre l'audio. Questo strumento permette di leggere il testo a voce alta, evidenziandolo man mano che la lettura procede. Puoi aumentare o diminuire la velocità della sintesi vocale, oppure sospendere la riproduzione. Per maggiori informazioni, clicca qui.
Professional Hadoop è disponibile online in formato PDF/ePub?
Sì, puoi accedere a Professional Hadoop di Benoy Antony, Konstantin Boudnik, Cheryl Adams, Branky Shao, Cazen Lee, Kai Sasaki in formato PDF e/o ePub, così come ad altri libri molto apprezzati nelle sezioni relative a Computer Science e Databases. Scopri oltre 1 milione di libri disponibili nel nostro catalogo.
The roles of HDFS, MapReduce, YARN, ZooKeeper, and Hive
Hadoop's integration with other systems
Data integration and Hadoop
Hadoop is an essential tool for managing big data. This tool fills a rising need for businesses managing large data stores, or data lakes as Hadoop refers to them. The biggest need in business, when it comes to data, is the ability to scale. Technology and business are driving organizations to gather more and more data, which increases the need to manage it efficiently. This chapter examines the Hadoop Stack, as well as all of the associated components that can be used with Hadoop.
In building the Hadoop Stack, each component plays an important role in the platform. The stack starts with the essential requirements contained in the Hadoop Common, which is a collection of common utilities and libraries that support other Hadoop modules. Like any stack, these supportive files are a necessary requirement for a successful implementation. The well-known file system, the Hadoop Distributed File System or HDFS, is at the heart of Hadoop, but it won't threaten your budget. To narrow your perspective on a set of data, you can use the programming logic contained within MapReduce, which provides massive scalability across many servers in a Hadoop cluster. For resource management, you can consider adding Hadoop YARN, the distributed operating system for your big data apps, to your stack.
ZooKeeper, another Hadoop Stack component, enables distributed processes to coordinate with each other through a shared hierarchical name space of data registers, known as znodes. Every znode is identified by a path, with path elements separated by a slash (/).
There are other systems that can integrate with Hadoop and benefit from its infrastructure. Although Hadoop is not considered a Relational Database Management System (RDBMS), it can be used along with systems like Oracle, MySQL, and SQL Server. Each of these systems has developed connector-type components that are processed using Hadoop's framework. We will review a few of these components in this chapter and illustrate how they interact with Hadoop.
Business Analytics and Big Data
Business Analytics is the study of data through statistical and operational analysis. Hadoop allows you to conduct operational analysis on its data stores. These results allow organizations and companies to make better business decisions that are beneficial to the organization.
To understand this further, let's build a big data profile. Because of the amount of data involved, the data can be distributed across storage and compute nodes, which benefits from using Hadoop. Because it is distributed and not centralized, it lacks the characteristics of an RDBMS. This allows you to use large data stores and an assortment of data types with Hadoop.
For example, let's consider a large data store like Google, Bing, or Twitter. All of these data stores can grow exponentially based on activity, such as queries and a large user base. Hadoop's components can help you process these large data stores.
A business, such as Google, can use Hadoop to manipulate, manage, and produce meaningful results from their data stores. The traditional tools commonly used for Business Analytics are not designed to work with or analyze extremely large datasets, but Hadoop is a solution that fits these business models.
The Components of Hadoop
The Hadoop Common is the foundation of Hadoop, because it contains the primary services and basic processes, such as the abstraction of the underlying operating system and its filesystem. Hadoop Common also contains the necessary Java Archive (JAR) files and scripts required to start Hadoop. The Hadoop Common package even provides source code and documentation, as well as a contribution section. You can't run Hadoop without Hadoop Common.
As with any stack, there are requirements that Apache provides for configuring the Hadoop Common. Having a general understanding as a Linux or Unix administrator is helpful in setting this up. Hadoop Common, also referred to as the Hadoop Stack, is not designed for a beginner, so the pace of your implementation rests on your experience. In fact, Apache clearly states on their site that using Hadoop is not the task you want to tackle while trying to learn how to administer a Linux environment. It is recommended that you are comfortable in this environment before attempting to install Hadoop.
The Distributed File System (HDFS)
With Hadoop Common now installed, it is time to examine the rest of the Hadoop Stack. HDFS delivers a distributed filesystem that is designed to run on basic hardware components. Most businesses find these minimal system requirements appealing. This environment can be set up in a Virtual Machine (VM) or a laptop for the initial walkthrough and advancement to server deployment. It is highly fault-tolerant and is designed to be deployed on low-cost hardware. It provides high throughput access to application data and is suitable for applications having large datasets.
Hardware failures are unavoidable in any environment. With HDFS, your data can span across thousands of servers, with each server containing an essential piece of data. This is where the fault tolerance feature comes into play. The reality is that with this many servers there is always the risk that one or more may become nonfunctional. HDFS has the ability to detect faults and quickly perform an automatic recovery.
HDFS is optimally designed for batch processing, which provides a high throughput of data access, rather than a low latency of data access. Applications that run on HDFS have large datasets. A typical file in HDFS can be hundreds of gigabytes or more in size, and so HDFS of course supports large files. It provides high aggregate data bandwidth and scales to hundreds of nodes in a single cluster.
Hadoop is a single functional distributed system that works directly with clustered machines in order to read the dataset in parallel and provide a much higher throughput. Consider Hadoop as a power house single CPU running across clustered and low cost machines. Now that we've described the tools that read the data, the next step is to process it by using MapReduce.
What Is MapReduce?
MapReduce is a programming component of Hadoop used for processing and reading large data sets. The MapReduce algorithm gives Hadoop the ability to process data in parallel. In short, MapReduce is used to compress large amounts of data into meaningful results for statistical analysis. MapReduce can do batch job processing, which is the ability to read large amounts of data numerous times during processing to produce the requested results.
For businesses and organizations with large data stores or data lakes, this is an essential component in getting your data down to a manageable size to analyze or query.
The MapReduce workflow, as shown in Figure 1.1, works like a grandfather clock with a number of gears. Each gear performs a particular task before it moves on to the next. It shows the transitional states of data as it is chunked into smaller sizes for processing.
FIGURE 1-1
The capabilities of MapReduce make it one of the most used batch-processing tools. The flexibility of this processor opens the door to use its leverage against existing systems. MapReduce will allow its users to process unlimited amounts of data of any type that's stored in HDFS by dividing workloads into multiple tasks across servers that are run in parallel. MapReduce thus makes Hadoop a powerhouse tool.
With the recent developments in Hadoop, another component, called YARN, is now available that can be used to further leverage your Hadoop Ecosystem.
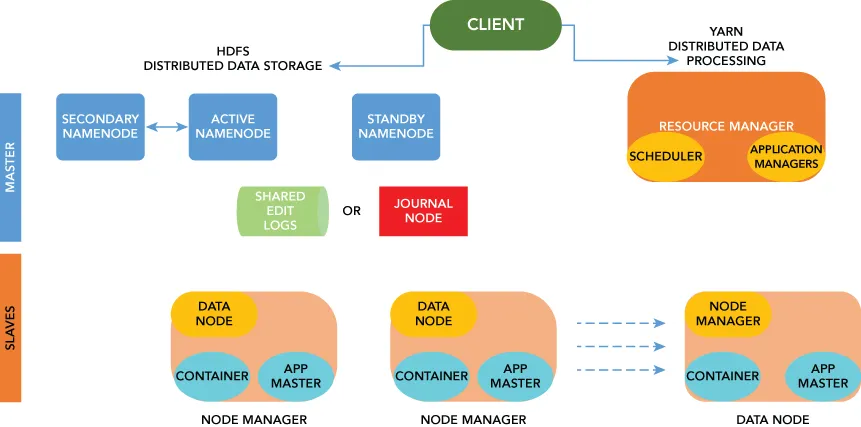
What Is YARN?
The YARN Infrastructure (Yet Another Resource Negotiator) is the framework responsible for pr...