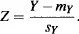![]()
CHAPTER 1
FOUNDATIONS
This chapter provides a brief refresher of the main statistical ideas that will be a useful foundation for the main focus of this book, regression analysis, covered in subsequent chapters. For more detailed discussion of this material, consult a good introductory statistics textbook such as Freedman et al. (2007) or Moore et al. (2011). To simplify matters at this stage, we consider univariate data, that is, datasets consisting of measurements of just a single variable on a sample of observations. By contrast, regression analysis concerns multivariate data where there are two or more variables measured on a sample of observations. Nevertheless, the statistical ideas for univariate data carry over readily to this more complex situation, so it helps to start as simply as possible and make things more complicated only as needed.
1.1 IDENTIFYING AND SUMMARIZING DATA
One way to think about statistics is as a collection of methods for using data to understand a problem quantitatively—we saw many examples of this in the introduction. This book is concerned primarily with analyzing data to obtain information that can be used to help make decisions in real-world contexts.
The process of framing a problem in such a way that it will be amenable to quantitative analysis is clearly an important step in the decision-making process, but this lies outside the scope of this book. Similarly, while data collection is also a necessary task—often the most time-consuming part of any analysis—we assume from this point on that we have already obtained some data relevant to the problem at hand. We will return to the issue of the manner in which these data have been collected—namely, whether the sample data can be considered to be representative of some larger population that we wish to make statistical inferences for—in Section 1.3.
For now, we consider identifying and summarizing the data at hand. For example, suppose that we have moved to a new city and wish to buy a home. In deciding on a suitable home, we would probably consider a variety of factors, such as size, location, amenities, and price. For the sake of illustration we focus on price and, in particular, see if we can understand the way in which sale prices vary in a specific housing market. This example will run through the rest of the chapter, and, while no one would probably ever obsess over this problem to this degree in real life, it provides a useful, intuitive application for the statistical ideas that we use in the rest of the book in more complex problems.
For this example, identifying the data is straightforward: the units of observation are a random sample of size n = 30 single-family homes in our particular housing market, and we have a single measurement for each observation, the sale price in thousands of dollars ($), represented using the notation Y = Price. Here, Y is the generic letter used for any univariate data variable, while Price is the specific variable name for this dataset. These data, obtained from Victoria Whitman, a realtor in Eugene, Oregon, are available in the HOMES1 data file—they represent sale prices of 30 homes in south Eugene during 2005. This represents a subset of a larger file containing more extensive information on 76 homes, which is analyzed as a case study in Section 6.1.
The particular sample in the HOMES1 data file is random because the 30 homes have been selected randomly somehow from the population of all single-family homes in this housing market. For example, consider a list of homes currently for sale, which are considered to be representative of this population. A random number generator—commonly available in spreadsheet or statistical software—can be used to pick out 30 of these. Alternative selection methods may or may not lead to a random sample. For example, picking the first 30 homes on the list would not lead to a random sample if the list were ordered by the size of the sale price.
We can simply list small datasets such as this. The values of Price in this case are:
However, even for these data, it can be helpful to summarize the numbers with a small number of sample statistics (such as the sample mean and standard deviation), or with a graph that can effectively convey the manner in which the numbers vary. A particularly effective graph is a stem-and-leaf plot, which places the numbers along the vertical axis of the plot, with numbers that are close together in magnitude next to one another on the plot. For example, a stem-and-leaf plot for the 30 sample prices looks like the following:
In this plot, the decimal point is two digits to the right of the stem. So, the “1” in the stem and the “6” in the leaf represents 160, or, because of rounding, any number between 155 and 164.9. In particular, it represents the lowest price in the dataset of 155.5 (thousand dollars). The next part of the graph shows two prices between 195 and 204.9, two prices between 205 and 214.9, one price between 225 and 234.9, two prices between 235 and 244.9, and so on. A stem-and-leaf plot can easily be constructed by hand for small datasets such as this, or it can be constructed automatically using statistical software. The appearance of the plot can depend on the type of statistical software used—this particular plot was constructed using R statistical software (as are all the plots in this book). Instructions for constructing stem-and-leaf plots are available as computer help #13 in the software information files available from the book website at www.iainpaxdoe.com/arm2e/software.htm.
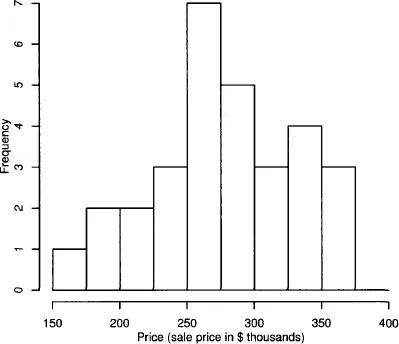
The overall impression from this graph is that the sample prices range from the mid-150s to the mid-350s, with some suggestion of clustering around the high 200s. Perhaps the sample represents quite a range of moderately priced homes, but with no very cheap or very expensive homes. This type of observation often arises throughout a data analysis—the data begin to tell a story and suggest possible explanations. A good analysis is usually not the end of the story since it will frequently lead to other analyses and investigations. For example, in this case, we might surmise that we would probably be unlikely to find a home priced at much less than $150,000 in this market, but perhaps a realtor might know of a nearby market with more affordable housing.
A few modifications to a stem-and-leaf plot produce a histogram—the value axis is now horizontal rather than vertical, and the counts of observations within adjoining data intervals (called “bins”) are displayed in bars (with the counts, or frequency, shown on the vertical axis) rather than by displaying individual values with digits. Figure 1.1 shows a histogram for the home prices data generated by statistical software (see computer help #14).
Histograms can convey very different impressions depending on the bin width, start point, and so on. Ideally, we want a large enough bin size to avoid excessive sampling “noise” (a histogram with many bins that looks very wiggly), but not so large that it is hard to see the underlying distribution (a histogram with few bins that looks too blocky). A reasonable pragmatic approach is to use the default settings in whichever software package we are using, and then perhaps to create a few more histograms with different settings to check that we’re not missing anything. There are more sophisticated methods, but for the purposes of the methods in this book, this should suffice.
In addition to graphical summaries such as the stem-and-leaf plot and histogram, sample statistics can summarize data numerically. For example:
- The sample mean, mY, is a measure of the “central tendency” of the data Y-values.
- The sample standard deviation, sy, is a measure of the spread or variation in the data Y-values.
We won’t bother here with the formulas for these sample statistics. Since almost all of the calculations necessary for learning the material covered by this book will be performed by statistical software, the book only contains formulas when they are helpful in understanding a particular concept or provide additional insight to interested readers.
We can calculate sample standardized Z-values from the data Y-values:
Sometimes, it is useful to work with sample standardized Z-values rather than the original data Y-values since sample standardized Z-values have a sample mean of 0 and a sample standard deviation of 1. Try using statistical software to calculate sample standardized Z-values for the home prices data, and then check that the mean and standard deviation of the Z-values are 0 and 1, respectively.
Statistical software can also calculate additional sample statistics, such as:
- the median (another measure of central tendency, but which is less sensitive than the sample mean to very small or very large values in the data)—half the dataset values are smaller than this quantity and half are larger;
- the minimum and maximum;
- percentiles or quantiles such as the 25th percentile—this is the smallest value that i...