![]()
1
Low Power Multicore Processors for Embedded Systems
FUMIO ARAKAWA
1.1 MULTICORE CHIP WITH HIGHLY EFFICIENT CORES
A multicore chip is one of the most promising approaches to achieve high performance. Formerly, frequency scaling was the best approach. However, the scaling has hit the power wall, and frequency enhancement is slowing down. Further, the performance of a single processor core is proportional to the square root of its area, known as Pollack’s rule [1], and the power is roughly proportional to the area. This means lower performance processors can achieve higher power efficiency. Therefore, we should make use of the multicore chip with relatively low performance processors.
The power wall is not a problem only for high-end server systems. Embedded systems also face this problem for further performance improvements [2]. MIPS is the abbreviation of million instructions per second, and a popular integer-performance measure of embedded processors. The same performance processors should take the same time for the same program, but the original MIPS varies, reflecting the number of instructions executed for a program. Therefore, the performance of a Dhrystone benchmark relative to that of a VAX 11/780 minicomputer is broadly used [3, 4]. This is because it achieved 1 MIPS, and the relative performance value is called VAX MIPS or DMIPS, or simply MIPS. Then GIPS (giga-instructions per second) is used instead of the MIPS to represent higher performance.
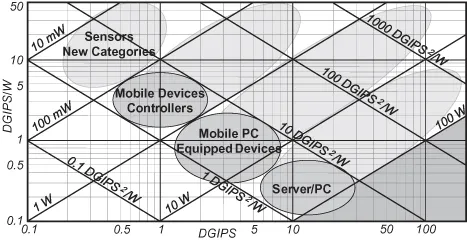
Figure 1.1 roughly illustrates the power budgets of chips for various application categories. The horizontal and vertical axes represent performance (DGIPS) and efficiency (DGIPS/W) in logarithmic scale, respectively. The oblique lines represent constant power (W) lines and constant product lines of the power–performance ratio and the power (DGIPS2/W). The product roughly indicates the attained degree of the design. There is a trade-off relationship between the power efficiency and the performance. The power of chips in the server/personal computer (PC) category is limited at around 100 W, and the chips above the 100-W oblique line must be used. Similarly, the chips roughly above the 10- or 1-W oblique line must be used for equipped-devices/mobile PCs, or controllers/mobile devices, respectively. Further, some sensors must use the chips above the 0.1-W oblique line, and new categories may grow from this region. Consequently, we must develop high DGIPS2/W chips to achieve high performance under the power limitations.
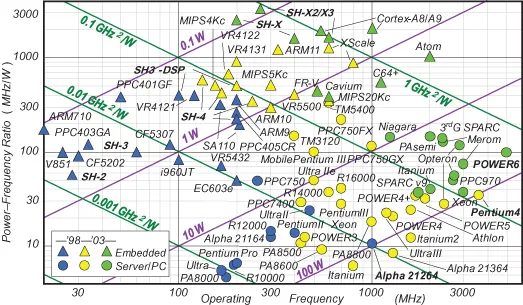
Figure 1.2 maps various processors on a graph, whose horizontal and vertical axes respectively represent operating frequency (MHz) and power–frequency ratio (MHz/W) in logarithmic scale. Figure 1.2 uses MHz or GHz instead of the DGIPS of Figure 1.1. This is because few DGIPS of the server/PC processors are disclosed. Some power values include leak current, whereas the others do not; some are under the worst conditions while the others are not. Although the MHz value does not directly represent the performance, and the power measurement conditions are not identical, they roughly represent the order of performance and power. The triangles and circles represent embedded and server/PC processors, respectively. The dark gray, light gray, and white plots represent the periods up to 1998, after 2003, and in between, respectively. The GHz2/W improved roughly 10 times from 1998 to 2003, but only three times from 2003 to 2008. The enhancement of single cores is apparently slowing down. Instead, the processor chips now typically adopt a multicore architecture.
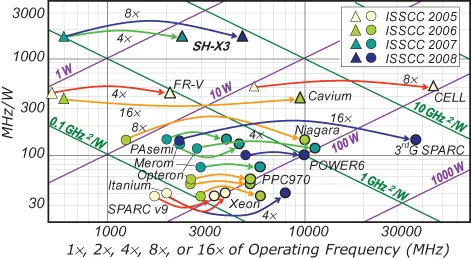
Figure 1.3 summarizes the multicore chips presented at the International Solid-State Circuit Conference (ISSCC) from 2005 to 2008. All the processor chips presented at ISSCC since 2005 have been multicore ones. The axes are similar to those of Figure 1.2, although the horizontal axis reflects the number of cores. Each plot at the start and end points of an arrow represent single core and multicore, respectively.
The performance of multicore chips has continued to improve, which has compensated for the slowdown in the performance gains of single cores in both the embedded and server/PC processor categories. There are two types of muticore chips. One type integrates multiple-chip functions into a single chip, resulting in a multicore SoC. This integration type has been popular for more than 10 years. Cell phone SoCs have integrated various types of hardware intellectual properties (HW-IPs), which were formerly integrated into multiple chips. For example, an SH-Mobile G1 integrated the function of both the application and baseband processor chips [5], followed by SH-Mobile G2 [6] and G3 [7, 8], which enhanced both the application and baseband functionalities and performance. The other type has increased number of cores to meet the requirements of performance and functionality enhancement. The RP-1, RP-2 and RP-X are the prototype SoCs, and an SH2A-DUAL [9] and an SH-Navi3 [10] are the multicore products of this enhancement type. The transition from single core chips to multicore ones seems to have been successful on the hardware side, and various multicore products are already on the market. However, various issues still need to be addressed for future multicore systems.
The first issue concerns memories and interconnects. Flat memory and interconnect structures are the best for software, but hardly possible in terms of hardware. Therefore, some hierarchical structures are necessary. The power of on-chip interconnects for communications and data transfers degrade power efficiency, and a more effective process must be established. Maintaining the external input/output (I/O) performance per core is more difficult than increasing the number of cores, because the number of pins per transistors decreases for finer processes. Therefore, a breakthrough is needed in order to maintain the I/O performance.
The second issue concerns runtime environments. The performance scalability was supported by the operating frequency in single core systems, but it should be supported by the number of cores in multicore systems. Therefore, the number of cores must be invisible or virtualized with small overhead when using a runtime environment. A multicore system will integrate different subsystems called domains. The domain separation improves system reliability by preventing interference between domains. On the other hand, the well-controlled domain interoperation results in an efficient integrated system.
The third issue relates to the software development environments. Multicore systems will not be efficient unless the software can extract application parallelism and utilize parallel hardware resources. We have already accumulated a huge amount of legacy software for single cores. Some legacy software can successfully be ported, especially for the integration type of multicore SoCs, like the SH-Mobile G series. However, it is more difficult with the enhancement type. We must make a single program that runs on multicore, or distribute functions now running on a single core to multicore. Therefore, we must improve the portability of legacy software to the multicore systems. Developing new highly parallel software is another issue. An application or parallelization specialist could do this, although it might be necessary to have specialists in both areas. Further, we need a paradigm shift in the development, for example, a higher level of abstraction, new parallel languages, and assistant tools for effective parallelization.
1.2 SUPERH™ RISC ENGINE FAMILY (SH) PROCESSOR CORES
As mentioned above, a multicore chip is one of the most promising approaches to realize high efficiency, which is the key factor to ...