Evolving technologies have brought about an explosion of information in recent years, but the question of how such information might be effectively harvested, archived, and analyzed remains a monumental challenge—for the processing of such information is often fraught with the need for conceptual interpretation: a relatively simple task for humans, yet an arduous one for computers.
Inspired by the relative success of existing popular research on self-organizing neural networks for data clustering and feature extraction, Unsupervised Learning: A Dynamic Approach presents information within the family of generative, self-organizing maps, such as the self-organizing tree map (SOTM) and the more advanced self-organizing hierarchical variance map (SOHVM). It covers a series of pertinent, real-world applications with regard to the processing of multimedia data—from its role in generic image processing techniques, such as the automated modeling and removal of impulse noise in digital images, to problems in digital asset management and its various roles in feature extraction, visual enhancement, segmentation, and analysis of microbiological image data.
Self-organization concepts and applications discussed include:
Distance metrics for unsupervised clustering
Synaptic self-amplification and competition
Image retrieval
Impulse noise removal
Microbiological image analysis
Unsupervised Learning: A Dynamic Approach introduces a new family of unsupervised algorithms that have a basis in self-organization, making it an invaluable resource for researchers, engineers, and scientists who want to create systems that effectively model oppressive volumes of data with little or no user intervention.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
With the explosion of information brought about by this Multimedia Age, the question of how such information might be effectively harvested, archived, and analysed, remains a monumental challenge facing today’s research community. The processing of such information, however, is often fraught with the need for conceptual interpretation—a relatively simple task for humans, yet arduous for computers. In order to handle the oppressive volumes of information that are becoming readily accessible in consumer and industrial sectors, some level of automation is desirable.
Automation requires computational systems that exhibit some degree of intelligence, in terms of the ability of a system to formulate its own models of the data in question with little or no user intervention. Such systems must be able to make basic decisions about what information is actually important and what is not. In effect, like a human user, the system must be able to discover characteristic properties of the data in some appropriate manner, without a teacher. This process is known as unsupervised learning (sometimes referred to as clustering or unsupervised pattern classification; an essentially pure form of data mining).
This book primarily introduces a new approach to the general problem of unsupervised learning, based on the principles of dynamic self-organization. Inspired by the relative success of other popular research on self-organizing neural networks for data clustering and feature extraction, this book presents new members within the family of generative, Self-Organizing Maps, namely: the self-organizing tree map (SOTM) and its advanced form, the self-organizing hierarchical variance map (SOHVM). While the devised approach is essentially generic, the core application considered in this book is the automatic, unsupervised data clustering for multimedia applications and unsupervised segmentation of microbiological image data.
1.1 PART I: THE SELF-ORGANIZING METHOD
Computational technologies based on Artificial Neural Networks (ANN) have been the focus of much research into the problem of unsupervised learning, in particular, for network architectures that are based on principles of Self-Organization. Such principles are in many ways centered on Turing’s initial observation in 1952 [1], namely, that Global order can arise from Local interactions. With much support from neurobiological research, such mechanisms are believed to be analogous to the organization that takes place in the human brain.
Clustering algorithms use unsupervised learning rules to group unlabeled training data into similar or dense clusters. Unsupervised training algorithms depend upon internally generated error measures, which are derived solely from training data. The network has no knowledge of the correct answer during training and, consequently, must derive the errors and the necessary weight modifications directly from the statistics of the training data. As a result, input patterns are stored as a set of cluster prototypes or exemplars—representations or natural groupings of similar data. In forming a description of an unknown set of data, such network architectures are characterized by their adherence to four key properties [2]: synaptic self-amplification for mining correlated stimuli, competition over limited resources, cooperative encoding of information, and the implicit ability to encode pattern redundancy as knowledge. Such principles are, in many ways, a reflection of Turing’s observations previously discussed.
Part I of this book consists of Chapters 2 and 3. It gives an extensive review of the general problems of unsupervised clustering, with emphasis placed on the inherent relationship that exists between unsupervised learning and Self-Organization. The unsupervised learning problem is first defined with respect to the concepts of similarity and distance. A survey of unsupervised techniques from the broader field is then conducted to establish the context for more focused surveys on self-organization-based principles and architectures. The issue of validating unsupervised clustering solutions in the absence of a ground truth is also addressed.
1.2 PART II: DYNAMIC SELF-ORGANIZATION FOR IMAGE FILTERING AND MULTIMEDIA RETRIEVAL
Multimedia processing has seen impressive growth in the past decade in terms of both theoretical development and applications. It represents a leading technology in a number of important areas that warrant significant need for data mining, namely, digital telecommunications, multimedia systems, high dimensional image analysis and visualization, information retrieval, biology, robotics and manufacturing, and intelligent sensing systems. Inherently unsupervised in nature, neural network architectures based on principles of Self-Organization appear to be a natural fit.
In Part II of this book, the SOTM and its recently successful application in multimedia processing is presented. This neural network architecture incorporates hierarchical properties by virtue of its growth, in a manner that is flexible in terms of revealing the underlying data space without being constrained by an imposed topological framework. As such, the SOTM exhibits many desirable properties over traditional self-organizing feature map (SOFM) based strategies. Chapter 4 of the book will provide an in-depth coverage of this architecture. Chapters 5 and 6 will then cover a series of pertinent real-world applications with regard to the processing of multimedia data. This includes problems in image-processing techniques, such as the automated modeling and removal of impulse noise in digital images, and problems in image classification in multimedia indexing and retrieval.
In Chapter 4, the SOTM algorithm is explored and developed, wherein a number of enhancements and modifications are proposed, justified, and tested, with the goal of rendering the SOTM more robust under application to different datasets. Specifically, alternative modalities for hierarchical control and learning are considered, in addition to more appropriate stopping criteria linked to aspects of the input data. The SOTM is then explored as a means of segmenting biofilm images, where its strengths and flexibility as a dynamic clustering model for segmentation are explored. Limitations and deficiencies of the SOTM are also identified.
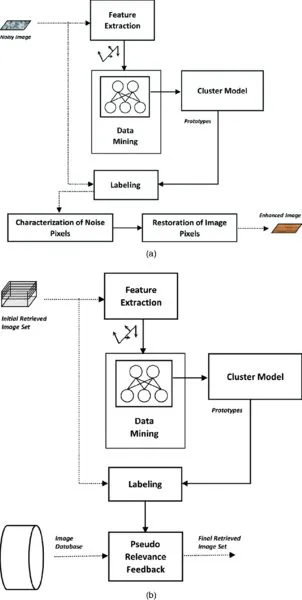
In Chapter 5, the SOTM is applied to the automated modeling and removal of impulse noise in digital images. Improving the quality of images degraded by noise is a classic problem in image processing [3]. In the early stages of signal and image processing, linear filters were the primary tools for noise cleaning. Later, the development of nonlinear filtering techniques for signal and image processing was spurred by some drawbacks of linear filters [4]. However, one problem with nonlinear filers such as the median filter is that they remove the fine details in the image and change the signal structure. In addition, improved nonlinear filters, such as the weighted median filter, multistage median filter, and nonlinear mean filters, have better detail-preserving characteristics at the expense of poorer noise suppression. Here, a novel approach for suppressing impulse noise in digital images is proposed for effectively preserving more image detail than previously proposed methods. The noise removal system, shown in Figure 1.1a, consists of two steps: the detection of the noise and the reconstruction of the image. As the SOTM network has the capability to classify pixels in an image, it is employed to detect the impulses. A noise-exclusive median (NEM) filtering algorithm and a noise-exclusive arithmetic mean (NEAM) filtering algorithm are proposed to restore the image. This system is able to detect noise locations accurately, and thus, achieves the best possible restoration of images corrupted by impulse noise.
FIGURE 1.1 Unsupervised Learning–based framework for (a) automated modeling and removal of impulse noise in digital images and (b) image classification in multimedia indexing and retrieval.
In Chapter 6, the SOTM is applied to problems in image classification in multimedia indexing and retrieval. The system architecture is shown in Figure 1.1b. In multimedia database retrieval, relevance feedback (RF) is a popular and effective way to improve the performance of image re-ranking and retrieval. However, RF needs a high level of human participation, which often leads to excessive subjective errors. Here, an automatic RF is present, using the SOTM, which minimizes user participation, providing a more user-friendly environment and avoiding errors caused by excessive human involvement. Unlike the conventional retrieval system, where the user’s direct input is required in the execution of the RF algorithm, SOTM estimation is now adopted to guide the adaptation of the RF parameters. As shown in Figure 1.1b, the initially retrieved samples are labeled with the unsupervised module, and image re-ranking is performed by the pseudo-labeled samples. As a result, instead of imposing a greater responsibility on the user, independent learning can be integrated to improve retrieval accuracy. This makes it possible to obtain either a fully automatic or a semiautomatic RF system suitable for practical applications.
1.3 PART III: DYNAMIC SELF-ORGANIZATION FOR IMAGE SEGMENTATION AND VISUALIZATION
Much emphasis of this book is placed on Part III, on the developments of the SOHVM and its application in the unsupervised segmentation and visualization of microbiological image data. With recent advances in imaging, computer, and optical modalities for microscopy, a paradigm shift away from the purely observational toward the extraction of more quantitative information seems to be taking place. As such, data mining techniques are thought to serve as a useful basis for further processing stages. To this end this book demonstrates the capability of the newly proposed SOHVM over its predecessors and other popular self-organizing and partition-based clustering algorithms, for formulating a relatively stable clustering solution. Furthermore, avenues are explored for how the model can extract and use data associations discovered between clusters.
In the interests of assisting biologists in exploring previously unseen, unlabeled image data, unsupervised methods for attaining useful data-driven segmentations are explored, serving as a useful basis for further processing stages such as visualization or quantitative analysis.
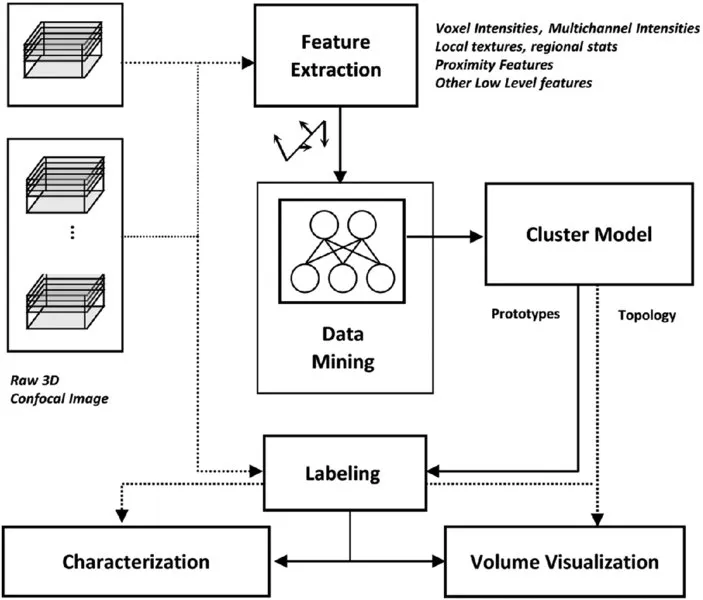
In general, the approach taken is to identify characteristic biological materials present in the data, by identifying natural groupings (clusters) of similar voxel patterns—where an individual voxel pattern may be thought of as a vector of one or more different attributes, to which we refer as features. The framework for the approach taken is summarized in Figure 1.2.
FIGURE 1.2 Unsupervised Learning–based framework for mining segmentations for visualization and characterization of microbiological image data.
In the most basic example, a voxel pattern from a single channel image might comprise a single feature only, namely, its intensity value. Alternatively, over a three-channel image, a voxel pattern may be a three-tuple vector, with one dimension for each channel. Under this framework, higher level, n-dimensional pattern vectors also become possible, allowing for the possibility of fusing local regional or other information extracted from the image into the description of each voxel. For instance, at a later stage in this stu...
Table of contents
Cover
IEEE Press
Titlepage
Copyright
Acknowledgments
1 Introduction
2 Unsupervised Learning
3 Self-Organization
4 Self-Organizing Tree Map
5 Self-Organization in Impulse Noise Removal
6 Self-Organization in Image Retrieval
7 The Self-Organizing Hierarchical Variance Map:
8 Microbiological Image Analysis Using Self-Organization
9 Closing Remarks and Future Directions
Appendix A
References
Index
IEEE Press Series
End User License Agreement
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Unsupervised Learning by Matthew Kyan,Paisarn Muneesawang,Kambiz Jarrah,Ling Guan in PDF and/or ePUB format, as well as other popular books in Computer Science & Artificial Intelligence (AI) & Semantics. We have over 1.5 million books available in our catalogue for you to explore.