- Comprehensively revised, updated and rewritten to encompass within one volume, basic and advanced gene manipulation techniques, genome analysis, genomics, transcriptomics, proteomics and metabolomics
- Includes two new chapters on the applications of genomics
- An accompanying website - www.blackwellpublishing.com/primrose - provides instructional materials for both student and lecturer use, including multiple choice questions, related websites, and all the artwork in a downloadable format.
- An essential reference for upper level undergraduate and graduate students of genetics, genomics, molecular biology and recombinant DNA technology.

- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Principles of Gene Manipulation and Genomics
About this book
The increasing integration between gene manipulation and genomics is embraced in this new book, Principles of Gene Manipulation and Genomics, which brings together for the first time the subjects covered by the best-selling books Principles of Gene Manipulation and Principles of Genome Analysis & Genomics.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
CHAPTER 1
Gene manipulation in the post-genomics era
Introduction
Since the beginning of the last century, scientists have been interested in genes. First, they wanted to find out what genes were made of, how they worked, and how they were transmitted from generation to generation with the seemingly mythic ability to control both heredity and variation. Genes were initially thought of in functional terms as hereditary units responsible for the appearance of particular biological characteristics, such as eye or hair color in human beings, but their physical properties were unclear. It was not until the 1940s that genes were shown to be made of DNA, and that a workable physical and functional definition of the gene – a length of DNA encoding a particular protein – was achieved (Box 1.1). Next, scientists wanted to find ways to study the structure, behavior, and activity of genes in more detail. This required the simultaneous development of novel techniques for DNA analysis and manipulation. These developments began in the early 1970s with the first experiments involving the creation and manipulation of recombinant DNA. Thus began the recombinant DNA revolution.
Gene manipulation involves the creation and cloning of recombinant DNA
The definition of recombinant DNA is any artificially created DNA molecule which brings together DNA sequences that are not usually found together in nature. Gene manipulation refers to any of a variety of sophisticated techniques for the creation of recombinant DNA and, in many cases, its subsequent introduction into living cells. In the developed world there is a precise legal definition of gene manipulation as a result of government legislation to control it. In the UK, for example, gene manipulation is defined as: “… the formation of new combinations of heritable material by the insertion of nucleic acid molecules,produced by whatever means outside the cell, into any virus, bacterial plasmid or other vector system so as to allow their incorporation into a host organism in which they do not naturally occur but in which they are capable of continued propagation.” The propagation of recombinant DNA inside a particular host cell so that many copies of the same sequence are produced is known as cloning.
Cloning was a significant breakthrough in molecular biology because it became possible to obtain homogeneous preparations of any desired DNA molecule in amounts suitable for laboratory-scale experiments. A single organism, the bacterium Escherichia coli, played the dominant role in the early years of the recombinant DNA era. This bacterium had always been a popular model system for molecular geneticists and, prior to the development of recombinant DNA technology, there were already a large number of well-characterized mutants, gene regulation was understood, and many plasmids had been isolated. It is not surprising that the first cloning experiments were undertaken in E. coli and that this organism became the primary cloning host. Subsequently, cloning techniques were extended to a range of other microorganisms, such as Bacillus subtilis, Pseudomonas spp., yeasts, and filamentous fungi, and then to higher eukaryotes. Despite these advances, E. coli remains the most widely used cloning host even today because gene manipulation in this bacterium is technically easier than in any other organism. As a result, it is unusual for researchers to clone DNA directly in other organisms. Rather, DNA from the organism of choice is first manipulated in E. coli and subsequently transferred back to the original host or another organism, as appropriate. Without the ability to clone and manipulate DNA in E. coli, the application of recombinant DNA technology to other organisms would be greatly hindered.
Until the mid-1980s, all cloning was cell-based (i.e. the DNA molecule of interest had to be introduced into E. coli or another host for amplification).
Box 1.1 What is a gene?
The concept of the gene as a unit of hereditary information was introduced by the Austrian monk Gregor Mendel in an 1866 paper entitled ‘Experiments in plant hybridization’. In this paper, he detailed the results of numerous crosses between pea plants of different characteristics, and from these data put forward a number of postulates concerning the principles of heredity.
Although Mendel introduced the concept, the word gene was not used until 25 years after his death. It was coined by Wilhelm Johansen in 1909 to describe a heritable factor responsible for the transmission and expression of a given biological trait. In Mendel’s work, published over 40 years earlier, these hereditary factors were given the rather less catchy name Formbildungelementen (form-building elements).
Mendel had no clear idea what his hereditary elements consisted of in a physical sense, and described them as purely mathematical entities. The first evidence as to the physical and functional nature of genes emerged in 1902. In this year, the chromosome theory of inheritance was put forward by William Sutton, after he noticed that chromosomes during meiosis behaved in the same way as Mendel’s elements. Also in 1902, Archibald Garrod showed that the metabolic disorder alkaptonurea resulted from the failure of a specific enzyme and could be transmitted in an autosomal recessive fashion. This he called an inborn error of metabolism. This was the first evidence that genes were necessary to make proteins. In 1911, Thomas Hunt Morgan and colleagues performed the first genetic linkage experiments in the fruit fly Drosophila melanogaster, and hence showed that genes were located on chromosomes and were physically linked together.
A more precise idea of the physical and functional basis for the gene emerged during the Second World War. In 1942, George Beadle and Edward Tatum found that X-ray-induced mutations in fungi often caused specific biochemical defects, reflecting the absence or malfunction of a single enzyme. This led to the one gene one enzyme model of gene function. In 1944, Oswald Avery and colleagues showed that DNA was the genetic material. Thus evolved a simple picture of the gene – a length of DNA in a chromosome which encoded the information required to produce a single enzyme.
This definition had to be expanded in the following years to encompass new discoveries. For example, not all genes encode enzymes: many encode proteins with other functions, and some do not encode proteins at all, but produce functional RNA molecules. Further complexity results from the selective use of information in the gene to generate multiple products. In eukaryotes, this often reflects alternative splicing, but in both prokaryotes and eukaryotes multiple gene products can be generated by alternative promoter or polyadenylation site usage. In more obscure cases, two or more genes may be required to generate a single polypeptide, e.g. the rare phenomenon of trans-splicing.
In 1983, there was a further mini-revolution in molecular biology with the invention of the polymerase chain reaction (PCR). This technique allowed DNA sequences to be amplified in vitro using pure enzymes. The great sensitivity and robustness of the PCR allows DNA to be prepared rapidly from very small amounts of starting material and material of very poor quality, but it is not as accurate as cell-based cloning and only works on relatively short DNA sequences. Therefore cell-based cloning and the PCR have complementary but overlapping uses in gene manipulation.
Although the initial cloning experiments generated a great deal of excitement, it is unlikely that any of the early workers in this field could have predicted the immense impact recombinant DNA technology would have on the progress of scientific understanding and indeed on society as a whole, particularly in the fields of medicine and agriculture. Today, gene manipulation underlies a multi-billion dollar industry, employing hundreds of thousands of people worldwide and offering solutions to some of mankind’s most intractable problems. The ability to insert new combinations of genetic material into microbes, animals, and plants offers novel ways to produce valuable small molecules and proteins; provides the means to produce plants and animals that are disease-resistant, tolerant of harsh environments, and have higher yields of useful products; and provides new methods to treat and prevent human disease.
Fig. 1.1 The impact of gene manipulation on the practice of medicine.
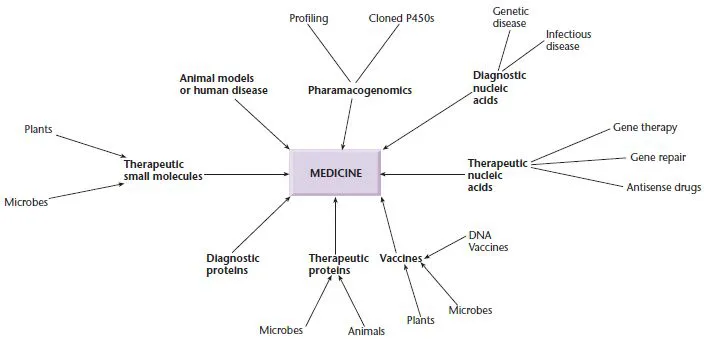
Recombinant DNA has opened new horizons in medicine
The developments in gene manipulation that have taken place in the last 30 years have revolutionized medicine by increasing our understanding of the basis of disease, providing new tools for disease diagnosis, and opening the way to the discovery or development of new drugs, treatments, and vaccines.
The first medical benefit to arise from recombinant DNA technology was the availability of significant quantities of therapeutic proteins, such as human growth hormone (HGH), which is used to treat growth defects. Originally HGH was purified from pituitary glands removed from cadavers. However, many pituitary glands are required to produce enough HGH to treat just one child. Furthermore, some children treated with pituitary-derived HGH have developed Creutzfeld–Jakob syndrome originating from cadavers. Following the cloning and expression of the HGH gene in E. coli, it became possible to produce enough HGH in a 10-liter fermenter to treat hundreds of children. Since then, many different therapeutic proteins have become available for the first time. Many of these proteins are also manufactured in E. coli but others are made in yeast or animal cells and some in plants or the milk of genetically modified animals. The only common factor is that the relevant gene has been cloned and overexpressed using the techniques of gene manipulation.
Medicine has benefited from recombinant DNA technology in other ways (Fig. 1.1). For example, novel routes to vaccines have been developed: the current hepatitis B vaccine is produced by the expression of a viral antigen on the surface of yeast cells, and a recombinant vaccine has been used to eliminate rabies from foxes in a large part of Europe. Gene manipulation can also be used to increase the levels of small molecules within microbial or plant cells. This can be done by cloning all the genes for a particular biosynthetic pathway and overexpressing them. Alternatively, it is possible to shut down particular metabolic pathways and thus redirect intermediates towards the desired end product. This approach has been used to facilitate production of chiral intermediates, antibiotics, and novel therapeutic entities. New antibiotics can also be created by mixing and matching genes from organisms producing different but related molecules in a technique known as combinatorial biosynthesis.
Gene cloning enables nucleic acid probes to be produced readily, and such probes have many uses in medicine. For example, they can be used to determine or confirm the identity of a microbial pathogen or to carry out pre- or peri-natal diagnosis of an inherited genetic disease. Increasingly, probes are being used to determine the likelihood of adverse reactions to drugs or to select the best class of drug to treat a particular illness in different groups of patients. Nucleic acids are also being used as therapeutic entities in their own right. For example, antisense nucleic acids are being used to downregulate gene expression in certain diseases, and the relatively new phenomenon of RNA interference is poised to become a breakthrough technology for the development of new therapeutic approaches. In other cases, nucleic acids are being administered to correct or repair inherited gene defects (gene therapy, gene repair) or as vaccines. In the reverse of gene repair, animals are being generated that have mutations identical to those found in human disease. These are being used as models to learn more about disease pathology and to test novel therapies.
Mapping and sequencing technologies formed a crucial link between gene manipulation and genomics
As well as techniques for DNA cloning and transfer to new host cells, the recombinant DNA revolution spawned new technologies for gene mapping (ordering genes on chromosomes) and DNA sequencing (determining the order of bases, identified by the letters A, C, G, and T, along the DNA molecule). Within the gene itself, the order of bases determines the protein encoded by the gene by specifying the order of amino acids. Thus, DNA sequencing made it possible to work out the amino acid sequence of the encoded protein without the direct analysis of the protein itself. This was extremely useful because, at the time DNA sequencing was first developed, only the most abundant proteins in the cell could be purified in sufficient quantities to facilitate direct analysis. Further elements surrounding the coding region of the gene were identified as control regions, specifying each gene’s expression profile. As more sequence data accumulated, it became possible to identify common features in related genes, both in the coding region and the regulatory regions. This type of sequence analysis was greatly facilitated by the foundation of sequence databases, and the development of computer-aided techniques for sequence analysis and comparison, a field now known as bioinformatics. Today, DNA molecules can be scanned quickly for a whole series of structural features, e.g. restriction enzyme recognition sites, matches or overlaps with other sequences, start and stop signals for transcription and translation, and sequence repeats, using programs available on the Internet.
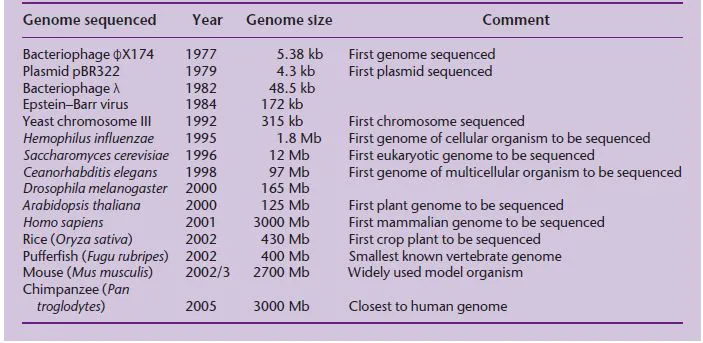
The original goal of sequencing was to determine the precise order of nucleotides in a gene, but soon the goal became the sequence of a small genome. A genome is the complete content of genetic information in an organism, i.e. all the genes and other sequences it contains. The first target was the genome of a small virus called ϕX174, then larger plasmid and viral genomes, then chromosomes and microbial genomes until ultimately the complete genomes of higher eukaryotes were sequenced (Table 1.1). In the mid-1980s, scientists began to discuss seriously how the entire human genome might be sequenced. To put these discussions in context, the largest stretch of DNA that can be sequenced in a single pass (even today) is 600–800 nucleotides and the largest genome that had been sequenced in 1985 was that of the 172-kb Epstein–Barr virus (Baer et al. 1984). By comparison, the human genome is 3000 Mb in size, over 17,000 times bigger! One school of thought was that a completely new sequencing methodology would be required, and a number of different technologies were explored but with little success. Early on, however, it was realized that existing sequencing technology could be used if a large genome could be broken down into more manageable pieces for sequencing in a highly parallel fashion, and then the pieces could be joined together again. A strategy was agreed upon in which a map of the human genome would be used as a scaffold to assemble the sequence.
Table 1.1 Timeline of genome sequencing, showing the increasing genome sizes that have been achieved.
The problem here was that in 1985 there were not enough markers, or points of reference, on the human genome map to produce a physical scaffold on which to assemble the complete sequence. Genetic maps are based on recombination frequencies, and in model organisms they are constructed by carrying out large-scale crosses between different mutant strains. The principle of a genetic map is that the further apart two loci are on a chromosome, the more likely that a crossover will occur between them during meiosis. Recombination events resulting from crossovers can be scored in genetically amenable organisms such as the fruit fly Drosophila melanogaster and yeast by looking for new combinations of the mutant phenotypes in the offspring of the cross. This approach cannot be used in human populations because it would involve setting up large-scale matings between people with different inherited diseases. Instead, human genetic maps rely on the analysis of DNA sequence polymorphisms, i.e. naturally occurring DNA sequence differences in the population which do not have an overt, debilitating effect. A major breakthrough was the development of methods for using DNA probes to identify polymorphic sequences (Botstein et al. 1980).
Prior to the Human Genome Project (HGP), low-resolution genetic maps had been constructed using restriction fragment length polymorphisms (RFLPs). These are naturally occurring variations that create or destroy sites for restriction enzymes and therefore generate different sized bands on Southern blots (Fig. 1.2). The Southern blot is a technique for separating DNA fragments by size, see Fig. 2.6, p. 23. The problem with RFLPs was that they were too few and too widely spaced to be of much use for constructing a framework for physical mapping – the first RFLP map had just over 400 markers and a resolution of 10 cM, equivalent to one marker for every 10 Mb of DNA (Donis-Keller et al. 1987). The necessary breakthrough came with the discovery of new polymorphic markers, known as microsatellites, which were abundant and widely dispersed in the genome (Fig. 1.3). By 1992, a genetic map based on microsatellites had been constructed with a resolution of 1 cM (equivalent to one marker for every 1 Mb of DNA) which was a suitable template for physical mapping.
Fig. 1.2 Restriction fragment length polymorphisms (RFLPs) are sequence variants that create or destroy a restriction site in DNA therefore altering the length of the restriction fragment that is detected. The top panel shows two alternative alleles, in which the restriction fragment detected by a specific probe differs in length due to the presence or absence of the middle of three restriction sites (represented by vertical arrows). Alleles a and b therefo...
Table of contents
- Cover
- Contents
- Title Page
- Copyright
- Preface
- Abbreviations
- Chapter 1: Gene manipulation in the post-genomics era
- Part I: Fundamental Techniques of Gene Manipulation
- Part II: Manipulating DNA in Microbes, Plants, and Animals
- Part III: Genome Analysis, Genomics, and Beyond
- Part IV: Applications of Gene Manipulation and Genomics
- References
- Appendix: the genetic code and single-letter amino acid designations
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Principles of Gene Manipulation and Genomics by Sandy B. Primrose,Richard Twyman in PDF and/or ePUB format, as well as other popular books in Biological Sciences & Genetics & Genomics. We have over 1.5 million books available in our catalogue for you to explore.