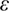![]()
PART I
Particle Swarm Optimization
![]()
Chapter 1
What is a Difficult Problem?
1.1. An intrinsic definition
As regards optimization, certain problems are regarded as more difficult than others. This is the case, inter alia, for combinatorial problems. But what does that mean? Why should a combinatorial problem necessarily be more difficult than a problem in continuous variables and, if this is the case, to what extent is it so? Moreover, the concept of difficulty is very often more or less implicitly related to the degree of sophistication of the algorithms in a particular research field: if one cannot solve a particular problem, or it takes a considerable time to do so, therefore it is difficult.
Later, we will compare various algorithms on various problems, and we will therefore need a rigorous definition. To that end, let us consider the algorithm for purely random research. It is often used as a reference, because even a slightly intelligent algorithm must be able to do better (even if it is very easy to make worse, for example an algorithm being always blocked in a local minimum). Since the measurement of related difficulty is very seldom clarified (see however [BAR 05]), we will do it here quickly.
The selected definition is as follows: the difficulty of an optimization problem in a given search space is the probability of not finding a solution by choosing a position at random according to a uniform distribution. It is thus the probability of failure at the first attempt.
Consider the following examples. Take the function f defined in [0 1] by f(x) = x. The problem is “to find the minimum of this function nearest within s”. It is easy to calculate (assuming that
is less than 1) that the difficulty of this problem,
following the definition above, is given by the quantity (1 – ε). As we can see in
Figure 1.1, it is simply the ratio of two measurements: the total number of acceptable solutions and the total number of possible positions (in fact, the definition of a probability). From this point of view, the minimization of x2 is twice as easy as that of x.
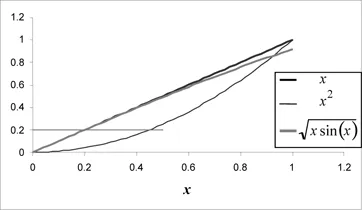
It should be noted that this assessment of difficulty can depend on the presence of local minima. For example,
Figure 1.2 represents part of the graph of a variant of the so-called “Alpine” function,
f (
x) = |
xsin(
x) + 0.1
x|. For
= 0.5 the field of the acceptable solutions is not connected. Of course, a part contains the position of the global minimum (0), but another part surrounds that of a local minimum whose value is less than ε. In other words, if the function presents local minima, and particularly if their values are close to that of the global minimum, one is quite able to obtain a satisfactory mathematical solution, but whose position is nevertheless very far from the hoped for solution.
By reducing the tolerance level (the acceptable error), one can certainly end up selecting only solutions actually located around the global minimum, but this procedure obviously increases the practical difficulty of the problem. Conversely, therefore, one tries to reduce the search space. But this requires some knowledge of the position of the solution sought and, moreover, it sometimes makes it necessary to define a search space that is more complicated than a simple Cartesian product of intervals; for example, a polyhedron, which may even be non-convex. However, we will see that this second item can be discussed in PSO by an option that allows an imperative constraint of the type g(position) < 0 to be taken into account.
1.2. Estimation and practical measurement
When high precision is required, the probability of failure is very high and to take it directly as a measure of difficulty is not very practical. Thus we will use instead a logarithmic measurement given by the following formula:
difficulty = −ln(1 − failure probability) = −ln(success probability)
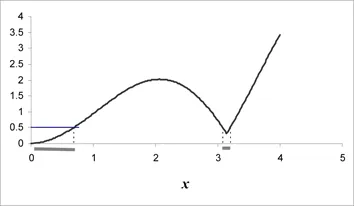
In this way one obtains more easily comparable numbers. Table 1.1 presents the results for four small problems. In each case, it is a question of reaching a minimal value. For the first three, the functions are continuous and one must accept a certain margin of error because that is what makes it possible to calculate the probability of success. The last problem is a classic “traveling salesman problem” with 27 cities, for which only one solution is supposed to exist. Here, the precision required is absolute: one wants to obtain this solution exactly.
We see, for example, that the first and last problems are of the same level of intrinsic difficulty. It is therefore not absurd to imagine that the same algorithm, particularly if it uses randomness advisedly, can solve one as well as the other. Moreover, and we will return to this, the distinction between discrete/combinatorial problems and continuous problems is rather arbitrary for at least two reasons:
– a continuous problem becomes necessarily discrete, since it is treated on a numerical computer, hence with limited precision;
– a discrete problem can be replaced by an equivalent continuous problem under constraints, by interpolating the function defining it on the search space.
1.3. For “amatheurs”: some estimates of difficulty
The probability of success can be estimated in various ways, according to the form of the function:
– direct calculation by integration in the simple cases;
– calculation on a finite expansion, either of the function itse...