![]()
III
RECOMMENDATIONS
![]()
10
APPLICATIONS, SOLUTIONS, AND ACCOUNTABILITY
Cloud computing is inherently a more complicated arrangement than tradition computing; instead of suppliers offering equipment and applications directly to enterprises that will operate the equipment and applications, cloud computing separates the cloud consumer enterprise that rents computing resources from the cloud service provider who owns and operates the computing resources. In addition to suppliers, cloud service providers, and cloud consumers, there are likely to be several communications service providers hauling IP traffic between end users and cloud data centers. All of these players are accountable for some service impairments that can impact the quality of experience for end users. This chapter offers canonical service downtime budgets and models to help understand how accountability changes as traditional applications migrate to the cloud. This chapter also frames the broader challenge of end-to-end service availability via several standard service measurement points.
10.1 APPLICATION CONFIGURATION SCENARIOS
Virtualization enables deployment flexibility beyond the options of traditional application deployment. In rough order of increasing complexity, these virtualization scenarios are as follows:
- Traditional or Native Deployment (i.e., No Virtualization Is Used). A software application is installed and integrated with an operating system running directly on nonvirtualized physical hardware.
- Hardware Independence Usage Scenario. virtualization reduces or eliminates an application’s dependence on the specifics of the underlying physical hardware in the hardware independence usage model. While the application may still require the same machine instruction set (e.g., Intel), virtualization can decouple the physical memory, networking, storage, and other hardware-centric details from the application software so the application can be moved onto modern hardware rather than being tied to legacy hardware platforms.
- Server Consolidation Usage Scenario. In the server consolidation usage scenario, virtualization is used to increase resource utilization by having multiple applications share hardware resources. In some cases, this provides the ability to take advantage of otherwise underutilized hardware resources. Moore’s law assures that the processing power of servers grows steadily over time, yet the processing needs of individual application instances does not necessarily grow as rapidly. Thus, in many cases, the growth in available processing power may not be effectively used by a single application running on the server hardware. In these cases, applications may nominally oversubscribe hardware capacity and the hypervisor relies on statistical usage patterns to make resource sharing work well.
- Multitenant Usage Scenario. A multitenant deployment permits multiple independent instances of a single application to be consolidated onto a single virtualized platform. For example, different application instances can be used for different user communities, such as for different enterprise customers; web service and electronic mail are examples of common multi-tenant applications as multiple independent instances of the same application may be running on a virtualized server platform to simultaneously serve different web sites or users from different enterprises. While some applications are explicitly written to be multitenant, other applications were written with the design assumption that a single application instances on a single hardware platform supports a single user community. Virtualization can facilitate making these single system-per-user community applications support multitenancy configurations in which several distinct user communities peacefully coexist on a shared, virtualized hardware platform.
- Virtual Appliance Usage Scenario. The virtual appliance notion of the Distributed Management Task Force [DSP2017] represents one ultimate vision of virtualization. In the appliance vision, applications are delivered as turnkey software prepackaged with operating systems, protocol stacks and supporting software. The supplier benefits by being able to thoroughly test the production configuration of all system software, and the customer benefits from simpler installation and maintenance, and should enjoy the higher quality enabled by having their field deployment software configuration be 100% identical to the reference configuration that was validated by the appliance supplier.
- Cloud Deployment Usage Scenario. The cloud deployment usage scenario provides the most flexible configuration, which is able to grow and degrow automatically along with changing workloads. With the flexibility of cloud deployment comes increased complexity, which is mitigated by service orchestration and elasticity, which provide automation guided by policies and usage data. Cloud deployment risks and mitigations are primarily considered in Chapter 13, “Design for Reliability of Cloud Solutions.”
Undoubtedly not all usage scenarios will apply to all applications. As a practical matter, some organizations will integrate virtualization into their existing applications over several releases by supporting different usage scenarios in different releases. For example, an application might be engineered and tested to support server consolidation in one release; engineered and tested for multitenant and cloud deployment in another release, and eventually offered as a virtualized appliance in a later release.
10.2 APPLICATION DEPLOYMENT SCENARIO
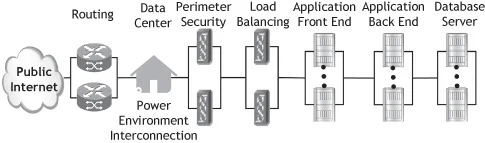
Neither traditional nor virtualized systems are useful in isolation; to deliver useful service to users, some physical hardware must be installed in a suitable physical environment and supplied with both power and IP connectivity. Operationally, this is generally achieved by deploying applications into a data center (see Section 1.3.1, “What Is a Data Center?”). Organizations do not generally deploy applications by simply connecting a traditional or virtualized server hosting an application into a data center to the public internet. Instead, there is usually a security appliance like a firewall or deep packet inspection server to enforce a security perimeter to protect the application from external attack. Within the security perimeter is often a load balancer to distribute the offered load across the application’s front-end servers. Many applications are architected with multiple tiers to simplify scalability, such as supporting user interface and client interaction in a tier of front-end servers, implementing application logic and business rules in a middle tier, and maintaining application data in a third tier of database servers. As critical applications are generally designed to remain operational even during routine maintenance and repair, these elements are often deployed across redundant instances. All of this physical hardware is installed in a data center that provides power, a suitably controlled environment, and network connectivity to all of the elements, including the routers that connect the data center to the public Internet. This canonical application deployment architecture is illustrated in Figure 10.1. Note that although the diagram shows pictures of server hardware elements, software on routers, perimeter security, load balancers, application front-end, application back-end, and database servers is implicitly assumed to be included in this deployment diagram.
Thus, the service availability seen by a user outside of the data center implicitly integrates the downtime of the data center’s routers, perimeter security, load balancers, power, environment and IP interconnection infrastructure, as well as the target application, and all this equipment and infrastructure is inevitably subject to failures, just as the target application is. The service availability seen from the public Internet for one application instance in one data center is inevitably lower than that of the product-attributable service availability of standalone applications.
10.3 SYSTEM DOWNTIME BUDGETS
System architects and reliability engineers use downtime budgets to manage service availability. For example, a system with “five 9’s” service availability is budgeted to have annual service downtime of 5.26 minutes per year; 5.26 minutes per year is the multiplicative product of the number of minutes per year (i.e., 365.25 days per average year times 24 hours per day times 60 minutes per hour) multiplied by 0.001% (99.999% uptime means 0.001% downtime). As with any budget:
- the expected downtime “expenses” are categorized;
- each category is assigned a reasonable allocation of the overall downtime budget;
- category allocations are adjusted to reach an acceptable and optimal total “cost”;
- architecture, design, and test plans are managed to achieve the individual downtime allocations; and
- if the downtime budget is missed in one measurement period (e.g., release), then it can be altered, and/or additional effort can be invested in the next period to meet the downtime budget.
Thus, the question of whether or not a virtualized system instance can achieve the same service availability as a native configuration comes down to the question of whether it is feasible and likely that a virtualized deployment can achieve a long-term average downtime budget that is equivalent to the downtime budget of a native system. We consider this question in three steps:
1. review the product-attributable downtime budget of a sample traditional high availability system;
2. alter the traditional product-attributable downtime budget for a hardware-independence virtualized deployment scenario and assess implications for an infrastructure as a service (IaaS) supplier; and
3. revise the hardware independence budget for cloud deployment scenario.
10.3.1 Traditional System Downtime Budget
Traditionally, system downtime expectations and predictions offered by suppliers covered only product-attributable service downtime, which is largely due to software and hardware failures (see Section 3.3.6, “Outage Attributability”). Downtime caused by factors not attributable to the system supplier or the product itself (e.g., power failures, network failures, and human mistakes by the customer’s maintenance staff) are generally excluded from product-attributable system availability measurements and predictions because they are allocated to other categories (e.g., customer-attributable downtime). Likewise, the measurement typically covered only agreed service time, so scheduled or planned downtime periods were excluded (see Section 3.3.1, “Service Availability Metric,” and Section 3.3.7, “Planned or Scheduled Downtime”).
Traditional system downtime budgets allocate unplanned product-attributed service downtime across three broad categories: hardware, software, and planned/procedural (sometimes called “human”). A traditional “five 9’s” system budget generally allocates 10% of the budgeted 5.26 prorated minutes (315 prorated seconds) of annual service downtime to hardware, meaning that hardware attributed causes typically gets about 30 seconds of prorated annual downtime. The vast majority of the remaining downtime will be allocated to unplanned software failures, but some of the remaining 4 minutes and 45 seconds might be budgeted to unsuccessful planned and procedural activities like failed software upgrades. The software downtime may be further budgeted either by architectural layer (e.g., application software vs. platform software) or by functional mo...