![]()
Part One
Introduction to Service Availability
![]()
Chapter 1
Definitions, Concepts, and Principles
Francis Tam
Nokia Research Center, Helsinki, Finland
1.1 Introduction
As our society increasingly depends on computer-based systems, the need for making sure that services are provided to end-users continuously has become more urgent. In order to build such a computer system upon which people can depend, a system designer must first of all have a clear idea of all the potential causes that may bring down a system. One should have an understanding of the possible solutions to counter the causes of a system failure. In particular, the costs of candidate solutions in terms of their resource requirements must also be known. Finally, the limits of the eventual system solution that is put in place must be well understood.
Dependability can be defined as the quality of service provided by a system. This definition encompasses different concepts, such as reliability and availability, as attributes of the service provided by a system. Each of these attribute can therefore be used to quantify aspects of the dependability of the overall system. For example, reliability is a measure of the time to failure from an initial reference instant, whereas availability is the probability of obtaining a service at an instant of time. Complex computer systems such as those deployed in telecommunications infrastructure today require a high level of availability, typically 99.999% (five nines) of the time, which amounts to just over five minutes of downtime over a year of continuous operation. This poses a significant challenge for those who need to develop an already complex system with the added expectation that services must be available even in the presence of some failures in the underlying system.
In this chapter, we focus on the definitions, concepts, principles, and means to achieving service availability. We also explain all the conceptual underpinning needed by the readers in understanding the remaining parts of this book.
1.2 Why Service Availability?
In this section, we examine why the study on service availability is important. It begins with a dossier on unavailability of services and discusses the consequences when the expected services are not available. The issues and challenges related to service availability are then introduced.
1.2.1 Dossier on Unavailability of Service
Service availability—what is it? Before we delve into all the details, perhaps we could step back and ask why service availability is important. The answer lies readily from the consequences when the desired services are not available. A dossier on the unavailability of services aims to illustrate this point.
Imagine you were one of the one million mobile phone users in Finland, who was affected by a widespread disturbance of a mobile telephone service [1] and had problems receiving your incoming calls and text messages. The interrupt of service, reportedly caused by a data overload in the network, lasted for about seven hours during the day. You could also picture yourself as one of the four million mobile phone subscribers in Sweden when a fault, although not specified, had caused the network to fail and unable to provide you with mobile phones services [2]. The disruption lasted for about twelve hours, which began in the afternoon and continued until around midnight.
Although the reported number of people affected in both cases does not seem to be that high at first glance, one has to put them in the context of their populations. The two countries have respectively 5 and 9 millions of people so the proportion of the affected were considerable.
These two examples have given a somewhat narrow illustration of the consequences when services are unavailable in the mobile communication domain. There are many others and they touch on different kinds of services, and therefore different consequences as a result. One case in point was the financial sector reported that a software glitch, apparently caused by a new system upgrade, had resulted in a 5.5 hour delay in shares trading across the Nordic region including Stockholm, Copenhagen, Helsinki, as well as the Baltic and Icelandic stock exchanges [3]. The consequence was significantly high in terms of the projected financial loss due to the delayed opening of the stock market trading.
Another high-profile and high-impact computer system failure was at the Amazon Web Services [4] for providing web hosting services by means of its cloud infrastructure to many web sites. The failure was reportedly caused by an upgrade of network capacity and lasted for almost four days before the last affected consumer data were recovered [5], although 0.07% of the affected data could not be restored. The consequence of this failure was the unavailability of services to the end customers of the web sites using the hosting services. Amazon had also paid 10-day service credits to those affected customers.
A nonexhaustive list of failures and downtime incidents collected by researchers [6] gives further examples of causes and consequences, which includes categories of data center failures, upgrade-related failures, e-commerce system failures, and mission-critical system failures. Practitioners in the field also maintain a list of service outage examples [7]. These descriptions further demonstrate the relationships between the cause and consequence of failures to providing services. Although some of the causes may be of a similar nature to have made the service unavailable in the first place, the consequences are very much dependent on what the computer system is used for. As described in the list of failure incidents, this could range from the inconvenience of not having the service immediately available, financial loss, to the most serious result of endangering human lives.
It is important to note that all the consequences in the dossier above are viewed from the end-users' perspective, for example, mobile phone users, stockbrokers trading in the financial market and users of web site hosting services. Service availability is measured by an end-user in order to gauge the level of a provided service in terms of the proportion of time it is operational and ready to deliver. This is a user experience of how ready the provided service is. Service availability is a product of the availability of all the elements involved in delivering the service. In the example case of a mobile phone user above, the elements include all the underlying hardware, software, and networks of the mobile network infrastructure.
1.2.2 Issues and Challenges
Lack of a common terminology and complexity have been identified as the issues and challenges related to service availability. They are introduced in this section.
1.2.2.1 Lack of a Common Terminology
Studies on dependability have long been carried out by the hardware as well as software communities. Because of the different characteristics and as a result a different perspective on the subject, dissimilar terminologies have been developed independently by many groups. The infamous observation of ‘one man's error is another man's fault’ is often cited as an example of confusing and sometimes contradictory terms used in the dependability community. The IFIP (International Federation for Information Processing) Working Group WG10.4 on Dependable Computing and Fault Tolerance [8] has long been working on unifying the concepts and terminologies used in the dependability community. The first taxonomy of dependability concepts and terms was published in 1985 [9]. Since then, a revised version was published in [10]. This taxonomy is widely used and referenced by researchers, practitioners, and the like in the field. In this book, we adopt this conceptual framework by following the defined concepts and terms in the taxonomy. On the general computing side, where appropriate, we also use the Institute of Electrical and Electronics Engineers (IEEE) standard glossary of software engineering terminology [11]. The remainder of this chapter presents all the needed definitions, concepts, and principles for a reader to understand the remaining parts of the book.
1.2.2.2 Complexity and Large-Scale Development
Dependable systems are inherently complex. The issues to be dealt with are usually closely intertwined because they have to deal with the normal functional requirements as well as the nonfunctional requirements such as service availability within a single system. Also, these systems tend to be large, such as mobile phone or cloud computing infrastructures as discussed in the earlier examples. The challenge is to manage the sheer scale of development and at the same time, ensure that the delivered service is available at an acceptable level most of the time. On the other hand, there is clearly a common element of service availability implementation across all these wide-ranging application systems. If we can extract the essence of service availability and turn it into some form of general application support, it can then be reused as ready-made template for service availability components. The principle behind this idea is not new. Over almost two decades ago, the use of commercial-off-the-shelf (COTS) components had been advocated as a way of reducing development and maintenance costs by buying instead of building everything from scratch. Since then, many government and business programs have mandated the use of COTS. For example, the United States Department of Defense has included this term into the Federal Acquisition Regulation (FAR) [12].
Following a similar consideration in [13] to combine the complementary notions of COTS and open systems, the Service Availability Forum was established and it developed the first open standards on service availability. Open standards is an important vehicle to ensure that different parts are working together in an ecosystem through well-defined interfaces. The additional benefit of open standards is the reduction of risks in a vendor lock-in for supplying COTS. In the next chapter, the background and motivations behind the creation of the Service Availability Forum and the service availability standards are described. A thorough discussion on the standards' services and frameworks, including the application programming and system administrator and management interfaces, are contained in Part Two of the book.
1.3 Service Availability Fundamentals
This section explains the basic definitions, concepts, and principles involving service availability without going into a specific type of computer system. This is deemed appropriate as the consequences of system failures are application dependent; it is therefore important to understand the fundamentals instead of going into every conceivable scenario. The section provides definitions of system, behavior, and service. It gives an overview of the dependable computing taxonomy and discusses the appropriate concepts.
1.3.1 System, Behavior, and Service
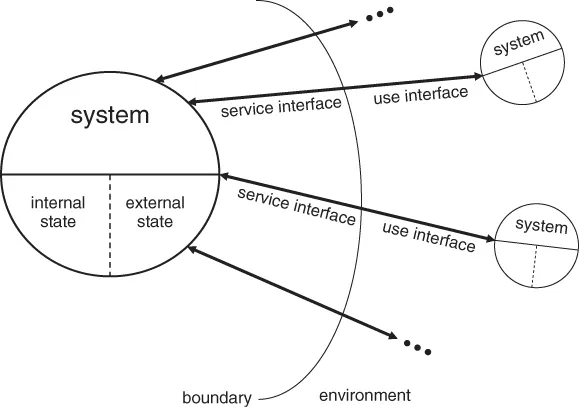
A system can be generically viewed as an entity that intends to perform some functions. Such entity interacts with other systems, which may be hardware, software, or the physical world. Relative to a given system, the other entities with which it interacts are considered as its environment. The system boundary defines the limit of a system and marks the place where the system and its environment interact.
Figure 1.1 shows the interaction between a given system and its environment over the system boundary. A system is structurally composed of a set of components bound together. Each component is another system and this recursive definition stops when a component is regarded as atomic, where further decomposition is not of interest. For the sake of simplicity, the remaining discussions in this chapter related to the properties, characteristics, and design approaches of a system are applicable to a component as well.
The functions of a system are what the system intends to do. They are described in a specification, together with other properties such as the specific qualities (for example, performance) that these functions are expected to deliver. What the system does to implement these functions is regarded as its behavior. It is represented by a sequence of states, some of which are internal to the system while some others are externally visible from other systems over the system boundary.
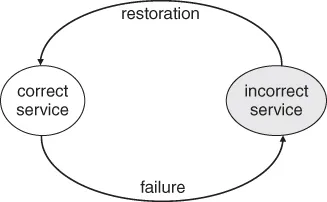
The service provided by a system is the observed behavior at the system boundary between the providing system and its environment. This means that a service user sees a sequence of the provider's external states. A correct service is delivered when the observed behavior matches those of the corresponding function as described in the specification. A service failure is said to have occurred when the observed behavior deviates from those of the corresponding function as stated in the specification, resulting in the system delivering an incorrect service. Figure 1.2 presents the transition from a correct service to service failure and vice versa. The duration of a system delivering an incorrect service is known as a service outage. After the restoration of the incorrect service, the system continues to provide a correct service.
Take a car as an example system. At the highest level, it is an entity to provide a tr...