![]()
Chapter 1
State-of-the-Art Technologies for Large-Scale Computing
Florian Feldhaus and Stefan Freitag
Dortmund University of Technology, Dortmund, Germany
Chaker El Amrani
Université Abdelmalek Essaâdi, Tanger, Morocco
1.1 INTRODUCTION
Within the past few years, the number and complexity of computer-aided simulations in science and engineering have seen a considerable increase. This increase is not limited to academia as companies and businesses are adding modeling and simulation to their repertoire of tools and techniques. Computer-based simulations often require considerable computing and storage resources. Initial approaches to address the growing demand for computing power were realized with supercomputers in 60 seconds. Around 1964, the CDC6600 (a mainframe computer from Control Data Corporation) became available and offered a peak performance of approximately 3 × 106 floating point operations per second (flops) (Thornton, 1965). In 2008, the IBM Roadrunner1 system, which offers a peak performance of more than 1015 flops, was commissioned into service. This system was leading the TOP500 list of supercomputers2 until November 2009.
Supercomputers are still utilized to execute complex simulations in a reasonable amount of time, but can no longer satisfy the fast-growing demand for computational resources in many areas. One reason why the number of available supercomputers does not scale proportional to the demand is the high cost of acquisition (e.g., $133 million for Roadrunner) and maintenance.
As conventional computing hardware is becoming more powerful (processing power and storage capacity) and affordable, researchers and institutions that cannot afford supercomputers are increasingly harnessing computer clusters to address their computing needs. Even when a supercomputer is available, the operation of a local cluster is still attractive, as many workloads may be redirected to the local cluster and only jobs with special requirements that outstrip the local resources are scheduled to be executed on the supercomputer.
In addition to current demand, the acquisition of a cluster computer for processing or storage needs to factor in potential increases in future demands over the computer’s lifetime. As a result, a cluster typically operates below its maximum capacity for most of the time. E-shops (e.g., Amazon) are normally based on a computing infrastructure that is designed to cope with peak workloads that are rarely reached (e.g., at Christmas time).
Resource providers in academia and commerce have started to offer access to their underutilized resources in an attempt to make better use of spare capacity. To enable this provision of free capacity to third parties, both kinds of provider require technologies to allow remote users restricted access to their local resources. Commonly employed technologies used to address this task are grid computing and cloud computing. The concept of grid computing originated from academic research in the 1990s (Foster et al., 2001). In a grid, multiple resources from different administrative domains are pooled in a shared infrastructure or computing environment. Cloud computing emerged from commercial providers and is focused on providing easy access to resources owned by a single provider (Vaquero et al., 2009).
Section 1.2 provides an overview of grid computing and the architecture of grid middleware currently in use. After discussing the advantages and drawbacks of grid computing, the concept of virtualization is briefly introduced. Virtualization is a key concept behind cloud computing, which is described in detail in Section 1.4. Section 1.5 discusses the future and emerging synthesis of grid and cloud computing before Section 1.7 summarizes this chapter and provides some concluding remarks.
1.2 GRID COMPUTING
Foster (2002) proposes three characteristics of a grid:
1. Delivery of nontrivial qualities of service
2. Usage of standard, open, general-purpose protocols and interfaces
3. Coordination of resources that are not subject to centralized control
Endeavors to implement solutions addressing the concept of grid computing ended up in the development of grid middleware. This development was and still is driven by communities with very high demands for computing power and storage capacity. In the following, the main grid middleware concepts are introduced and their implementation is illustrated on the basis of the gLite3 middleware, which is used by many high-energy physics research institutes (e.g., CERN). Other popular grid middleware include Advanced Resource Connector (ARC4), Globus Toolkit,5 National Research Grid Initiative (NAREGI6), and Platform LSF MultiCluster.7
Virtual Organizations. A central concept of many grid infrastructures is a virtual organization. The notion of a virtual organization was first mentioned by Mowshowitz (1997) and was elaborated by Foster et al. (2001) as “a set of the individuals and/or institutions defined by resource sharing rules.”
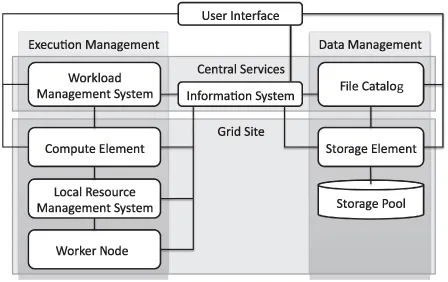
Virtual organization is used to overcome the temporal and spatial limits of conventional organizations. The resources shared by a virtual organization are allowed to change dynamically: Each participating resource/institution is free to enter or leave the virtual organization at any point in time. One or more resource providers can build a grid infrastructure by using grid middleware to offer computing and storage resources to multiple virtual organizations. Resources at the same location (e.g., at an institute or computing center) are forming a (local) grid site. Each grid site offers its resources through grid middleware services to the grid. For the management and monitoring of the grid sites as well as the virtual organizations, central services are required. The main types of service of a grid middleware may be categorized into (Fig. 1.1) (Foster, 2005; Burke et al., 2009) the following:
- Execution management
- Data management
- Information services
- Security
Execution Management. The execution management services deal with monitoring and controlling compute tasks. Users submit their compute tasks together with a description of the task requirements to a central workload management system (WMS). The WMS schedules the tasks according to their requirements to free resources discovered by the information system. As there may be thousands of concurrent tasks to be scheduled by the WMS, sophisticated scheduling mechanisms are needed. The simulation and analysis of the corresponding scheduling algorithms has become an important research area in its own right (Section 1.6).
Each grid site needs to run a compute element that is responsible for user authentication at the grid site and to act as an interface between local resources and the grid. The compute element receives compute tasks from the WMS and submits them to a local resource management system,8 which then schedules the tasks to be executed on a free worker node.
With the LCG9 and the CREAM10 compute elements (Aiftimiei et al., 2010), the gLite middleware currently offers two choices for this task. Whereas the LCG is the standard compute element of gLite, the CREAM compute element was developed to be more lightweight and also allows direct job submission if mechanisms other than the central gLite WMS should be used for job scheduling and resource matching.
Data Management. Besides offering potentially powerful computing resources, a grid may also provide storage capacity in the form of storage elements.
With the Disk Pool Manager (DPM) (Abadie et al., 2007), the CERN Advanced STORage manager (CASTOR)11 and dCache,12 gLite currently supports three storage services. All of these are able to manage petabytes of storage on disk and/or tape. Retrieving and storing data are possible via various protocols, for example, dcap, xrootd,13 gridFTP, and SRM (Badino et al., 2009). The LCG storage element defines the minimum set of protocols that have to be supported to access the storage services.
For gLite, the central LCG File Catalog enables virtual organizations to create a uniform name space for data and to hide the physical data location. This is achieved by using logical file names that are linked to one or more physical file names (consisting of the full qualified name of the storage element and the absolute data path for the file on this specific storage element). Replicas of the data can be created by copying the physical files to multiple storage elements and by registering them under one unique logical file name in the LCG File Catalog. Thus, the risk of data loss can be reduced.
Information System. The information system discovers and monitors resources in the grid. Often the information system is organized hierarchically. The information about local resources is gathered by a service at each grid site and then sent to a central service. The central service keeps track of the status of all grid services and offers an interface to perform queries. The WMS can query the information to match resources to compute tasks.
For gLite, a system based on the Lightweight Directory Access Protocol, is used. The Berkeley Database Information Index (BDII) service runs at every site (siteBDII) and queries all loca...