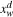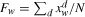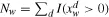![]()
PART 1
Information Retrieval
![]()
Chapter 1
Probabilistic Models for Information Retrieval 1
In this chapter, we wish to present the main probabilistic models for information retrieval. We recall that an information retrieval system is characterized by three components which are as follows:
1) a module for indexing queries;
2) a module for indexing documents;
3) a module for matching documents and queries.
Here, we are not interested in the indexing modules, which are the subjects of development elsewhere (see for example [SAV 10]). We are interested only in the matching module. In addition, among all the information retrieval models, we will concentrate only on the probabilistic models, as they are considered to be the strongest performers in information retrieval and have been the subject of a large number of developments over recent years.
1.1. Introduction
Information Retrieval (IR) organizes collections of documents and responds to user queries by supplying a list of documents which are deemed relevant for the user’s requirements. In contrast to databases, (a) information retrieval systems process non-structured information, such as the contents of text documents, and (b) they fit well within a probabilistic framework, which is generally based on the following assumption:
Assumption 1. The words and their frequency in a single document or a collection of documents can be considered as random variables. Thus, it is possible to observe the frequency of a word in a corpus and to study it as a random phenomenon. In addition, it is possible to imagine a document or query as the result of a random process.
Initial IR models considered words as predicates of first order logic. From this point of view, a document is considered to be relevant if it implies, in the logical sense, the query. Later, vector space models represented documents in vector spaces the axes of which correspond to different indexing terms. Thus, the similarity between a document and a query can be calculated by the angle between the two associated vectors in the vector space. Beyond the Boolean and vector representation, the probabilistic representation provides a paradigm that is very rich in models. For example, it is possible to use different probability laws for modeling the frequency of words.
In all these models, a pre-processing stage is necessary to achieve a useful representation of the documents. This pre-processing consists of filtering the words that are used frequently (empty words), then normalizing the surface form of the words (removing conjugations and plurals) and then finally counting, for each term, the number of occurrences in a document. Consider for example the following document (extracted from “The Crow and the Fox”, by Jean de la Fontaine):
“Mr Crow, perched on a tree,
Holding a cheese in his beak.
Mr Fox, enticed by the smell,
This is what he said:
Well, hello, Mr Crow
How lovely you are! How handsome you seem!”
The filtering of empty words leads to the removal of words such as “a” and “the”, etc. Afterward, the word occurrences are counted: the term Crow occurs twice in this document, whereas the term cheese appears once. We can thus represent a document by a vector, the coordinates of which correspond to the number of occurrences of a particular term, and a collection of documents by a group of such vectors, in matrix form.
In all the models, we shall see that the number of occurrences of different words are considered to be statistically independent. Thus, we can suppose that the random variable corresponding to the number of occurrences of cheese is independent of that of the random variable for Crow. We define the random variable associated with the word w as Xw. A document is a multi-varied random variable noted Xd. The definitions used in this chapter are summarized in Table 1.1. These definitions represent those that are more commonly (and more recently) used in information retrieval. We will often refer to a probability law for predicting the number of occurrences as a frequency law.
Table 1.1. Notations
| Notation | Description |
| RSV(q, d) | Retrieval status value: score of document d for query q |
| qw | Number of occurrences of a term w in the query q |
| Number of occurrences of a term w in the document d |
| N | Number of documents in the collection |
| M | Number of indexing terms |
| Fw | Average frequency of |
| Nw | Document frequency of w: |
| zw | zw = Fw or zw = Nw |
| ld | Document length d |
| lc | Length of collection |
| m | Average length of document |
| Xw | Random variable associated with the word w |
| Xd | Multivariate random variable associated with the document d |
Historically, we can classify the probabilistic models for information retrieval under three main categories:
1) Probability ranking principle
These models assume that for a query there exists both a class of relevant documents and a class of non-relevant documents. This idea leads to ordering the documents according to the probability of relevance of the document P(Rq = 1|Xd). This principle will be presented in section 1.3. Different frequency laws on the frequency classes of documents thus generate different models. The major model in this family is BM25 or Okapi. We shall ...