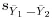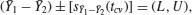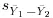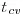The Second Edition of Analysis of Covariance and Alternatives sheds new light on its topic, offering in-depth discussions of underlying assumptions, comprehensive interpretations of results, and comparisons of distinct approaches. The book has been extensively revised and updated to feature an in-depth review of prerequisites and the latest developments in the field.
The author begins with a discussion of essential topics relating to experimental design and analysis, including analysis of variance, multiple regression, effect size measures and newly developed methods of communicating statistical results. Subsequent chapters feature newly added methods for the analysis of experiments with ordered treatments, including two parametric and nonparametric monotone analyses as well as approaches based on the robust general linear model and reversed ordinal logistic regression. Four groundbreaking chapters on single-case designs introduce powerful new analyses for simple and complex single-case experiments. This Second Edition also features coverage of advanced methods including:
- Simple and multiple analysis of covariance using both the Fisher approach and the general linear model approach
- Methods to manage assumption departures, including heterogeneous slopes, nonlinear functions, dichotomous dependent variables, and covariates affected by treatments
- Power analysis and the application of covariance analysis to randomized-block designs, two-factor designs, pre- and post-test designs, and multiple dependent variable designs
- Measurement error correction and propensity score methods developed for quasi-experiments, observational studies, and uncontrolled clinical trials
Thoroughly updated to reflect the growing nature of the field, Analysis of Covariance and Alternatives is a suitable book for behavioral and medical scineces courses on design of experiments and regression and the upper-undergraduate and graduate levels. It also serves as an authoritative reference work for researchers and academics in the fields of medicine, clinical trials, epidemiology, public health, sociology, and engineering.