
Statistik verstehen, nicht rechnen
Band 1: Beschreibende Statistik
- 223 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
About this book
Der Deutsche trinkt im Jahr durchschnittlich 5 Liter Hochprozentiges. Jeder? Auch Kinder und Bewohner eines Altenheimes? Sind Kokosnüsse gefährlicher als Haie? 28% der Führungskräfte gaben an, dass ihnen das Aussehen ihrer Angestellten wichtig ist. Sterben die Bienen demnächst aus? Solche Aussagen richtig einzuordnen, fällt vielen schwer, obwohl solide und anwendungsbezogene Grundkenntnisse der Statistik in Alltag und Beruf unerlässlich sind. Der Autor ist ein erfahrener Dozent und erklärt im vorliegenden Sachbuch ebenso unterhaltsam wie verständlich die Grundlagen der beschreibenden (deskriptiven) Statistik, die er anhand zahlreicher Beispiele praxisnah aufbereitet. Dabei verzichtet er auf die Herleitung umfangreicher Formeln und Methoden, die nötigen Berechnungen können und sollen ohne Taschenrechner nachvollzogen werden. Er vergisst auch nicht, den Leser auf typische Anwendungsfehler hinzuweisen.
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app.
Information
1 Nur eine Größe interessiert uns – eindimensionale Verteilungen

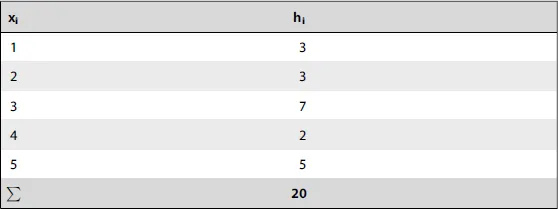
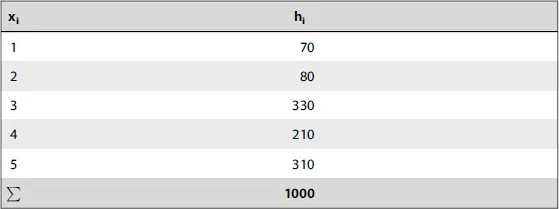
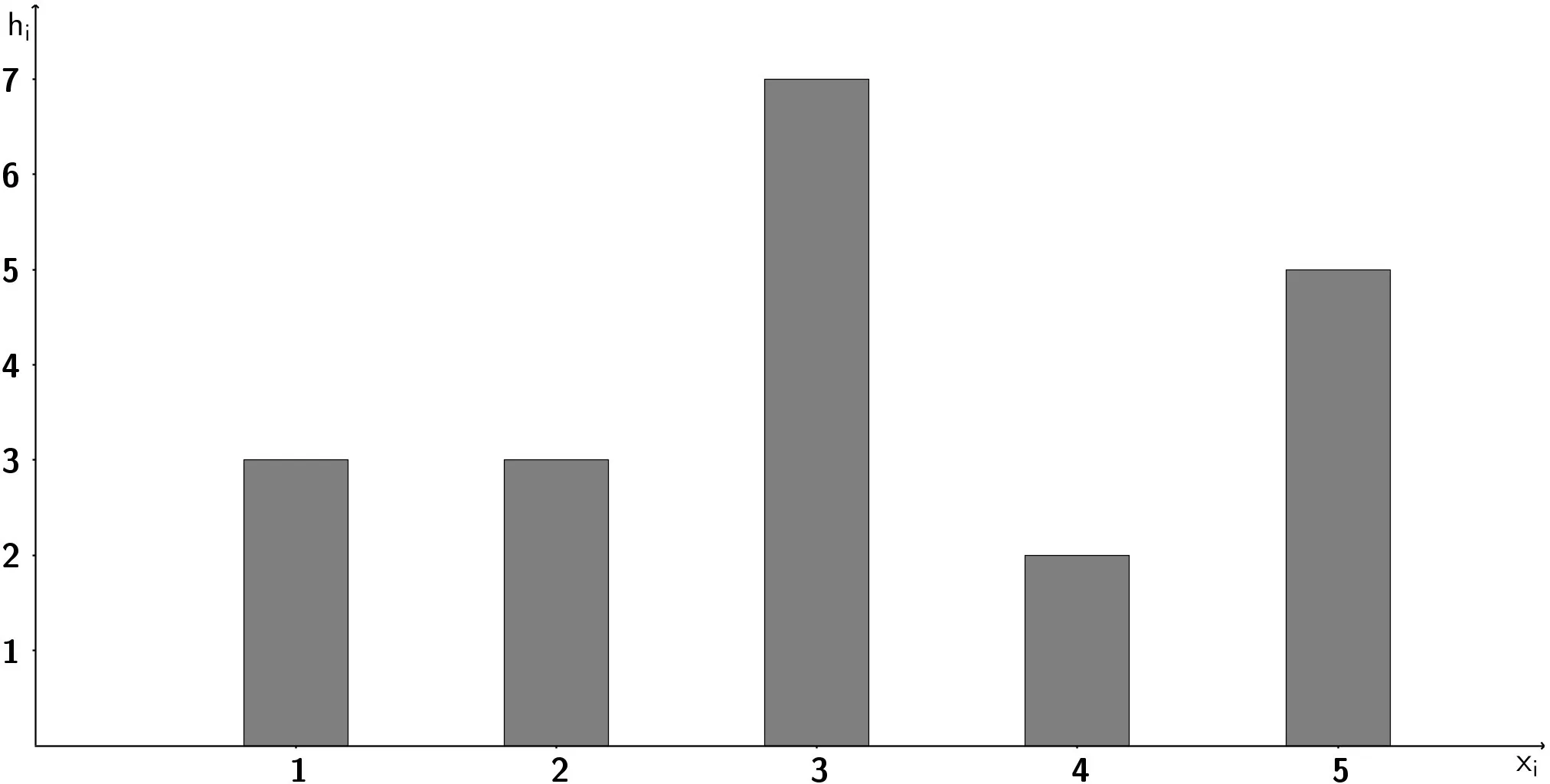
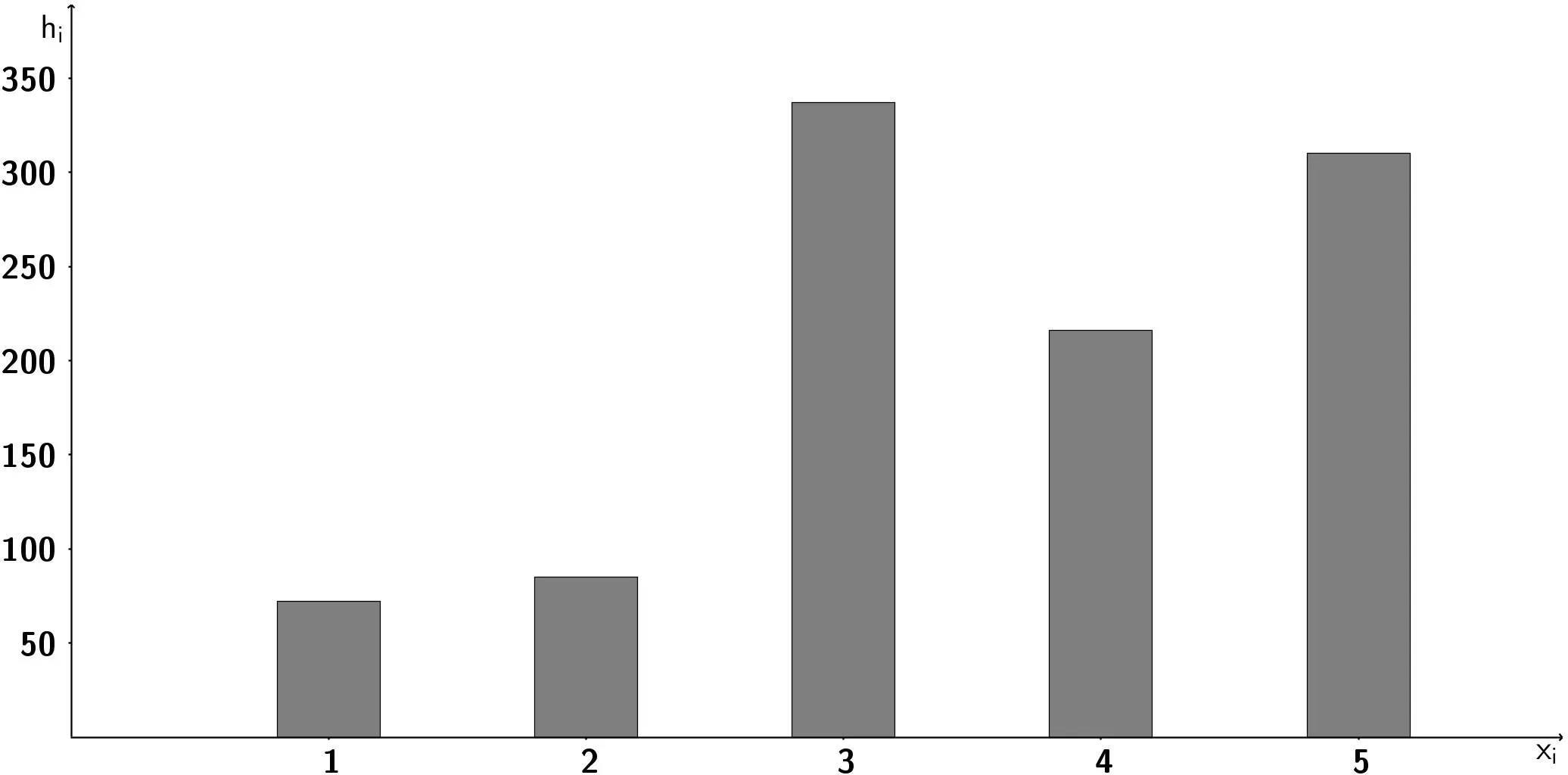
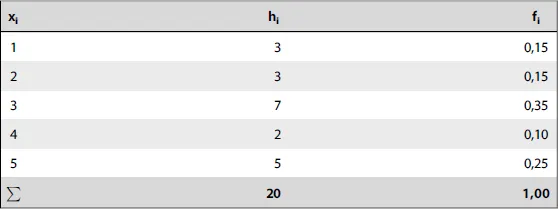
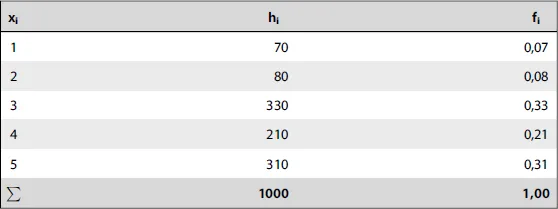
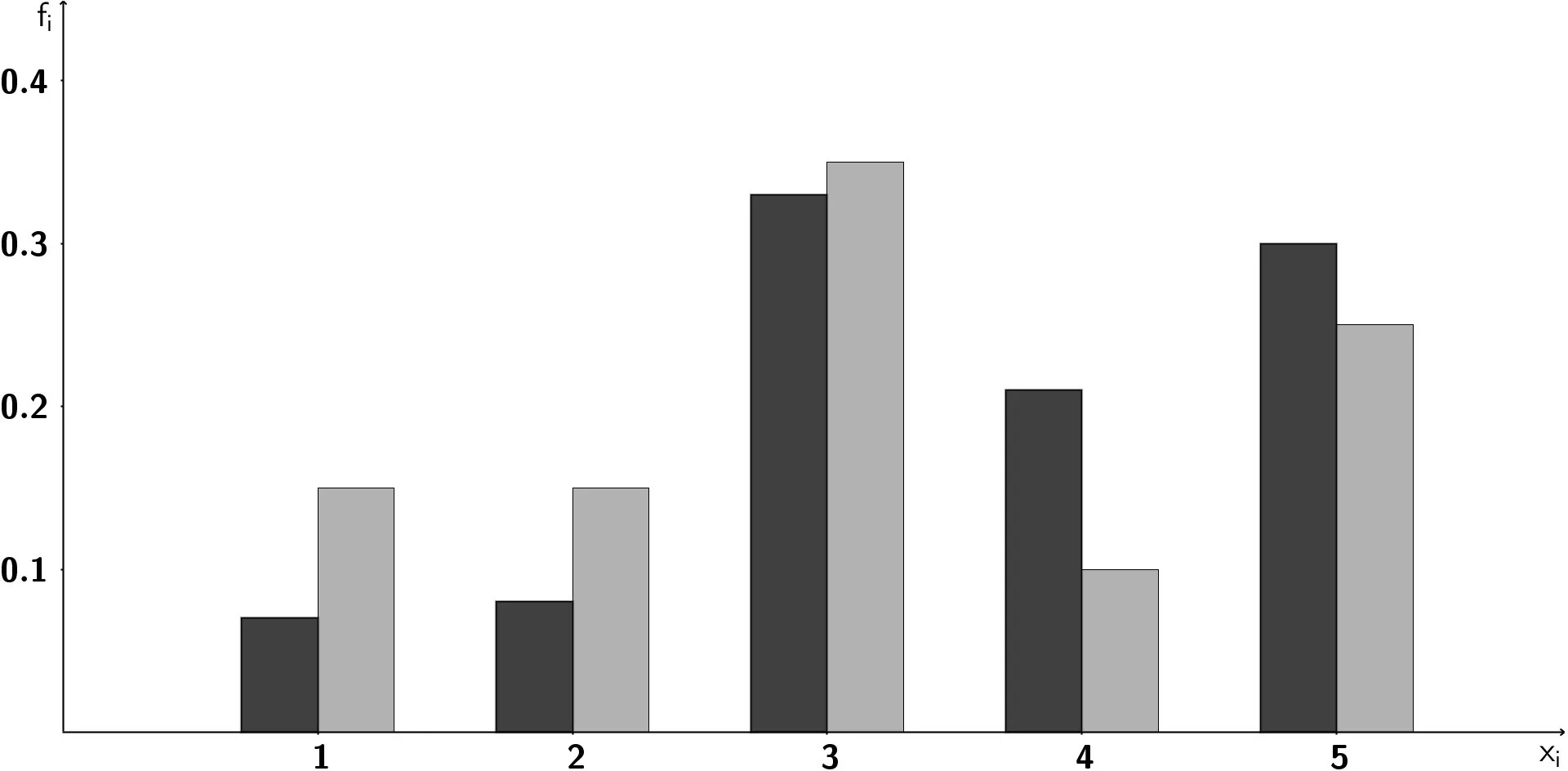

Table of contents
- Deckblatt
- Titelseite
- Impressum
- Inhalt
- Ein Vorwort, das man lesen sollte
- 0 Statistik ist überall – eine Einführung
- 1 Nur eine Größe interessiert uns – eindimensionale Verteilungen
- 2 Die Abhängigkeit zwischen mehreren Größen – mehrdimensionale Verteilungen
- 3 So stehen zwei Größen zueinander – Arten von Indizes
- 4 Epilog: Plötzlich ist man arm
- Anhang 1: Eine Übung zur vollständigen Berechnung von Lage- und Streuungsparametern
- Anhang 2: Eine Übung zur vollständigen Regressions- und Korrelationsberechnung
- Anhang 3: Eine Übung zur vollständigen Indexberechnung
- Stichwortverzeichnis