L'organizzazione di basi di dati con l'utilizzo dei vari software che, a partire dagli anni '70 del secolo scorso, si sono via via perfezionati fino a diventare utilizzabili anche sui personal computer è per lo più considerato un compito da esperti informatici. I meno esperti, tuttavia talmente evoluti da saper utilizzare un foglio di calcolo, arrivano magari a catalogare le loro raccolte di libri o di DVD su tabelle create con questo strumento, che, peraltro, contiene funzioni di database adatte a strutturare, ordinare, ricercare, modificare dati contenuti nelle sue tabelle. I risultati che si ottengono per questa via non sono però certamente all'altezza di ciò che si può ottenere utilizzando un serio DBMS (Data Base Management System) come, stando a quelli più diffusi, i software commerciali DB2, Oracle, Access e i software liberi open source MySQL, SQLite e PostgreSQL. Tra tutti questi, SQLite, da considerarsi neanche solo software libero ma addirittura di pubblico dominio, penso sia il più diffuso in assoluto a causa di una ottimale combinazione tra facilità d'uso, basso impiego di risorse e qualità del risultato. Certamente ha dei limiti, ma sono limiti entro i quali si possono tranquillamente collocare le esigenze elaborative di un qualsiasi privato cittadino e buona parte di quelle di un'impresa. Ha anche il pregio di poter essere utilizzato su personal computer, su tablet e su smartphone. Ma, soprattutto, non richiede abilità significativamente superiori a quelle richieste per sviluppare una tabella di dati su foglio di calcolo. Questo manualetto lo dimostra.

- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
SQLite, il database per tutti
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Publisher
Vittorio AlbertonieBook ISBN
9788829521265
Year
2018Capitolo 1 - Caratteristiche
Il source code di SQLite è di pubblico dominio e può essere usato senza bisogno di licenza alcuna.
Esiste comunque un'organizzazione che se ne occupa, che rilascia licenze e assistenza a pagamento a chi utilizzi il software in costosi progetti complessi e che non voglia fondare questi progetti su un pubblico dominio che oggi c'è e domani non si sa.
L'organizzazione si chiama Hwaci (pronuncia uàci) e, nonostante il nome, non è giapponese: sta per Hipp, Wyrick & Co., Inc. ed ha sede a Charlotte nel North Carolina. Hipp altro non è che Richard Hipp, l'inventore del software, la cui prima stesura risale al 2000, e Wyrick altro non è che la di lui moglie Ginger Wyrick.
Tutto in famiglia per una minuscola libreria software il cui kernel, scritto in linguaggio C, occupa poche centinaia di kB e che, con tutti gli accessori del caso, non occupa più di 5 mega sul nostro computer.
E questa piccola libreria si è rivelata il più efficiente motore di database che esista ed è diventato il database più diffuso al mondo.
Il limite principale lo abbiamo visto in premessa: non è un database client/server. Questo, tuttavia, può risultare un vantaggio, più che un limite. L'altro limite sta nel non riuscire a gestire database superiori a 2 TB (cioè 2 mila miliardi di byte), che penso, tuttavia, siano più che sufficienti per le esigenze di moltissima gente e di moltissime imprese.
I vantaggi vanno dal non essere un database client/server quando questa impostazione non serve e sarebbe ridondante per le nostre esigenze, al riunire in un unico file tutto il database, qualunque sia il numero di tabelle di cui è composto 1.
SQLite è dotato di un suo linguaggio specifico per l'esecuzione di determinate operazioni e, fatta eccezione per alcuni comandi di raro utilizzo, riconosce i comandi del linguaggio SQL, che è lo standard per operare con i database (Structured Query Language).
1 Occorre riconoscere che questi vantaggi li ritroviamo anche nel programma di gestione di database Access della Microsoft. Ma il paragone con Access è perdente, per Access, su tutti gli altri fronti: dal costo alla flessibilità di utilizzo.
Capitolo 2 - Installazione
La versione corrente di SQLite si chiama sqlite3.
SQLite praticamente funziona su tutti i sistemi operativi; limitandomi a quelli più vicini a noi ricordo Linux, Windows, Mac OSX, Android, iOS e VSIX.
Per quanto riguarda apparecchiature equipaggiate Android non abbiamo nemmeno il disturbo di installarlo in quanto è già presente e così dovrebbe essere per tablet e smartphone equipaggiati con altri sistemi (iOS per quanto riguarda i prodotti Apple e VSIX per quanto riguarda Windows Phone).
Anche sui computer dovrebbe essere già installato insieme al sistema operativo. Per averne conferma basta lanciare il comando sqlite3 e vedere cosa succede.
In ogni modo, dal sito https://sqlite.org/ possiamo scaricare la versione adatta al nostro sistema operativo: nel momento in cui scrivo l'ultima nata è la 3.25.2, rilasciata il 25 settembre 2018. Se usiamo Linux troviamo certamente la versione più adatta alla distro che abbiamo installato nel relativo repository.
Sullo stesso sito troviamo tutta la documentazione su SQLite, fatta molto bene ma solo in lingua inglese.
Capitolo 3 - Uso di SQLite a riga di comando
Una volta installato, sqlite3, da solo, ci consente di creare e gestire un database senza bisogno di ricorrere ad altri programmi.
Essendo, come ho detto nel precedente Capitolo 1, un piccolissimo programma senza fronzoli e ridotto all'essenziale, se vogliamo usarlo da solo dobbiamo fare il sacrificio di scendere al suo basso livello e richiederne le prestazioni usando il linguaggio suo proprio attraverso il primordiale sistema dell'interfaccia a riga di comando.
L'interfaccia a riga di comando si basa su una interazione di tipo testuale tra utente ed elaboratore, che avviene attraverso l'uso della sola tastiera del computer per impartire istruzioni a questo, come si faceva un tempo, quando si dialogava con grossi mainframe, magari collocati in un luogo diverso da quello in cui lavorava l'utente, con apparecchiature prive di capacità elaborativa, chiamate terminali. Non a caso le interfacce a riga di comando che sono rimaste nei moderni computer si chiamano, pure loro, almeno per chi proviene dalla cultura informatica di quei tempi, terminali. E i programmi che ci propongono questo tipo di interfaccia sui moderni personal computer sono degli emulatori di terminale: in Linux e in Mac OS X, data la provenienza di entrambi i sistemi operativi dal sistema Unix, si chiamano terminale e ci vengono proposti nei menu delle applicazioni e in Windows si chiama prompt dei comandi e, ove non proposto nel menu, si può attivare con il comando cmd.
La seguente figura 3.1 mostra il terminale del computer su cui sto lavorando, equipaggiato Linux
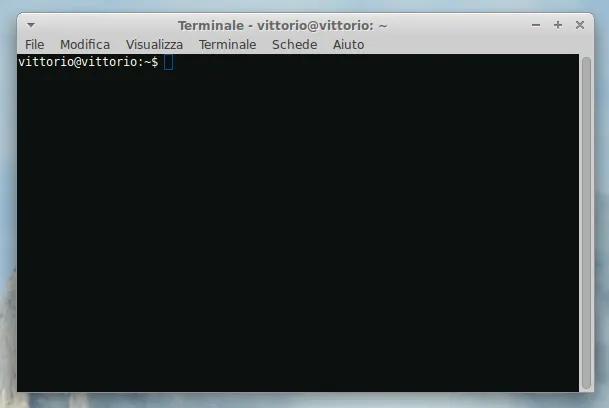
Figura 3.1: Terminale di un sistema Linux Ubuntu
Per avviare il programma SQLite dobbiamo scrivere nella prima riga del terminale, appena dopo il simbolo $ che vediamo nella figura, il comando
sqlite3
e nella seguente figura 3.2 vediamo il risultato.
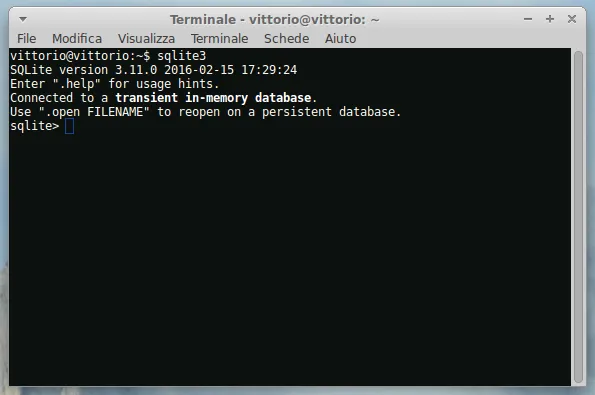
Figura 3.2: Prompt di sqlite3 in un terminale Linux Ubuntu
Nel terminale è comparso il prompt per i comandi SQLite, con cui veniamo avvertiti che SQLite è pronto (prompt) per ricevere comandi e scrivendo sulla riga che comincia con
sqlite>
possiamo chiedere a SQLite di fare ciò che ci serve.
Per chiederlo dobbiamo utilizzare un linguaggio che SQLite comprenda: il linguaggio SQL (Structured Query Language), quello che tutti i programmi di gestione di database comprendono, integrato con alcuni comandi speciali tipici del programma SQLite, detti comandi puntati, in quanto vengono impartiti preceduti da un punto.
L'inserimento dei comandi può indifferentemente avvenire con lettere maiuscole o minuscole. I comandi si possono scrivere su più righe, andando a capo con invio, e terminano con il punto e virgola ;.
I comandi SQL riconosciuti da SQLite non sono proprio tutti ma i non riconosciuti sono quelli che praticamente non si usano mai 2.
L'elenco che segue riguarda i comandi di uso più frequente e ne indico la sintassi per le più comuni applicazioni. Per ulteriori approfondimenti su questi e altri comandi rimando a uno dei numerosi manualetti sul linguaggio SQL che si trovano in libreria o a ricerca su Internet.
CREATE TABLE, per creare una tabella
create table <nome_tabella> (<nome_colonna><tipo_dato>[attributi],<nome_colonna> <tipo_dato>[attributi], ...);
gli attributi sono di inserimento facoltativo e i più frequentemente usati sono:
primary key, che rende il campo la chiave primaria della tabella (quella che serve per instaurare relazioni con altre tabelle);
not null, che rende il campo obbligatoriamente destinato a contenere un dato, contrariamente a quella che sarebbe l'impostazione di default;
autoincrement, destinato solo a campi contenenti un numero per fare in modo che il contenuto del campo si incrementi automaticamente di una unità a partire dal più grande valore già presente 3. Attributo molto utile per la primary key.
DROP TABLE, per cancellare una tabella
drop table <nome_tabella>;
INSERT, per inserire dati in una tabella
insert into <nome_tabella> (<colonna_interessata>, <colonna_interessata>, ...) values (<valore>, <valore>, ...);
Ovviamente i valori vanno elencati nello stesso ordine delle colonne. I valori numerici si inseriscono tali e quali, mentre i valori espressi come testo vanno racchiusi tra semplici apici '.
SELECT, per leggere i dati dalle tabelle del database
select <nome_colonna>, <nome_colonna>, ... from <tabella>, <tabella>, ... where <condizioni>;
Questo è il comando più importante del linguaggio SQL in quanto è l'unico che viene o può convenientemente essere utilizzato anche quando lavoriamo con SQLite non a riga di comando. Per meglio fissare i concetti sulla sua sintassi sottolineo che
• dopo select va inserito, attraverso il nome di colonna, l'elenco dei campi che si vogliono evidenziare nel risultato della ricerca (in gergo la query), separati da virgola e nell'ordine in cui si vogliono evidenziare; non appena vi è il minimo rischio di ambiguità e, comunque, nel caso i campi da evidenziare non corrispondano, nell'ordine o nel numero, a quelli che sono coinvolti nella ricerca, il campo va indicato non semplicemente come nome_colonna ma nella forma più completa tabella.nome_colonna;
• dopo from va inserito l'elenco delle tabelle coinvolte nella ricerca, coinvolte o per l'estrazione di campi da evidenziare o semplicemente perché contengono almeno un elemento utile alla ricerca;
• dopo where, separate eventualmente da and, si indicano le relazioni tra le tabelle coinvolte nella ricerca nella forma
tabella.nome_colonna = tabella.nome_colonna
e poi, sempre con and, si aggiungono le condizioni di ricerca:...
Table of contents
- Introduzione
- Capitolo 1 - Caratteristiche
- Capitolo 2 - Installazione
- Capitolo 3 - Uso di SQLite a riga di comando
- Capitolo 4 - Interfacce grafiche per SQLite
- Capitolo 5 - Uso di SQLite con LibreOffice Base
- Capitolo 6 - Collegamenti attraverso i principali linguaggi di programmazione.
- Capitolo 7 - Conversione di database