
- 410 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Strukturgleichungsmodelle in den Sozialwissenschaften
About this book
Das Buch gibt eine Einführung in die methodologischen und statistischen Grundlagen von Strukturgleichungsmodellen und in deren Handhabung für sozialwissenschaftliche Forschungsfragestellungen. Neben historischen Betrachtungen wird auf Basis verschiedener Erhebungsdesigns eine Einführung in die Pfadanalyse, in Messmodelle, in die konformatorische Faktorenanalyse bis zum allgemeinen Strukturgleichungsmodell vorgenommen. Neben der formalen Darstellung der einzelnen Modellvarianten steht die Erörterung anhand empirischer Beispiele im Vordergrund. Damit kann auch der statistisch weniger versierte Leser die Modellierungen nachvollziehen und auf seine eigenen Fragestellungen übertragen. In den letzten Jahren hat sich in sozialwissenschaftlichen Anwendungsbereichen eine Reihe spezieller Modellierungen mit Strukturgleichungen etabliert. Hierzu gehören Wachstums- und Mischverteilungsmodelle, die in Form eines eigenen Kapitels in die zweite Auflage aufgenommen wurden. Um eine zur EDV-Umgebung des jeweiligen Nutzers passende Auswahl treffen zu können, werden zur Verfügung stehende Programme zur Berechnung von Strukturgleichungsmodellen mit ihren jeweiligen Aktualisierungen erörtert. Weiterführende Hinweise aus dem Internet werden an den jeweiligen Stellen angegeben. Die Literaturliste wurde für die zweite Auflage umfassend ergänzt und aktualisiert.
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app.
Information
1 Einleitung
- Strukturgleichungsmodelle werden nach Formulierung bestimmter inhaltlicher Hypothesen aufgestellt und überprüft. Hiermit wird der konfirmatorische Charakter dieser statistischen Modellbildung hervorgehoben: Das Modell stellt eine Verknüpfung inhaltlicher Zusammenhangshypothesen dar, die anhand empirisch gewonnener Daten getestet werden. Demgegenüber würde ein aus den Daten generiertes Modell eine explorative Modellstrategie unterstützen. Jöreskog und Sörbom (1993a) unterscheiden drei typische Situationen der Modellprüfung:
- Eine strikt konfirmatorische Prüfung, wobei der Forscher einen einzelnen Modelltest vornimmt und die zugrunde liegenden Hypothesen entweder bestätigt oder verwirft.
- Eine konfirmatorische Prüfung von Modellen, bei der der Forscher mehrere alternative Hypothesen überprüft und sich für ein zu akzeptierendes Modell entscheidet.
- Eine modellgenerierte Anwendung, bei der der Forscher ein Anfangsmodell (sogenanntes initial model) spezifiziert und durch schrittweise Modellmodifikation eine Annäherung an die Datenstruktur erreicht.
Die zuletzt genannte Strategie wird in der Praxis am häufigsten durchgeführt und verfolgt zwei Ziele: Zum einen soll das Modell entwickelt werden, das am ehesten den theoretischen Überlegungen entspricht, zum anderen soll auch eine hohe statistische Korrespondenz zwischen dem Modell und den Daten gewährleistet sein. - Strukturgleichungsmodelle können explizit nach gemessenen (sogenannten manifesten) und nicht gemessenen (sogenannten latenten) Variablen unterscheiden und erlauben eine Differenzierung in ein Meß- und ein Strukturmodell. Die explizite Formulierung eines Meßmodells ermöglicht die Berücksichtigung unterschiedlicher Meßqualitäten der manifesten Variablen, vorausgesetzt die latenten Variablen werden über mehr als eine gemessene Variable definiert. Das Meßmodell führt zu einer sogenannten minderungskorrigierten Schätzung der Zusammenhänge zwischen den latenten Variablen. Dies bedeutet, daß sich die Konstruktvalidität der einzelnen Messungen explizit auf die Koeffizienten des Strukturmodells auswirkt. Für das klassische Pfadmodell wird kein Meßmodell formuliert. Die postulierten Beziehungen der manifesten Variablen werden geschätzt, ohne daß die Konstruktvalidität der Messungen geprüft wird. In der Regel werden dadurch die geschätzten Koeffizienten des klassischen Pfadmodells unterschätzt.
- Die meisten Strukturgleichungsmodelle basieren auf Befragungsdaten, die nicht experimentell erhoben werden. Werden experimentelle oder quasi-experimentelle Anordnungen vorgenommen, dann lassen sich über Gruppenbildungen Differenzen der Modellparameter ermitteln. Dabei können Strukturgleichungsmodelle über die Leistungsfähigkeit der klassischen Varianzanalyse hinausgehen, weil eine Differenzierung in manifeste und latente Variablen dort nicht möglich ist.
- Mit Strukturgleichungsmodellen werden große Datensätze analysiert. Es ist relativ schwierig, eine einfache Antwort auf die Frage zu geben, wie hoch die Mindestgröße der Stichprobe sein muß, um stabile Parameterschätzungen in Strukturgleichungsmodellen zu erhalten. Ein deutlicher Zusammenhang besteht zwischen der Stichprobengröße und der Modellkomplexität: Je mehr Parameter im Modell zu schätzen sind, desto größer muß die Datenbasis sein. Des weiteren werden bei Schätzverfahren, die höhere Momente berücksichtigen, größere Stichproben benötigt.
- Varianzen und Kovarianzen bilden in der Regel die Datengrundlage für Strukturgleichungsmodelle. Damit werden zwei Ziele verbunden. Zum einen die Uberprüfung der Zusammenhänge zwischen den Variablen auf Grund der postulierten Hypothesen und zum anderen die Erklärung der Variationen in den abhängigen Variablen. Werden über Kovariaten (z. B. Geschlecht) Gruppen gebildet, dann können Unterschiede der Modellparameter zwischen den Gruppen ermittelt und getestet werden. Mittelwertdifferenzen können zwischen den latenten Variablen geschätzt werden, wenn neben den Varianzen und Kovarianzen auch der Mittelwertvektor der manifesten Variablen zur Verfügung steht.
- Viele statistische Techniken wie die Varianzanalyse, die multiple Regression oder die Faktorenanalyse sind spezielle Anwendungen von Strukturgleichungsmodellen. Schon vor längerer Zeit konnte festgestellt werden, daß die Varianzanalyse (ANO-VA) ein Spezialfall der multiplen Regression ist und beide Verfahren wiederum unter das allgemeine lineare Modell eingeordnet werden können. Zum allgemeinen linearen Modell gehören auch die multivariate Varianzanalyse (MANOVA) und die exploratorische Faktorenanalyse. Alle Varianten des allgemeinen linearen Modells sind in Strukturgleichungsmodelle überführbar. Durch nicht-lineare Parameterrestriktionen können Produktterme in den linearen Gleichungen berücksichtigt werden. Dies führt beispielsweise zu sogenannten Interaktionsmodellen.
- Strukturgleichungsmodelle beschränken sich nicht nur auf kontinuierliche Variablen. Kategoriale Variablen können in den Modellen gleichermaßen berücksichtigt werden. Multinomiale Regressionsmodelle können Teil eines komplexeren Strukturgleichungsmodells sein. Wenn latenten kategoriale Variablen berücksichtigt werden, so haben diese die Funktion, Subgruppen als latente Klassen zu identifizieren und damit Hinweise auf unbeobachtete Heterogenität im Datenmaterial zu geben.
2 Die Entwicklung der statistischen Modellbildung mit Strukturgleichungen
2.1 Einführung
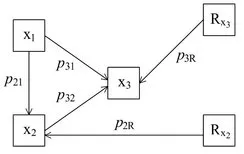
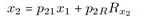
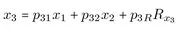
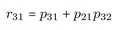
Table of contents
- Titel
- Impressum
- Vorwort
- Inhaltsverzeichnis
- 1 Einleitung
- 2 Die Entwicklung der statistischen Modellbildung mit Strukturgleichungen
- 3 Erhebungsdesigns, Daten und Modelle
- 4 Statistische Grundlagen für Strukturgleichungsmodelle
- 5 Strukturgleichungsmodelle mitgemessenen Variablen
- 6 Meßmodelle
- 7 Die konfirmatorische Faktorenanalyse
- 8 Das allgemeine Strukturgleichungsmodell
- 9 Wachstums- und Mischverteilungsmodelle
- 10 EDV-Programme
- Literaturverzeichnis
- Index