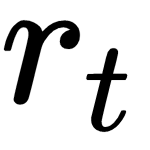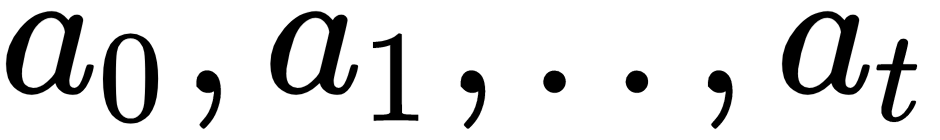Humans and animals learn through a process of trial and error. This process is based on our reward mechanisms that provide a response to our behaviors. The goal of this process is to, through multiple repetitions, incentivize the repetition of actions which trigger positive responses, and disincentivize the repetition of actions which trigger negative ones. Through the trial and error mechanism, we learn to interact with the people and world around us, and pursue complex, meaningful goals, rather than immediate gratification.
Learning through interaction and experience is essential. Imagine having to learn to play football by only looking at other people playing it. If you took to the field to play a football match based on this learning experience, you would probably perform incredibly poorly.
This was demonstrated throughout the mid-20th century, notably by Richard Held and Alan Hein's 1963 study on two kittens, both of whom were raised on a carousel. One kitten was able to move freely (actively), whilst the other was restrained and moved following the active kitten (passively). Upon both kittens being introduced to light, only the kitten who was able to move actively developed a functioning depth perception and motor skills, whilst the passive kitten did not. This was notably demonstrated by the absence of the passive kitten's blink-reflex towards incoming objects. What this, rather crude experiment demonstrated is that regardless of visual deprivation, physical interaction with the environment is necessary in order for animals to learn.
Inspired by how animals and humans learn, reinforcement learning (RL) is built around the idea of trial and error from active interactions with the environment. In particular, with RL, an agent learns incrementally as it interacts with the world. In this way, it's possible to train a computer to learn and behave in a rudimentary, yet similar way to how humans do.
This book is all about reinforcement learning. The intent of the book is to give you the best possible understanding of this field with a hands-on approach. In the first chapters, you'll start by learning the most fundamental concepts of reinforcement learning. As you grasp these concepts, we'll start developing our first reinforcement learning algorithms. Then, as the book progress, you'll create more powerful and complex algorithms to solve more interesting and compelling problems. You'll see that reinforcement learning is very broad and that there exist many algorithms that tackle a variety of problems in different ways. Nevertheless, we'll do our best to provide you with a simple but complete description of all the ideas, alongside a clear and practical implementation of the algorithms.
To start with, in this chapter, you'll familiarize yourself with the fundamental concepts of RL, the distinctions between different approaches, and the key concepts of policy, value function, reward, and model of the environment. You'll also learn about the history and applications of RL.
The following topics will be covered in this chapter:
- An introduction to RL
- Elements of RL
- Applications of RL
![]()
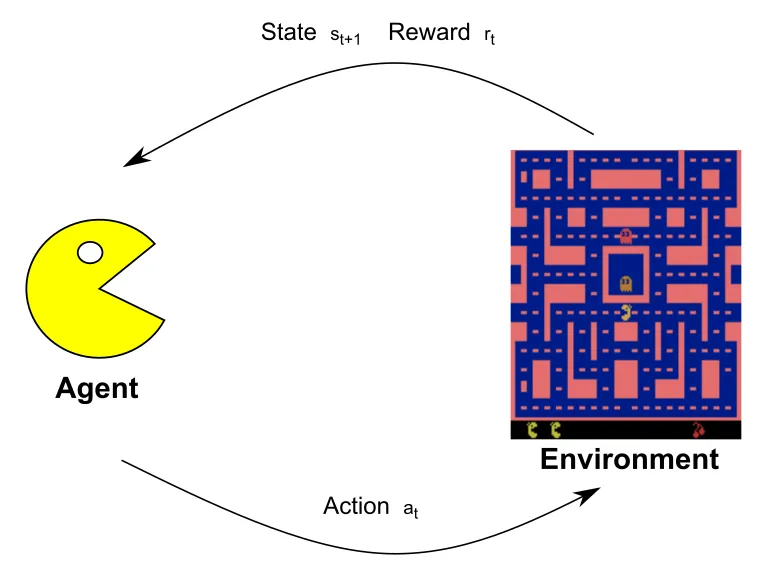
RL is an area of machine learning that deals with sequential decision-making, aimed at reaching a desired goal. An RL problem is constituted by a decision-maker called an Agent and the physical or virtual world in which the agent interacts, is known as the Environment. The agent interacts with the environment in the form of Action which results in an effect. As a result, the environment will feedback to the agent a new State and Reward. These two signals are the consequences of the action taken by the agent. In particular, the reward is a value indicating how good or bad the action was, and the state is the current representation of the agent and the environment. This cycle is shown in the following diagram:
In this diagram the agent is represented by PacMan that based on the current state of the environment, choose which action to take. Its behavior will influence the environment, like its position and that of the enemies, that will be returned by the environment in the form of a new state and the reward. This cycle is repeated until the game ends.
The ultimate goal of the agent is to maximize the total reward accumulated during
its lifetime. Let's simplify the notation:
if
is
the action at
time
and
is the
reward at
time
,
then the agent will take
actions
, to
maximize the sum of all
rewards
.
To maximize the cumulative reward, the agent has to learn the best behavior in every situation. To do so, the agent has to optimize for a long-term horizon while taking care of every single action. In environments with many discrete or continuous states and actions, learning is difficult because the agent should be accountable for each situation. To make the problem harder, RL can have very sparse and delayed rewards, making the learning process more arduous.
To give an example of an RL problem while explaining the complexity of a sparse reward, consider the well-known story of two siblings, Hansel and Gretel. Their parents led them into the forest to abandon them, but Hansel, who knew of their intentions, had taken a slice of bread with him when they left the house and managed to leave a trail of breadcrumbs that would lead him and his sister home. In the RL framework, the agents are Hansel and Gretel, and the environment is the forest. A reward of +1 is obtained for every crumb of bread reached and a reward of +10 is acquired when they reach home. In this case, the denser the trail of bread, the easier it will be for the siblings to find their way home. This is because to go from one piece of bread to another, they have to explore a smaller area. Unfortunately, sparse rewards are far more common than dense rewards in the real world.
An important characteristic of RL is that it can deal with environments that are dynamic, uncertain, and non-deterministic. These qualities are essential for the adoption of RL in the real world. The following points are examples of how real-world problems can be reframed in RL settings:
- Self-driving cars are a popular, yet difficult, concept to approach with RL. This is because of the many aspects to be taken into consideration while driving on the road (such as pedestrians, other cars, bikes, and traffic lights) and the highly uncertain environment. In this case, the self-driving car is the agent that can act on the steering wheel, accelerator, and brakes. The environment is the world around it. Obviously, the agent cannot be aware of the whole world around it, as it can only capture limited information via its sensors (for example, the camera, radar, and GPS). The goal of the self-driving car is to reach the destination in the minimum amount of time while following the rules of the road and without damaging anything. Consequently, the agent can receive a negative reward if a negative event occurs and a positive reward can be received in proportion to the driving time when the agent reaches its destination.
- In the game of chess, the goal is to checkmate the opponent's piece. In an RL framework, the player is the agent and the environment is the current state of the board. The agent is allowed to move the game pieces according to their own way of moving. As a result of an action, the environment returns a positive or negative reward corresponding to a win or a loss for the agent. In all other situations, the reward is 0 and the next state is the state of the board after the opponent has moved. Unlike the self-driving car example, here, the environment state equals the agent state. In other words, the agent has a perfect view of the environment.
![]()
RL and supervised learning are similar, yet different, paradigms to learn from data. Many problems can be tackled with both supervised learning and RL; however, in most cases, they are suited to solve different tasks.
Supervised learning learns to generalize from a fixed dataset with a limited amount of data consisting of examples. Each example is composed of the input and the desired output (or label) that provides immediate learning feedback.
In comparison, RL is more focused on sequential actions that you can take in a particular situation. In this case, the only supervision provided is the reward signal. There's no correct action to take in a circumstance, as in the supervised settings.
RL can be viewed as a more general and complete framework for learning. The major characteristics that are unique to RL are as follows:
- The reward could be dense,...