1 A cognitive neuropsychological approach
Theories and models
An historical perspective
Cognitive neuropsychology first emerged as a coherent discipline in the 1970s as a reaction to the then dominant approach in neuropsychology. This earlier approach to neuropsychology (the ‘classical approach’) sought to characterise the performance of people with aphasia by defining them in terms of their localisation of lesion (see Shallice, 1988, for further discussion of this approach). The aim here was to understand the psychological functions of parts of the cortex by investigating the patterns of deficits shown by individuals with lesions in these areas, and identify syndromes defined in terms of deficits that frequently co-occurred. Over the last 20 years, in the UK at least, cognitive neuropsychology has expanded to become the dominant approach in neuropsychology. Part of the reason is that it moved neuropsychology from being of interest only to those concerned with brain behaviour relationships to a major source of evidence on the nature of normal processing. Another reason is that good cognitive neuropsychology pays real attention to providing accounts that address how individual people with brain lesions behave, often using sophisticated experimental methods to investigate the determinants of their performance.
The origins of cognitive neuropsychology lay in two papers on people with reading disorders by Marshall and Newcombe (1966, 1973). There were two critical features. First, Marshall and Newcombe realised that individual people with reading disorders could show qualitatively different patterns of impairment that would have been obscured by treating them as a group. They described two people who made semantic errors in single-word reading (e.g. NEPHEW → ‘cousin’, CITY → ‘town’; a difficulty described as ‘deep dyslexia’), two people who made regularisation errors (e.g. LISTEN → ‘liston’, ISLAND → ‘izland’; ‘surface dyslexia’), and two people who made primarily visually related errors (e.g. EASEL →‘aerial’, PAMPER →‘paper’; ‘visual dyslexia’). The second feature was that the nature of the individual’s problems could be understood in terms of an information-processing model developed to account for the performance of normal individuals, in this case the ‘dual-route’ model of reading. Three of the essential features of cognitive neuropsychology that were to define the approach were evident here: (1) the realisation that the performance of the individual, not the average of a group, was the important evidence; (2) that the nature of errors was informative; and (3) that the explanations of individuals’ performance were to be couched in terms of information models of normal language processing and not in terms of brain lesions.
The approach developed from an initial focus on reading disorders to encompass a variety of other domains. These include, in a vaguely chronological order, spelling disorders, memory impairments (including both longand short-term memory), semantic disorders, disorders of word retrieval, disorders of object and picture recognition, word-comprehension impairments, disorders of action, executive disorders, sentence-processing impairments, number processing, and calculation. The initial focus, in terms of the people whose disorders were investigated, was on adults with acquired brain lesions, typically following stroke, head injury or, more rarely, brain infections such as herpes simplex encephalitis. The focus has now broadened to encompass developmental disorders, and those disorders found in progressive brain diseases, most prominently the dementias.
Methods have also shown a gradual change. While the early studies were in-depth investigations of single individuals, there has been an increasing use of case series designs where a series of people are investigated using the same set of tasks. The data are not, however, analysed in terms of groups, but rather the focus is on accounting for the patterns of performance of a group of people analysed individually. Here, both differences and similarities between individuals constitute the relevant evidence. Theoretical models have also evolved. While box and arrow models of cognitive architecture remain a major source of explanatory concepts, there has been increasing use of computational models, usually confined to specific domains such as reading, word retrieval or comprehension.
Finally, there has been a resurgence of interest in localisation of cognitive functions in the brain. This has been fuelled by the development of imaging methods such as positron emission tomography and functional magnetic resonance imaging that can be used to measure changes in regional blood flow (reflecting local synaptic activity) in the brain while people are engaged in cognitive tasks. These methods have allowed people to explore how and where the information-processing modules are represented in the brain (e.g. Price, 2001; Price et al., 2003).
Cognitive neuropsychology as a working theoretical model
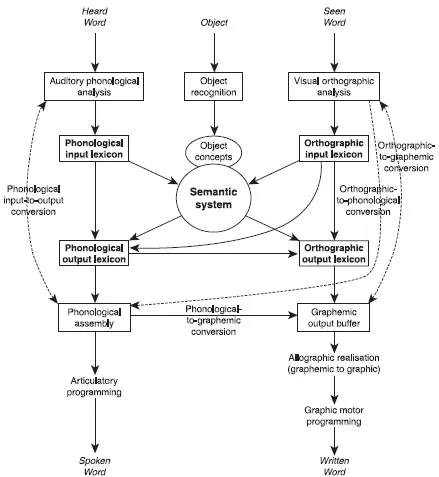
With the abandonment of theories that drew direct links between localising lesions in the brain and characterising deficits in speech and language, the replacement model drew on the components involved in processing information and the interconnections between such components. These were first illustrated in Morton and Patterson’s (1980) version of the logogen model. Morton and Patterson (1980) revised and articulated earlier versions of the logogen model (which date back to Morton, 1969) to account for both the types of errors and the factors influencing reading performance (e.g. word imageability; part of speech) in people with deep dyslexia. This model was a quintessential ‘box and arrow’ processing diagram that specified a number of component processes (the boxes) and how they interrelate (the arrows). The model referred to in this book is illustrated in Figure 1.1 and is (loosely) based on Patterson and Shewell’s (1987) adaptation of the earlier logogen models.
While a model of this kind may appear complex, each of these components appears to be necessary to account for the processing of single words. As Coltheart, Rastle, Perry, Langdon and Ziegler (2001) argued: ‘All the complexities of the model are motivated. If any box or arrow were deleted from it, the result would be a system that would fail in at least one languageprocessing task at which humans succeed’ (p. 211).
Figure 1.1 Language-processing model for single words, based on Patterson and Shewell’s (1987) logogen model.
If different modules and connections (boxes and arrows) in this model can be independently impaired, a very large number of possible patterns of performance may result from a lesion. Given this large number, one clearly cannot assume that any two people will necessarily have the same pattern of performance. The idea, therefore, that aphasia can be grouped into a limited number of identifiable and homogeneous ‘syndromes’ must necessarily fail. This does not, of course, mean that there will not be resemblances between the performances of different people with aphasia; to the extent that they have the same components damaged, this is precisely what we would predict. Nor does it mean that some combinations of symptoms do not appear more frequently than others. It simply means that one cannot group data from people with aphasia together as the differences between individuals are important (Shallice, 1988). Analysis of data from single individuals is the necessary consequence.
Using this kind of model to explain patterns of performance with people with aphasia involves making several assumptions, described and defended in detail by, among others, Caramazza (1986), Shallice (1988) and Coltheart (2001). Coltheart (2001) describes four assumptions:
- Functional modularity. Some, at least, of the components of the cognitive system are modular, meaning that they operate independently, or relatively independently, of other components.
- Anatomical modularity. Some, at least, of the modules of the cognitive system are localised in different parts of the brain. As a result, brain lesions can result in selective information-processing deficits, either by destroying the tissue responsible for particular modules or by disconnecting them. Functional modularity does not necessarily entail anatomical modularity.
- Universality of cognitive systems. This simplifying assumption is that all normal people have the same cognitive systems. This is a plausible assumption for language processing, for example, but is clearly not directly applicable in domains of which some people have no experience, for example music. Note that it is not claimed here that all people will have equal experience and facility in all aspects of their cognitive system, rather that different people do not have radically different cognitive architectures for the same processes.
- Subtractivity. The result of a brain lesion is to destroy, damage or impair one or more components of the normal cognitive system. Damage does not result in new information-processing systems. On the other hand, a person with brain damage may rely on different sources of information to perform a task, but these use processing systems that were available pre-morbidly. For example, a person with a severe face recognition impairment (prosopagnosia) may come to rely on a person’s dress or voice to recognise them. While normal individuals may not rely on these strategies to recognise people, they can do so when necessary.
Models like that in Figure 1.1 are, in this form, radically unspecified. The diagram says nothing about how the processing in the boxes is achieved. Each of the cognitive modules will necessarily have structure and may comprise a whole set of component processes. For example, Figure 1.1 has a box called ‘phonological assembly’. Levelt, Roelofs and Meyer (1999) argue that there are a number of separable processes involved in phonological assembly, including separate spell out of both the segmental and metrical structure. There is evidence that there can be separable impairments of these component processes (Nickels & Howard, 2000).
A working assumption is that any of the modules in the diagram can be lost or damaged as a result of cortical lesions. An individual with aphasia might have damage to one or several modules or the mappings between them. Because of the functional architecture of the brain, some patterns of deficits will be more frequent than others, but because lesions vary both in their precise cortical locations and in the cutting of sub-cortical white matter fibre tracts, identical patterns of deficit in any two people are unlikely. One objective in assessment can be to identify which of the modules and mappings (boxes and arrows) are damaged and which are intact, yielding a concise explanation of the pattern of performance across a range of tasks and materials.
In Chapters 4–8 we describe, in outline only, the nature of the processing in many of the components of the model. We are aware, of course, that we are not putting forward a complete, or even necessarily accurate, model of language processing even just for single words. Our fundamental claim, in the context of this book, is much more modest. It is that the model in Figure 1.1 provides a usable working model of language processing. It provides a level of description that can be used to guide a process of assessment that can identify levels of breakdown and intact and impaired processes in people with aphasia.
Competing models
There are many models of single word processing that can be, and have been, used to account for patterns of language breakdown as well as normal processing. Many of these are task-specific, dealing, for example, with spoken word production (e.g. Foygel & Dell, 2000; Levelt et al., 1999; Rapp & Goldrick, 2000), spoken language comprehension (e.g. Marslen-Wilson, 1987), or semantic representation (e.g. Tyler, Moss, Durrant-Peatfield, & Levy, 2000). Evaluation of such models is beyond the scope of what this book aims to achieve. However, while these models do attempt to provide detailed accounts of representations and processes involved in particular tasks, they provide little information on how different tasks relate to each other. For example, the phonological assembly module in the lexical model of Figure 1.1 is a common output process shared by picture naming, word reading and word repetition. Impairment at this level should result in qualitatively similar patterns of impairment across all three tasks (some quantitative differences may be due to the differing nature of the input to the module). This is the pattern found in many people with phonological deficits in speech production (e.g. Caplan, Vanier, & Baker, 1986; Franklin, Buerk, & Howard, 2002).
Some models do, however, highlight the shared nature of processes and aim to account for patterns of performance across different tasks. In 1979, motivated by patterns of cross-modal repetition priming, Morton had revised the original 1969 logogen model that had a single lexicon for spoken word recognition, spoken word production, written word recognition and written word production, to have the four separate lexicons shown in Figure 1.1 (Morton, 1979a). Allport and Funnell (1981) pointed out that Morton’s priming data only motivated a separation of orthographic and phonological lexicons, and, arguing against the need for the separation into input and output lexicons, suggested that a single phonological lexicon was used for both spoken word recognition and production, and a single orthographic lexicon was used for written word recognition and writing (see also Allport, 1985). There have been discussions about the explanatory adequacy of this proposal centring on a number of issues (see Howard & Franklin, 1988; Monsell, 1987). For example, there are people with deficits apparently at a lexical level in word retrieval with unimpaired recognition of the same words in spoken form (e.g. Howard, 1995) and, conversely, those with a lexical level of deficit in spoken word recognition with relatively unimpaired spoken naming (Howard & Franklin, 1988). This dissociation seems to imply separate input and output phonological lexicons. On the other hand, there have been reports of item-specific difficulties in reading and spelling that may be most easily captured by proposing impairment to a common orthographic lexicon (Behrmann & Bub, 1992).
A computational interactive activation model that also incorporated a single lexicon for word recognition and production was developed by Martin, Dell and their colleagues (Martin, Dell, Saffran, & Schwartz, 1994; Schwartz, Dell, Martin, & Saffran, 1994). In the original form of the model, word comprehension depended on exactly the same components as in word production operating in reverse. They used this to model the pattern of errors in repetition and naming in a single person who made semantic errors in repetition. However, when Dell, Schwartz, Martin, Saffran and Gagnon (1997) tried to use this model to account for the pattern of errors in naming and repetition in a group of further people with aphasia, they found that lesions that captured, with reasonable accuracy, the individuals’ patterns of errors in naming, typically radically underestimated their repetition accuracy. Coupled with demonstrations that the model, in its unlesioned form, was only able to comprehend two-thirds of words correctly, was unable to repeat nonwords, and could not account for the relationships between accuracy in comprehension and production found in people with aphasia (Nickels & Howard, 1995b), Dell et al. (1997) abandoned this as a model of comprehension and repetition. Even its ability to account for the patterns of errors found in naming with people with aphasia has been challenged (Ruml & Caramazza, 2000). As a result of these problems, the current version of this model by Foygel and Dell (2000) restricts its aims simply to accounting for patterns of errors in picture naming.
Finally, we need to consider the ‘triangle model’ developed by McClelland, Plaut, Seidenberg, Patterson and their colleagues (Plaut, McClelland, Seidenberg, & Patterson, 1996; Seidenberg & McClelland, 1989). This is a computational model of lexical processing that, like that of Allport and Funnell (1981), has only a single phonological system serving both production and comprehension of spoken words and a single orthographic system for both written input and output. The radical innovation in this model, however, is that there is no lexical representation. A set of units in phonological space, for example, encodes any possible phonological string whether word or nonword. Mappings from phonology to semantics or orthography will have been learned, using a real word vocabulary. During the process of learning, the weights in the connections between the input units and hidden units, and those between hidden units and orthography and semantics, will have been adjusted so that they achieve the correct mappings for the words used to train the model (see Plaut et al., 1996, for a detailed description of this model). Knowledge of the mappings for individual words are not localised in a lexicon, but distributed across all the weights in all the connections between the domains.
The triangle model has been in development since Seidenberg and McClellands’ (1989) proposal. There are two particularly notable achievements that have resulted. Plaut and Shallice (1993) showed that, at least with a limited vocabulary, a model mapping from orthography via semantics to phonology can account for most of the features found in people with deep dyslexia. Plaut et al. (1996) and Plaut (1999) have developed a model of the direct mapping from orthography to phonology for single-syllable words. With the right representations in both the orthographic and phonological domains, this model has enjoyed considerable success in accounting for the phenomena of normal reading and the patterns of deficit found in people with surface and phonological dyslexia. Most radically, the model shows that a single computational mechanism, trained only on a real word vocabulary, is able to generate the correct phonology for both irregular words (e.g. YACHT, PINT) and nonwords (e.g. THORK, SLINT).
Computational models of these kinds present a very interesting new way of understanding how mappings between domains might be implemented. It is important to realise, however, that the capabilities of these models depend critically on how the representations in the input and output domains are coded, as well as features of the architecture of the model such as the numbers of hidden units, and how they are connected. Models of this kind generally find it much easier to learn mappings between domains that are mostly systematic and generalisable, as in the mapping from orthography to phonology (where, for instance, the letter M at input almost always relates to a phoneme /m/ in output). This is because it finds it easiest to learn mappings where similar inputs result in similar outputs (see Plaut & Shallice, 1993). Where, as in the mapping from orthography to semantics, there is no systematicity of this kind, the connectionist model finds this difficult to learn, although, eventually, it can succeed. Children, on the other hand, learn the mapping between new words and their meanings with extraordinary rapidity (Clark, 1993).
These models are currently limited in scope. Both of the implemented models have only feed-forward connections (that is, they use only onedirectional connections between levels), although the overarching triangle model always uses bidirectional connections between domains. Since we know that the architecture of the models is critically impo...