About 10 years ago, the biggest buzz in the IT industry was the term big data. Every major enterprise was racing to harness the mystical powers of massive, yet supposedly manageable, silos of data. Equipped with big data, no problem would prove insurmountable, and all forecasts would be met.
But lately, these forecasts appear to have faded, and the worst-kept secret in the IT industry is that big data is dead – at least as we knew it. This doesn't mean that the volume or growth of data has broken down – or the opposite. It's just the underlying technology that has changed, which means that the architectures of applications that use big data have too.
Take Hadoop as an example, which has been the icon of the big data hype. It was designed based on a set of assumptions that dramatically changed in a short time. One of these assumptions was that, in order to process a large batch of data, network latency was the evil and cloud-native storage simply wasn't an option. At that time, most of the IT industry data was on-premise, so the focus was on avoiding moving around big sets of information. This meant that data was to be co-located in order to compute it efficiently.
Today, this scenario has changed quite a bit: most applications still use large amounts of data, but data is now processed on the fly. That is to say, we now stream data instead of processing the whole dataset multiple times.
Besides this, the network latency barrier has become less of an issue for cloud providers and there are even multiple cloud sources to choose from. Also, companies now have the option to deploy their own private cloud on-premise, leading to new scenarios such as hybrid clouds.
Therefore, the focus is what really changed: today, big data does not merely mean a big quantity of datasets but flexible storage options for a big quantity of data.
This is where containers and, specifically, Kubernetes fits in. In a nutshell, you can think of a container as a packaged application that contains just the libraries that are needed to run it, and Kubernetes is like an orchestrating system that makes sure all the containers have the appropriate resources while managing their life cycle.
Kubernetes runs images and manages containers using Docker. However, Kubernetes can use other engines too (for example, rkt). Since we will be building our applications on top of Kubernetes, we will provide a short overview of its architecture in the next section.
![]()
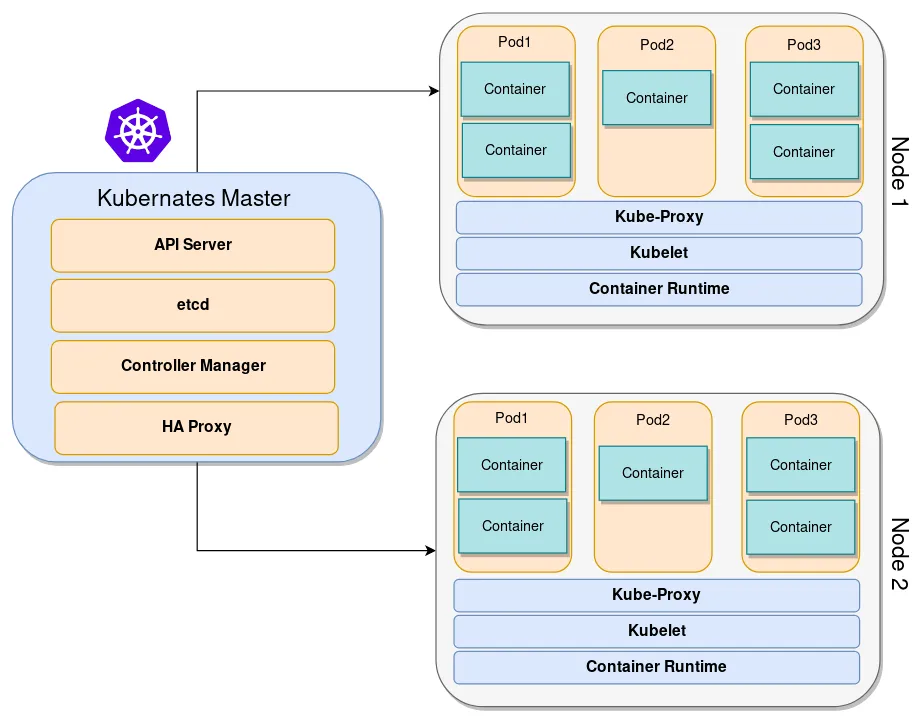
The architecture of Kubernetes is focused around the concept of a loosely coupled, flexible mechanism for service discovery. Like most other distributed middleware platforms, a Kubernetes cluster is composed of one or more master nodes and multiple compute nodes. The following diagram depicts a high-level view of a Kubernetes cluster:
Kubernetes Master nodes essentially make up the brain of the cluster. They are responsible for managing the overall cluster, exposing APIs, and scheduling deployments. Kubernetes nodes (right-hand side of the preceding diagram) contain the services that are needed to run applications in components called Pods.
Each master node contains the following components:
- API Server: This synchronizes and validates the information running in Pods and services.
- etcd: This provides consistent and highly available storage for the cluster data. You can think of etcd as the brain's shared memory.
- Controller Manager server: This checks for changes in the etcd service and uses its API to enforce the desired state.
- HAProxy: This can be added when we're configuring HA masters to balance loads between several master endpoints.
Kubernetes nodes (simply called nodes) can be considered workhorses of a Kubernetes cluster. Each node exposes a set of resources (such as computing, networking, and storage) to your applications. The node also ships with additional components for service discovery, monitoring, logging, and optional add-ons. In terms of infrastructure, you can run a node as a virtual machine (VM) in your cloud environment or on top of bare-metal servers running in the data center.
Each node contains the following components:
- Pod: This allows us to logically group containers and pieces of our application stacks together. A Pod acts as the logical boundary for such containers with shared resources and contexts. Pods can be scaled at runtime by creating Replica sets. This, in turn, ensures that the required number of Pods is always run by the deployment.
- Kubelet: This is an agent that runs on each node in the Kubernetes cluster. It makes sure that the containers are running in a Pod.
- Kube-Proxy: This maintains network rules on nodes to allow network communication between Pods.
- Container Runtime: This is the software that is responsible for running containers. Kubernetes supports multiple container runtimes (such as Docker, containerd, cri-o, and rktlet).
Now that we've covered the basics of the Kubernetes architecture, let's look at the top advantages that it can bring to your organization.
![]()
The advantages that Kubernetes can bring to your organization are as follows:
- Kubernetes greatly simplifies container management. As you have learned, when using Kubernetes, there's no need to manage conta...