
eBook - ePub
Data Lakes
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
About this book
The concept of a data lake is less than 10 years old, but they are already hugely implemented within large companies. Their goal is to efficiently deal with ever-growing volumes of heterogeneous data, while also facing various sophisticated user needs. However, defining and building a data lake is still a challenge, as no consensus has been reached so far. Data Lakes presents recent outcomes and trends in the field of data repositories. The main topics discussed are the data-driven architecture of a data lake; the management of metadata – supplying key information about the stored data, master data and reference data; the roles of linked data and fog computing in a data lake ecosystem; and how gravity principles apply in the context of data lakes. A variety of case studies are also presented, thus providing the reader with practical examples of data lake management.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
1
Introduction to Data Lakes: Definitions and Discussions
As stated by Power [POW 08, POW 14], a new component of information systems is emerging when considering data-driven decision support systems. This is the case because enhancing the value of data requires that information systems contain a new data-driven component, instead of an information-driven component1. This new component is precisely what is called data lake.
In this chapter, we first briefly review existing work on data lakes and then introduce a global architecture for information systems in which data lakes appear as a new additional component, when compared to existing systems.
1.1. Introduction to data lakes
The interest in the emerging concept of data lake is increasing, as shown in Figure 1.1, which depicts the number of times the expression “data lake” has been searched for during the last five years on Google. One of the earliest research works on the topic of data lakes was published in 2015 by Fang [FAN 15].
The term data lake was first introduced in 2010 by James Dixon, a Penthao CTO, in a blog [DIX 10]. In this seminal work, Dixon expected that data lakes would be huge sets of row data, structured or not, which users could access for sampling, mining or analytical purposes.
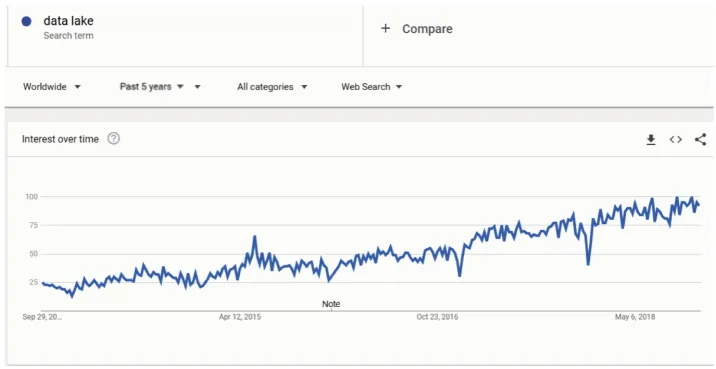
Figure 1.1. Queries about “data lake” on Google
In 2014, Gartner [GAR 14] considered that the concept of data lake was nothing but a new way of storing data at low cost. However, a few years later, this claim was changed2, based on the fact that data lakes have been considered valuable in many companies [MAR 16a]. Consequently, Gartner now considers that the concept of data lake is like a graal in information management, when it comes to innovating through the value of data.
In the following, we review the industrial and academic literature about data lakes, aiming to better understand the emergence of this concept. Note that this review should not be considered as an exhaustive, state of the art of the topic, due to the recent increase in published papers about data lakes.
1.2. Literature review and discussion
In [FAN 15], which is considered one of the earliest academic papers about data lakes, the author lists the following characteristics:
- – storing data, in their native form, at low cost. Low cost is achieved because (1) data servers are cheap (typically based on the standard X86 technology) and (2) no data transformation, cleaning and preparation is required (thus avoiding very costly steps);
- – storing various types of data, such as blobs, data from relational DBMSs, semi-structured data or multimedia data;
- – transforming the data only on exploitation. This makes it possible to reduce the cost of data modeling and integrating, as done in standard data warehouse design. This feature is known as the schema-on-read approach;
- – requiring specific analysis tools to use the data. This is required because data lakes store row data;
- – allowing for identifying or eliminating data;
- – providing users with information on data provenance, such as the data source, the history of changes or data versioning.
According to Fang [FAN 15], no particular architecture characterizes data lakes and creating a data lake is closely related to the settlement of an Apache Hadoop environment. Moreover, in this same work, the author anticipates the decline of decision-making systems, in favor of data lakes stored in a cloud environment.
As emphasized in [MAD 17], considering data lakes as outlined in [FAN 15] leads to the following four limitations:
- 1) only Apache Hadoop technology is considered;
- 2) criteria for preventing the movement of the data are not taken into account;
- 3) data governance is decoupled from data lakes;
- 4) data lakes are seen as data warehouse “killers”.
In 2016, Bill Inmon published a book on a data lake architecture [INM 16] in which the issue of storing useless or impossible to use data is addressed. More precisely, in this book, Bill Inmon advocates that the data lake architecture should evolve towards information systems, so as to avoid storing only row data, but also “prepared” data, through a process such as ETL (Extract-Transform-Load) that is widely used in data warehouses. We also stress that, in this b...
Table of contents
- Cover
- Table of Contents
- Preface
- 1 Introduction to Data Lakes: Definitions and Discussions
- 2 Architecture of Data Lakes
- 3 Exploiting Software Product Lines and Formal Concept Analysis for the Design of Data Lake Architectures
- 4 Metadata in Data Lake Ecosystems
- 5 A Use Case of Data Lake Metadata Management
- 6 Master Data and Reference Data in Data Lake Ecosystems
- 7 Linked Data Principles for Data Lakes
- 8 Fog Computing
- 9 The Gravity Principle in Data Lakes
- Glossary
- References
- List of Authors
- Index
- End User License Agreement
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Data Lakes by Anne Laurent, Dominique Laurent, Cédrine Madera, Anne Laurent,Dominique Laurent,Cédrine Madera in PDF and/or ePUB format, as well as other popular books in Computer Science & Computer Engineering. We have over 1.5 million books available in our catalogue for you to explore.