Research data are the cornerstone of scientific knowledge, learning and innovation and of our quest to understand, explain and develop humanity and the world around us. In the digital age, the generation of research data has grown exponentially, and data are nowadays very easily stored, kept and exchanged around the world. Digital infrastructures and the internet facilitate both the creation of ever larger amounts of research data, as well as their sharing.
Over 66 years ago, Watson and Crick (1953) published the structure of DNA in a single page article in Nature, with no raw data to underpin their findings. More recently, The 1000 Genomes Project Consortium (2010) accompanied their publication of the human genome map in Nature with 4.9 terabases of DNA sequences available through the project website and deposited in dbSNP, the database of single nucleotide polymorphisms (Kiermer, 2011). Genetics research is just one example that shows how the openness and exchange of information – including research data – have changed drastically thanks to technological advances, and how this can rapidly increase the speed of research and discovery to our advantage. Just consider the medical benefits of our growing genetic understanding.
The importance of rapidly sharing research data became very apparent during the recent Ebola and Zika epidemics, where relatively little-known and little-studied viruses caused public health emergencies that required rapid research and action. The World Health Organization called for researchers to share their data rapidly and put in place a protocol to facilitate this (Dye et al., 2016) and numerous health research funders and publishers issued a joint statement calling for all content concerning the Zika virus to be made openly and freely available (Wellcome Trust, 2016).
Since 2000 we have seen a boom in both the drivers of data sharing and the development of human and technological capability to do so. Data sharing is increasingly encouraged or required by research funders and journal publishers, but also from within the research community itself. Research funders want to maximise the scientific outputs and benefits to society from their investments, and making sure that data can be reused for future research plays an important role. They require data plans to ensure maximum quality, sustainability, accessibility and openness of those data. At the same time they fund data infrastructures to facilitate that. Academic publishers demand that the supporting data of scientific papers be accessible for scrutiny or further exploration, as proof that the findings are indeed based on solid data and to enable reproduction of the research. Governments internationally expect transparency in research, and the economic climate makes it desirable for much greater reuse of data to maximise the return on science investments. The scientific community itself moves towards open science and transparency, indicating that lack of access to data impedes scientific progress.
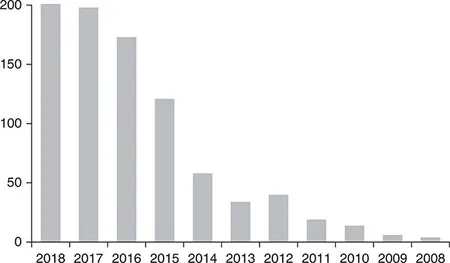
Access to data means that scientific findings can be verified and scrutinised, but also that junior researchers can learn from methods used by more experienced academics. Society also demands access to data to enable businesses to employ new knowledge for the development of tools and applications; to allow organisations to question governmental policies and decisions; and for citizens to contribute to research processes. Citizen science has indeed become immensely popular in the past decade, as can be seen from the spike in publications on citizen science in the last five years (Figure 1.1). Citizens’ involvement in science can be citizens helping to generate data for research, for example through biodiversity observations, or citizens participating in data analysis, for example in Galaxy Zoo.
Data sharing and reusing existing data for new applications, then, require good data management practices. Managing data resources well throughout their lifecycle makes for sustainable data resources. Good data management also has clear benefits for researchers in productivity, avoiding data loss and protecting against data breaches. Good data management also builds trust for people to participate in research activities.
Researchers’ responsibilities towards their research data are therefore changing across all domains of scientific endeavour. Researchers need to improve, enhance and professionalise their research data management skills to meet the challenge of producing the highest quality research outputs and sustainable data in a responsible and efficient way, with the ability to share and reuse such outputs. One would think that the desire for high quality research alone would motivate any researcher to implement good data management practices. That is not necessarily the case, as data management requires skills that are often not taught as part of a standard training programme, as well as time and effort. The promotion of data skills offers a strategic contribution to research capacity-building programmes. Institutions also need high quality research data management to address the ethical and security risks of their data assets. Robust research data management techniques give researchers, data professionals and those involved in supporting research the skills that are required to deal with the rapid, and uneven, developments in the data management environment.
This chapter will guide you through the many facets of managing and sharing data, before the rest of the book steers you step by step towards data proficiency.
Figure 1.1 Number of publications with ‘citizen science’ in title
Source: Clarivate Analytics, 2019
Defining Research Data, Data Management and Data Sharing
Research data are data that are used as primary sources to support technical or scientific enquiry, research, scholarship, or artistic activity, and that are used as evidence in the research process and/or are commonly accepted in the research community as necessary to validate research findings and results. All other digital and non-digital content has the potential of becoming research data. Research data may be experimental data, observational data, operational data, third party data, public sector data, monitoring data, processed data or repurposed data.
Data management comprises the activities of data policies, data planning, data element standardisation, information management control, data synchronisation, data sharing and database development, including practices and projects that acquire, control, protect, deliver and enhance the value of data and information.
Data sharing is the practice of making data available for reuse. This may be done, for example, by depositing the data in a repository and through data publication.
Source: CASRAI, 2018
Research data do not have to be electronic, but for the purposes of this book we assume that they are. By data management we mean all data practices, manipulations, enhancements and processes that ensure th...