Companies are optimizing their computing resources to get more transactional performance out of the same hardware resources. At the same time, the demand and pace of business and customer focus is increasing; they need real-time insights on the transactional data.
In recent years, many companies have turned to No-SQL solutions that allow very high write performance of transactions while allowing eventual consistency, but that later require data mining and analysis.
Microsoft SQL Server has taken on this challenge and, with every release, continues to expand the workloads in many dimensions. This chapter will discuss many of the features that allow both high-performance transaction processing while simultaneously allowing real-time analytics on transactional data without the need for a separate set of ETL processes, a separate data warehouse, and the time to do that processing.
Microsoft SQL Server 2019 is built on a database engine that is number one for TPC-E (On-Line Transaction Processing Benchmark) and TCP-H (Decision Support Benchmark). See http://www.tpc.org for more information.
Changes in hardware architecture allow dramatic speed increases with Hybrid Buffer Pool, which utilizes persistent memory (PMEM), also known as Storage Class Memory (SCM).
Microsoft SQL Server 2019 can be used in the most demanding computing environments required today. Using a variety of features and techniques, including in-memory database operations, can make dramatic increases in your transaction processing rate while still allowing near-real-time analysis without having to move your transaction data to another "data warehouse" for reporting and analysis.
Microsoft SQL Server 2019 has also expanded the number of opportunities to tune database operations automatically, along with tools and reports to allow monitoring and optimization of queries and workloads. Comprehensive diagnostic features including Query Store allow SQL Server 2019 to identify performance issues quickly.
By upgrading to SQL Server 2019, the customer will be able to boost query performance without manual tuning or management. Intelligent Query Processing (IQP) helps many workloads to run faster without making any changes to the application.
Hybrid transactional and analytical processing (HTAP)
Hybrid transactional and analytical processing (HTAP), is the application of tools and features to be able to analyze live data without affecting transactional operations.
In the past, data warehouses were used to support the reporting and analysis of transactional data. A data warehouse leads to many inefficiencies. First, the data has to be exported from the transactional database and imported into a data warehouse using ETL or custom tools and processes. Making a copy of data takes more space, takes time, may require specialized ETL tools, and requires additional processes to be designed, tested, and maintained. Second, access to analysis is delayed. Instead of immediate access, business decisions are made, meaning the analysis may be delayed by hours or even days. Enterprises can make business decisions faster when they can get real-time operational insights. In some cases, it may be possible to affect customer behavior as it is happening.
Microsoft SQL Server 2019 provides several features to enable HTAP, including memory-optimized tables, natively compiled stored procedures, and Clustered Columnstore Indexes.
This chapter covers many of these features and will give you an understanding of the technology and features available.
A more general discussion of HTAP is available here: https://en.wikipedia.org/wiki/Hybrid_transactional/analytical_processing_(HTAP).
Clustered Columnstore Indexes
Clustered Columnstore indexes can make a dramatic difference and are the technology used to optimize real-time analytics. They can achieve an order of magnitude performance gain over a normal row table, a dramatic compression of the data, and minimize interference with real-time transaction processing.
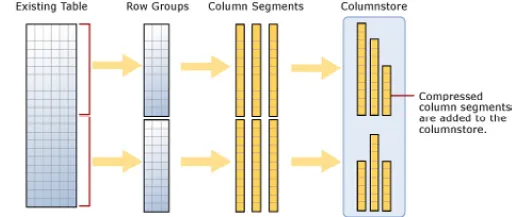
A columnstore has rows and columns, but the data is stored in a column format.
A rowgroup is a set of rows that are compressed into a columnstore format — a maximum of a million rows (1,048,576).
There are an optimum number of rows in a rowgroup that are stored column-wise, and this represents a trade-off between large overhead, if there are too few rows, and an inability to perform in-memory operations if the rows are too big.
Each row consists of column segments, each of which represents a column from the compressed row.
Columnstore is illustrated in Figure 1.1, showing how to load data into a non-clustered columnstore index:
Figure 1.1: Loading data into a non-clustered columnstore index
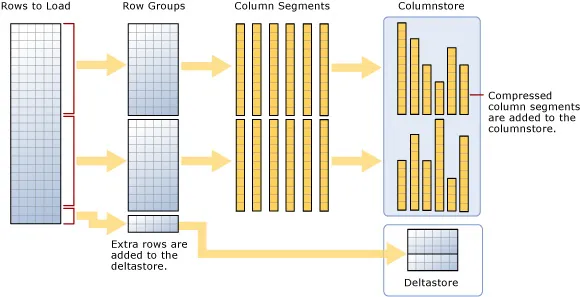
A clustered columnstore index is how the columnstore table segments are stored in physical media. For performance reasons, and to avoid fragmenting the data, the columnstore index may store some data in a deltastore and a list of the IDs of deleted rows. All deltastore operations are handled by the system and not visible directly to the user. Deltastore and columnstore data is combined when queried.
A delta rowgroup is used to store columnstore indexes until there are enough to store in the columnstore. Once the maximum number of rows is reached, the delta rowgroup is closed, and a background process detects, compresses, and writes the delta rowgroup into the columnstore.
There may be more than one delta rowgroup. All delta rowgroups are described as the deltastore. While loading data, anything less than 102,400 rows will be kept in the deltastore until they group to the maximum size and are written to the columnstore.
Batch mode execution is used during a query to process multiple rows at once.
Loading a clustered columnstore index and the deltastore are shown in Figure 1.2.
Figure 1.2: Loading a clustered columnstore index
Further information can be found here: https://docs.microsoft.com/en-us/sql/relational-databases/indexes/get-started-with-columnstore-for-real-time-operational-analytics?view=sql-server-2017.
Adding Clustered Columnstore Indexes to memory-optimized tables
When using a memory-optimized table, add a non-clustered columnstore index. A clustered columnstore index is especially useful for running analytics on a transactional table.
A clustered columnstore index can be added to an existing memory-optimized table, as shown in the following code snippet:
-- Add a clustered columnstore index to a memory-optimized table
ALTER TABLE MyMemOpttable
ADD INDEX MyMemOpt_ColIndex clustered columnstore
Disk-based tables versus memory-optimized tables
There are several differences between memory-optimized and disk-based tables.
One difference is the fact that, in a disk-based table, rows are stored in 8k pages and a page only stores rows from a single table. With...