
- 421 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Parallel Supercomputing in MIMD Architectures
About this book
Parallel Supercomputing in MIMD Architectures is devoted to supercomputing on a wide variety of Multiple-Instruction-Multiple-Data (MIMD)-class parallel machines. This book describes architectural concepts, commercial and research hardware implementations, major programming concepts, algorithmic methods, representative applications, and benefits and drawbacks. Commercial machines described include Connection Machine 5, NCUBE, Butterfly, Meiko, Intel iPSC, iPSC/2 and iWarp, DSP3, Multimax, Sequent, and Teradata. Research machines covered include the J-Machine, PAX, Concert, and ASP. Operating systems, languages, translating sequential programs to parallel, and semiautomatic parallelizing are aspects of MIMD software addressed in Parallel Supercomputing in MIMD Architectures. MIMD issues such as scalability, partitioning, processor utilization, and heterogenous networks are discussed as well.This book is packed with important information and richly illustrated with diagrams and tables, Parallel Supercomputing in MIMD Architectures is an essential reference for computer professionals, program managers, applications system designers, scientists, engineers, and students in the computer sciences.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Topic
InformaticaSubtopic
Architettura di sistemiPart 1
MIMD Computers
In this part we examine a representative sample of MIMD computers, both those that are commercially available and the research machines not yet available to the general user community. Each is addressed in its own chapter, some with application examples.
In the rapidly evolving world of MIMD computers, particularly at the high-performance end of the range, the more recent machines are more advanced than earlier implementations. This is reflected in the selection of computers covered here; for example, the BBN Butterfly and Encore Multimax both played important roles in the development of the technology, but are no longer offered in the marketplace.
The evolutionary progress of MIMD computers is not as advanced as SIMD computers. The 1992Gorden Bell Prize forparallel processing achievement went, in the MIMD arena, to the first application to exceed one GigaFLOPS. The SIMD part of the price was awarded to a 14-GigaFLOPS application. However, the MIMD paradigm is believed to be richer in application opportunities.
Commercial Machines
___________________________________________________________
1 Thinking Machines Corporation CM-5
Overview
In October 1991, Thinking Machines Corporation (TMC) introduced the Connection Machine model CM-5. The design of the CM-5 surprised the parallel high-performance computing community because many of the features are distinct departures from the pattern that characterized prior TMC products. Prior Connection Machine models were SIMD, but the CM-5 has MIMD capabilities. They were hypercube connected, but the CM-5 is not. They had custom chips, but the CM-5 uses a standard off-the-shelf RISC microprocessor. The CM-5 has vector pipes, four per node, while prior machines did not. It has a Unix-like operating system, new to TMC.
TMC emphasizes the scalability of the design. Since one can always increase performance by adding more processors, the question becomes does the I/O, communications and reliability grow in proportion with the size of the system. Danny Hillis, TMC’s chief scientist, believes the CM-5 architecture answers that question and can grow to teraFLOPS throughput rates.
Processors
A CM-5 (Figure 1) system may contain hundreds or thousands of parallel processing nodes. Each node has its own memory. Nodes can fetch from the same address in their respective memories to execute the same (SIMD-style) instruction, or from individually chosen addresses to execute independent (MIMD-style) instructions.
The processing nodes are supervised by a control processor, which runs an enhanced version of the UNIX operating system. Program loading begins on the control processor; it broadcasts blocks of instructions to the parallel processing nodes and then initiates execution. When all nodes are operating on a single control thread, the processing nodes are kept closely synchronized and blocks are broadcast as needed. (There is no need to store an entire copy of the program at each node.) When the nodes take different branches, they fetch instructions independently and synchronize only as required by the algorithm under program control.
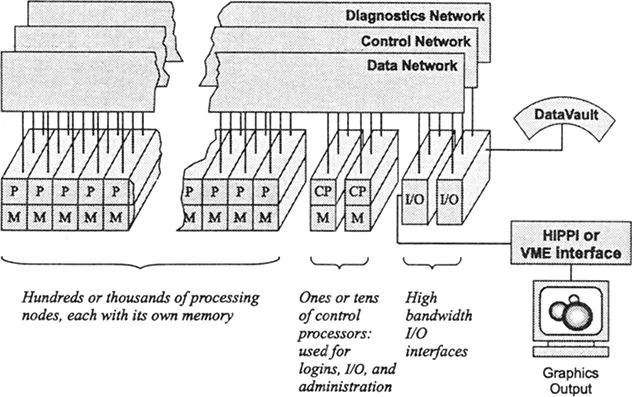
FIGURE 1. Organization of the CM system.*
To maximize system usefulness, a system administrator may divide the parallel processing nodes into groups, known as partitions. There is a separate control processor, known as a partition manager, for each partition. Each user process executes on a single partition, but may exchange data with processes on other partitions. Since all partitions utilize UNIX time-sharing and security features, each allows multiple users to access the partition while ensuring that no user’s program interferes with another’s.
Other control processors in the CM-5 system manage the system’s I/O devices and interfaces. This organization allows a process on any partition to access any I/O device and ensures that access to one device does not impede access to other devices. Figure 2 shows how this distributed control works with the CM-5 interprocessor communication networks to enhance system efficiency.
Functionally, the CM-5 is divided into three major areas. The first contains some number of partitions, which manage and execute user applications; the second contains some number of I/O devices and interfaces; and the third contains the two interprocessor communication networks that connect all parts of the first two areas. (A fourth functional area, covering system management and diagnostics, is handled by a third interprocessor network and is not shown in Figure 2.)
Because all areas of the system are connected by the Data Network and the Control Network, all can exchange information efficiently. The two networks provide high bandwidth transfer of messages of all sorts: downloading code from a control processor to its nodes, passing I/O requests and acknowledgments between control processors, and transferring data, either among nodes (whether in a single partition or in different partitions) or between nodes and I/O devices.
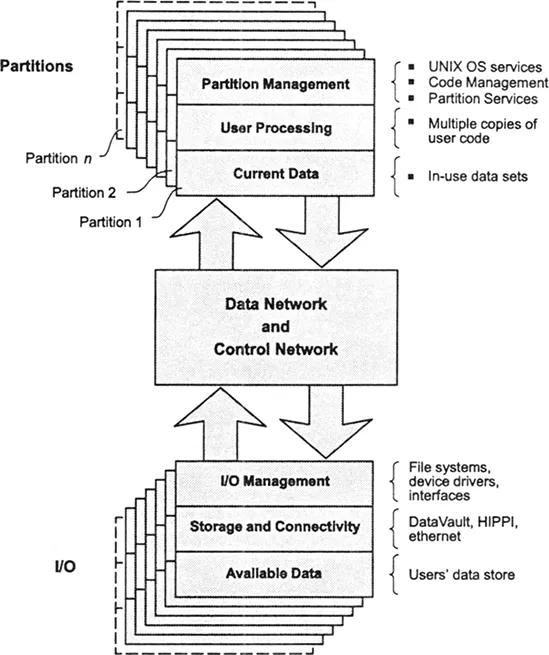
FIGURE 2. Distributed control on the CM-5.
Networks
Every control processor and parallel processing node in the CM-5 is connected to two scalable interprocessor communication networks, designed to give low latency combined with high bandwidth in any possible configuration a user may wish to apply to a problem. Any node may present information, tagged with its logical destination, for delivery via an optimal route. The network design provides low latency for transmissions to near neighboring addresses, while preserving a high, predictable bandwidth for more distant communications.
The two interprocessor communications networks are the Data Network and the Control Network. In general, the Control Network is used for operations that involve all the nodes at once, such as synchronization operations and broadcasting; the Data Network is used for bulk data transfers where each item has a single source and destination.
A third network, the Diagnostics Network, is visible only to the system administrator; it keeps tabs on the physical well-being of the system.
External networks, such as Ethernet and FDDI, may also be connected to a CM-5 system via the control processors.
I/O
The CM-5 runs a UNIX-based operating system; it provides its own highspeed parallel file system and also allows full access to ordinary NFS file systems. It supports both high-performance parallel interface (HIPPI) and VME interfaces, thus allowing connections to a wide range of computers and I/O devices, while using standard UNIX commands and programming techniques throughout. A CMIO interface supports mass storage devices such as the Data Vault and enables sharing of data with CM-2 systems.
I/O capacity may be scaled independently of the number of computational processors. A CM-5 system of any size can have the I/O capacity it needs, whether that be measured in local storage, in bandwidth, or in access to a variety of remote data sources. Communications capacity scales both with processors and with I/O.
Just as every partition is managed by a control processor, every I/O device is managed by an input/output control processor (IOCP), which provides the software that supports the file system, device driver, and communications protocols. Like partitions, I/O devices and interfaces use the Data Network and the Control Network to communicate with processes running in other parts of the machine. If greater bandwidth is desired, files can be spread across multiple I/O devices: a striped set of eight DataVaults, for example, can provide eight times the I/O bandwidth of a single DataVault.
The same hardware and software mechanisms that transfer data between a partition and an I/O device can also transfer data from one partition to another (through a named UNIX pipe) or from one I/O device to another.
A Universal Architecture
The architecture of the CM-5 is optimized for data parallel processing of large, complex problems. The Data Network and Control Network support fully general patterns of point-to-point and multiway communication, yet reward patterns that exhibit good locality (such as nearest-neighbor communications) with reduced latency and increased throughput. Specific hardware and software support improve the speed of many common special cases.
Two more key facts should be noted about the CM-5 architecture. First, it depends on no specific types of processors. As new technological advances arrive, they can be moved with ease into the architecture. Second, it builds a seamlessly integrated system from a small number of basic types of modules. This creates a system that is thoroughly scalable and allows for great flexibility in configuration.
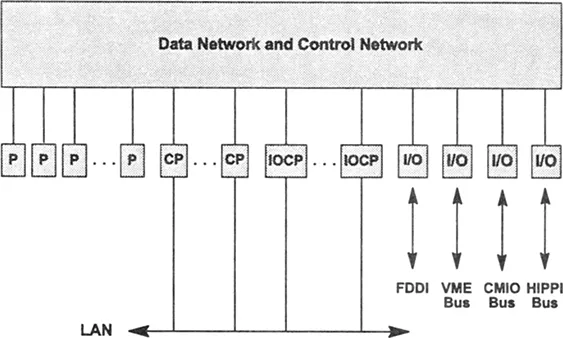
FIGURE 3. System components.
Architecture Details
A Connection Machine Model CM-5 system contains thousands of computational processing nodes, one or more control processors, and I/O units that support mass storage, graphic display devices, and VME and HIPPI peripherals. These are connected by the Control Network and the Data Network. (For a high-level sketch of these components, see Figure 3.)
A CM-5 system contains tens, hundreds, or thousands of processing nodes, each with up to 128 Mflops of 64-bit floating-point performance. It also contains a number of I/O devices and external connections. The number of I/O devices and external connections is independent of the number of processing nodes. Both processing and I/O resources are managed by a relatively small set of control processors. All these components are uniformly integrated into the system by two internal communications networks, the Control Network and the Data Network.
Processors
Every processing node is a general-purpose computer that can fetch and interpret its own instruction stream, execute arithmetic and logical instructions, calculate memory addresses, and perform interprocessor communication. The processing nodes inaCM-5systemcan perform independent tasks or collaborate on a single problem. Each processing node has 8,16, or 32 Mbytes of memory; with the high-performance arithmetic accelerator, it has the full 32 Mbytes of memory and delivers up to 128 Mips or 128 Mflops.
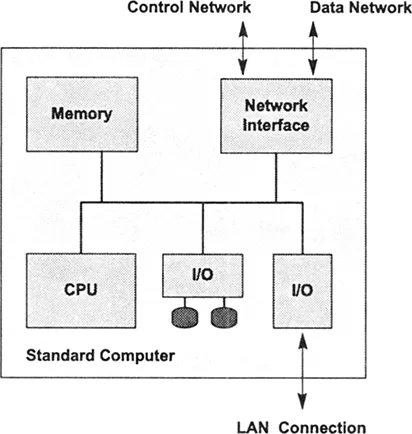
FIGURE 4. Control processor.
The control processors are responsible for administrative actions such as scheduling user tasks, allocating resources, servicing I/O requests, accounting, enforcing security, and diagnosing component failures. In addition, they may also execute some of the code for a user program. Control processors have the same general capabilities as processing nodes, but are specialized for performing managerial functions rather than computational functions. For example, control processors have additional I/O connections and lack the high-performance arithmetic accelerator. (See Figure 4.)
The basic CM-5 control processor consists of a RISC m...
Table of contents
- Cover
- Half Title
- Copyright Page
- Dedication
- Table of Contents
- Foreword
- Preface
- List of Figures
- The Author
- Introduction
- Background
- PART 1: MIMD COMPUTERS
- PART 2: MIMD SOFTWARE
- PART 3: MIMD ISSUES
- List of Sources
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Parallel Supercomputing in MIMD Architectures by R.Michael Hord in PDF and/or ePUB format, as well as other popular books in Informatica & Architettura di sistemi. We have over 1.5 million books available in our catalogue for you to explore.