
- 642 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
About this book
Since the publication of the first edition, parallel computing technology has gained considerable momentum. A large proportion of this has come from the improvement in VLSI techniques, offering one to two orders of magnitude more devices than previously possible. A second contributing factor in the fast development of the subject is commercialization. The supercomputer is no longer restricted to a few well-established research institutions and large companies. A new computer breed combining the architectural advantages of the supercomputer with the advance of VLSI technology is now available at very attractive prices. A pioneering device in this development is the transputer, a VLSI processor specifically designed to operate in large concurrent systems.
Parallel Computers 2: Architecture, Programming and Algorithms reflects the shift in emphasis of parallel computing and tracks the development of supercomputers in the years since the first edition was published. It looks at large-scale parallelism as found in transputer ensembles. This extensively rewritten second edition includes major new sections on the transputer and the OCCAM language. The book contains specific information on the various types of machines available, details of computer architecture and technologies, and descriptions of programming languages and algorithms. Aimed at an advanced undergraduate and postgraduate level, this handbook is also useful for research workers, machine designers, and programmers concerned with parallel computers. In addition, it will serve as a guide for potential parallel computer users, especially in disciplines where large amounts of computer time are regularly used.
Trusted by 375,005 students
Access to over 1 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Subtopic
Programming AlgorithmsIndex
Computer Science1 Introduction
Large-scale parallelism is the principal innovation to appear in the design of large commercially available computers in the 1980s. In this introductory chapter we trace the history of this development (§1.1), then lay out the principles that can be applied to classify these parallel computers (§1.2) and characterise their relative performance (§1.3). In order to make efficient use of such parallel computers the programmer must be aware of the overall organisation of the computer system, which we aptly describe as its architecture: that is to say, the number and type of processors, memory modules and input/output channels, and how these are controlled and interconnected. Chapters 2 and 3 are devoted respectively to describing the architecture of the two main classes of parallel computers, namely the pipelined computer and the multiprocessor array. It would be impractical to give a comprehensive description of all designs in these categories; instead we have selected principally commercially available computers that have or are likely to have a significant number of sales, and which differ sufficiently from each other to illustrate alternative approaches to the same problem. The pipelined computers described in Chapter 2 are the CRAY X-MP, CRAY-2, CYBER 205, ETA10 and the FPS 164/MAX. The processor arrays and multiprocessors described in Chapter 3 are the ICL DAP, Burroughs BSP, Denelcor HEP and the Connection Machine. In our discussion of future developments in Chapter 6 we compare the characteristics of Bipolar and MOS technologies, discuss the technological issues arising in the design of parallel computers, and consider the potential of wafer-scale integration.
The advent of very large-scale chip integration (VLSI), culminating in the single-chip microprocessor, has led to a large number of computer designs in which more than one instruction stream cooperate towards the solution of a problem. Such multi-instruction stream or MIMD computers are reviewed (§1.1.8) and classified (§1.2.5) in Chapter 1 and one of them, the Denelcor HEP (§3.4.4), is described in detail in Chapter 3.
New architectural features require new computer languages and new numerical algorithms, if the user is to take advantage of the development. In the case of parallel computers that are designed to work most efficiently on one- or sometimes two-dimensional lists of data, this is most naturally achieved by introducing the mathematical concept of vector or matrix into the computer language and by analysing algorithms in terms of their suitability for execution on vectors of data. A good computer language also greatly influences the ease of programming and Chapter 4 is devoted to parallel languages from the point of view of implicit parallelism (§4.2), structure parallelism (§4.3) and process parallelism (§4.4). The usefulness of a parallel computer depends on the invention or selection of suitable parallel algorithms and in Chapter 5 we establish principles for measuring the performance of an algorithm on a parallel computer. These are then applied to the selection of algorithms for recurrences, matrix multiplication, tridiagonal linear equations, transforms and some partial differential equations.
Although our presentation is necessarily based on the situation circa 1987, we try to establish principles that the reader can apply as computer architecture develops further. Our objective is to enable the reader to assess new designs by classifying their architecture and characterising their performance; and thereby be able to select suitable algorithms and languages for solving particular problems.
1.1 HISTORY OF PARALLELISM AND SUPERCOMPUTING
Our history will be primarily a study of the influence of parallelism on the architecture of top-of-the-range high-performance computers designed to solve difficult problems in science and engineering (e.g. the solution of three-dimensional time-dependent partial differential equations). The requirement in such work is for the maximum arithmetic performance in floating-point (i.e. real as opposed to integer) arithmetic, which has been achieved by a combination of technological advances and the introduction of parallelism into the architecture of the computers. Computers satisfying the above requirement are now generally known as supercomputers, so that this section might equally well be regarded as a history of supercomputing.
We start our discussion of the history of parallelism in computer architecture by considering the reduction in the time required for a simple arithmetic operation, for example a floating-point multiplication, in the period since the first commercially produced computer, the UNIVAC 1, appeared in 1951. This is shown in figure 1.1 and demonstrates roughly a ten-fold increase in arithmetic computing speed every five years. This sensational increase in computer speed has been made possible by combining the technological improvements in the performance of the hardware components with the introduction of ever greater parallelism at all levels of the computer architecture.
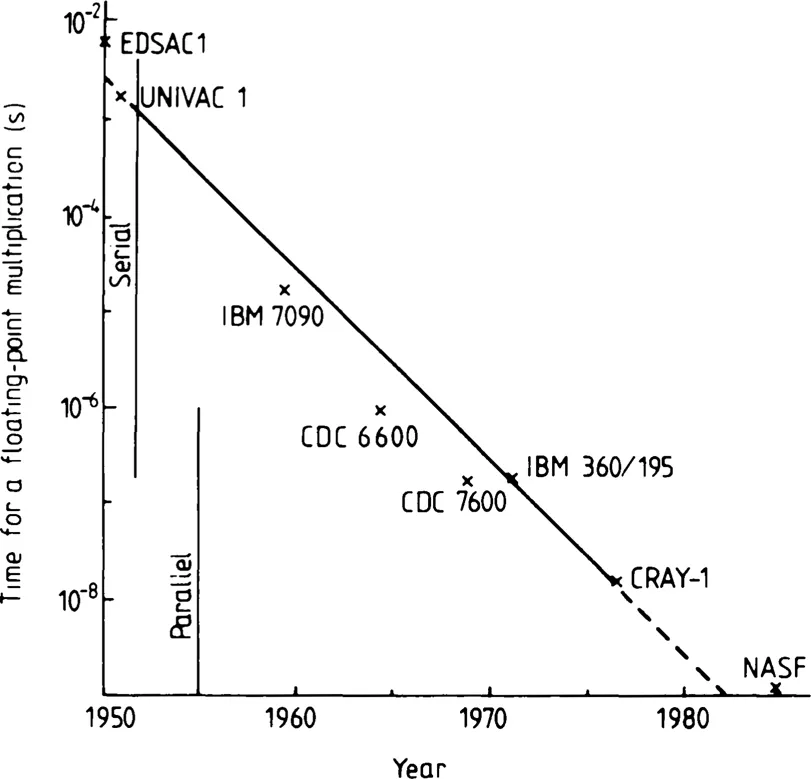
FIGURE 1.1 The history of computer arithmetic speed since 1950, showing an increase of a factor of 10 in 5 years.
The first generation of electronic digital computers in the 1950s used electronic valves as their switching components with gate delay times† of approximately 1 /xs. These were replaced about 1960 by the discrete germanium transistor (gate delay time of approximately 0.3 /xs) in such second-generation machines as the IBM 7090. Bipolar planar integrated circuits (ics) on silicon, at the level of small-scale integration (ssi), with a few gates per chip and gate delay time of about 10 ns, were introduced in about 1965 and gradually improved until around 1975 gate delay times of slightly less than 1 ns were reliably possible. Although about five to ten times slower, much greater packing densities are possible with the alternative metal oxide silicon (MOS) semiconductor technology. By the beginning of the 1980s micro-processors, with a speed and capacity about equal to the first-generation valve computers, were available on a single chip of silicon a few millimetres square. This engineering development obviously makes possible the implementation of various highly parallel architectures that had previously remained only theoretical studies.
†The gate delay time is the time taken for a signal to travel from the input of one logic gate to the input of the next logic gate (see e.g. Turn 1974 p 147). The figures are only intended to show the order of magnitude of the delay time.
Looking at the period from 1950 to 1975 one can see that the basic speed of the components, as measured by the inverse of the gate delay time, has increased by a factor of about 103, whereas the performance of the computers, as measured by the inverse of the multiplication time, has increased by a factor of about 105. This additional speed has been made possible by architectural improvements, principally the introduction of parallelism, which is the main subject of this volume. For economic reasons, different technologies favour the introduction of parallelism in different ways. For example, in Chapter 6 we discuss the influence of VLSI and wafer-scale integration on the way increased parallelism is likely to be introduuced into the architecture of future scientific supercomputers. Technological development, including some interesting predictions for the 1980s, is also discussed by Turn (1974) in his book entitled Computers in the 1980s and by Sumner (1982) in the Infotech State of the Ar...
Table of contents
- Cover
- Halftitle Page
- Title Page
- Copyright Page
- Dedication
- Table of Contents
- Preface
- Preface to the Second Edition
- 1 INTRODUCTION
- 2 PIPELINED COMPUTERS
- 3 MULTIPROCESSORS AND PROCESSOR ARRAYSS
- 4 PARALLEL LANGUAGES
- 5 PARALLEL ALGORITHMS
- 6 TECHNOLOGY AND THE FUTURE
- APPENDIX
- REFERENCES
- INDEX
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Parallel Computers 2 by R.W Hockney,C.R Jesshope in PDF and/or ePUB format, as well as other popular books in Computer Science & Programming Algorithms. We have over one million books available in our catalogue for you to explore.