
- 160 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
About this book
First published in 1979. The aim of this series of Tutorial Essays, of which the present book is the second volume, is to enable the specialist in one area to discover in as painless a way as possible what his colleagues in other parts of the field are up to: New discoveries, methods and theories in one speciality often have important implications for work in others. The essays are also intended to be intelligible and useful to graduate students and advanced undergraduates seeking an introduction to a topic. In this volume Bow Lett describes modern work on an old topic, delay learning in animals, and discusses its implications for theories of learning. Mark Georgeson expounds an important new approach to vision, the application of Fourier analysis: His chapter contains an exceptionally clear exposition of the ideas underlying this technique written for the reader with little mathematical knowledge. Dennis Holding provides a synthesis of the many different approaches to the problem of echoic memory, and Gregory Jones presents some new ideas on associative memory which make many previously puzzling results fall into place.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Subtopic
Experimental PsychologyIndex
Psychology1 Long-Delay Learning: Implications for Learning and Memory Theory
Bow Tong Lett
Memorial University of Newfoundland
Memorial University of Newfoundland
This chapter is about the mystery of how animals associate two events separated by a temporal gap. That is, how does an animal learn that event A is related to event B when A precedes B and is no longer present at the time B begins? Traditional theories of learning have usually attempted to explain this phenomenon in one of two ways.
The first explanation is that a chain of associations involving one or more intervening events bridges the temporal gap between A and B. Although A and B are separated in time, the underlying process does not involve association over a delay because each individual association in the chain is between temporally contiguous events. For example, when a rat learns to run a maze, it does not link the start directly with the goal; it learns that the startpoint leads to the next point, which leads to the next point, and so on until the goal is reached. There is a variant of this approach for cases in which there are no changes in the external stimuli over a delay: The animal is presumed to emit a mediating chain of covert responses that bridge the gap between A and B.
The second traditional explanation invokes lingering stimulus traces. After the first event (A) is over, sensory activity initiated by it may continue until the occurrence of the second event (B). In such a case, the animal does not really associate A with B over a delay; rather, it associates the stimulus trace of A with B which is present concurrently. It should be noted that in traditional learning theory a stimulus trace is not the same thing as a memory. Perhaps the most important difference is that the trace, as traditionally defined by learning theories, does not involve long term retention of information.
1.1 Types of Long-Delay Learning
In traditional learning experiments, associations were rarely obtained over delays greater than a minute or two, and these instances seemed to be readily explicable in terms of mediating chains or lingering stimulus traces. It is, however, hard to conceive of either mediating chains or lingering stimulus traces that last much longer than a few minutes. Thus, the recent discovery of a variety of learning situations in which animals can readily associate over delays of an hour or more poses a severe problem for the traditional position. Before considering the theoretical ramifications of such long-delay learning, two instances will be described, namely, learned flavor aversions and longdelay learning in traditional experimental situations such as the runway and T-maze.
Learned Flavor Aversions

FIG. 1.1. Mean intake of saccharin solution in groups previously made sick at various delay times after drinking. The saccharin controls (top line) had not previously been made sick. (After Nachman, 1970.)
If an animal ingests a poisonous substance and survives, it will usually avoid consuming that or similar tasting substances in the future. The basis for this highly adaptive behavior was in doubt until Garcia (Garcia, Kimeldorf, & Koelling, 1955) devised a technique to analyze how flavor aversions are learned; his innovation was to dissociate the ingested substance from the toxic agent. The animal was made to consume a harmless substance with an arbitrary flavor and then subjected to toxicosis by some independent means. It was tested for an aversion to the harmless substance after recovery from the poisoning. For instance, thirsty rats can be allowed to consume saccharin solution and then be made sick by X-irradiation or injection of a sublethal dose of poison. Amazingly for those accustomed to traditional learning situations, the rats exhibit an aversion to the saccharin solution after a single such pairing of saccharin consumption with induction of sickness delayed by as much as 6-12 hours (e.g., Revusky, 1968; Smith & Roll, 1967). Figure 1.1 shows a typical curve of saccharin aversion as a function of delay of sickness (Nachman, 1970).
Garcia's technique makes it possible to use the control procedures needed to demonstrate that learning has occurred. The animal can be made sick without consuming the flavored substance beforehand; it can consume the flavored substance without being subjected to sickness, or it can experience both sickness and the flavored substance but separated by one or more days. None of these control procedures produces a flavor aversion (Revusky & Garcia, 1970). Since the formation of a flavor aversion depends on a paired occurrence of flavor and sickness, these flavor aversions must be learned.
Although no serious student of flavor aversions denies that they are learned and involve associations over long delays, there is disagreement about how similar they are to the types of learning more commonly studied in the laboratory. At one end of the spectrum are Rozin and Kalat (1971), who claim that learned food aversion is a specialized adaptation with laws that differ from those governing other forms of learning. They rest their case largely on the fact that the natural contingencies governing learning to select food are different from those involved in learning which motor behaviors will pay off in the presence of different audiovisual stimuli. Important consequences of ingestion are often delayed until digestion and absorption occur, while the consequences of motor activities are seldom delayed. Accordingly, Rozin and Kalat feel that the laws governing learning for food selection have evolved in a different way from those governing other learned responses.
My own view is at the opposite end of the spectrum from that of Rozin and Kalat. It will be argued that it is inappropriate to treat food selection as a unique case because there are more similarities than differences between learned flavor aversions and more conventional learning situations. Many of the basic phenomena obtained in other learning paradigms can be demonstrated using learned flavor aversions. They include the following:
1. Extinction. Learned flavor aversions undergo extinction when the flavor is no longer followed by sickness (e.g., Garcia, Ervin, & Koelling, 1966).
2. Discrimination. Animals discriminate between a flavored substance paired with sickness and one that is not; flavor aversions are specific to the substance ingested prior to sickness (Revusky & Garcia, 1970).
3. Parametric manipulations. Varying CS intensity, US intensity, and the length of delay affect the strength of a flavor aversion in much the same way as any other learned behavior. Increasing CS intensity by raising the concentration of flavoring (e.g., Dragoin, 1971; Garcia, 1971) or increasing US intensity by raising the dose of the toxic agent (e.g., Garcia, Ervin, & Koelling, 1967; Nachman & Ashe, 1973; Revusky, 1968) both increase the strength of the aversion.
As can be seen in Fig. 1.1, the function relating strength of aversion and length of delay is similar to the delay gradients found in other learning situations, except that the delays are measured in minutes or hours rather than seconds. In addition, there are some subtle effects that are remarkably similar in both learned flavor aversions and traditional learning situations. These include sensory preconditioning (Lavin, 1976), overshadowing (Revusky, 1971), blocking (Revusky, 1971), and conditioned inhibition (Best, 1975; Taukulis & Revusky, 1975).
Long-Delay Learning in Traditional Situations
Aside from the parametric similarities between learned flavor aversions and conventional learned responses, there is another reason for treating longdelay learning of flavor aversions as a general rather than a specific theoretical problem: Long-delay learning is not limited to "exotic" situations like flavor-aversion learning but has also been demonstrated in conventional learning situations. In the next two sections I will describe two instances of such long-delay learning, namely, delayed-response learning and learning with delay of reward. The former phenomenon involves a delay between a discriminative cue and the opportunity to respond while the latter involves a delay between a response and a reward. In traditional behavioristic theories of learning, the two kinds of learning have usually been treated as posing different theoretical problems. Although the differences between them are not important in the present theoretical context, it is convenient to distinguish them for purposes of exposition.
Delayed-Response Learning
In delayed-response experiments there is a cue that indicates whether or not a single response will be rewarded (go-no-go experiment) or which of a number of responses will be rewarded (e.g., go-left-go-right procedure). The cue terminates before the animal is given an opportunity to emit a response, and the delay between termination of the cue and the opportunity to respond may be regarded as the delay over which association is to occur.
With one exception, rats do not perform appropriately with delays greater than 10 seconds unless there is a mediating event such as a secondary reinforcer between the cue and the opportunity to respond. Rats taught under conditions in which the delay is initially short and gradually made longer usually cease to respond correctly when the delay approaches 10 seconds or so (Hunter, 1913).
The single type of delayed-response experiment that results in learning over delays much greater than a minute will be referred to here as "home cage (HC) delayed-response learning." In that procedure, the cue is made available tothe rat near the end of one trial; shortly thereafter, the subject is taken out of the apparatus and placed in its home cage or in a holding cage until the next trial. When it is replaced in the apparatus, usually a runway or T-maze, it must make use of the discriminative cue given on the preceding trial.
The best known example of HC delayed-response learning was devised by Tyler, Wortz and Bitterman (1953) and has been extensively studied by Capaldi (for a thorough review, see Capaldi, 1971). Rats are trained to run down a runway to a goalbox that contains food only on alternate trials. They eventually learn this pattern of reinforcement as evidenced by faster running on rewarded trials than on unrewarded trials. Figure 1.2 shows an instance of such learning with a minimum intertrial interval of 20 minutes (Capaldi & Stanley, 1963).
Within a trial, there are no external cues correlated with the presence or absence of reward in the goalbox. The rat's anticipatory behavior, therefore, implies that it can use the reward outcome of the previous trial to predict the presence or absence of reward on the current trial. In other words, the rat must have learned that a reward on the previous trial signals nonreward on the current trial, and a nonreward on the previous trial indicates that the present trial will be a rewarded one. This type of learning has been demonstrated with a 24-hour delay (Capaldi & Spivey, 1964), but such a feat is not easily accomplished (Surridge & Amsel, 1965). There can, however, be no doubt that such learning readily occurs with delays up to 15-20 minutes.
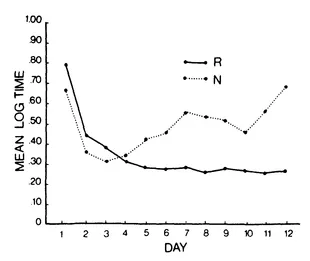
FIG. 1.2. Mean log time to traverse the runway on rewarded (R) and nonrewarded (N) trials on each day of training with alternating reinforcement. (After Capaldi & Stanley, 1963.)
If the capacity of rats to learn an alternating pattern of reinforcement were the only instance of HC delayed-response learning, it might seem reasonable to dismiss it as a special case of no significance for animal learning theory as a whole. Perhaps reward and nonreward are unusually salient differential cues since they differ in their emotional effects in addition to their stimulus properties. Fortunately, however, it has been shown that HC delayedresponse learning can occur under other conditions. Pschirrer (1972) trained rats in a runway with a regularly recurring cycle of three types of reward outcomes. For some rats, the first reward outcome in the three-trial cycle was chow pellets, the second was milk, the third trial was not rewarded; after the third trial, the cycle started again. Other rats received these three types of trials in different orders. The novel feature of this procedure is that appropriate anticipatory behavior depends upon the rat's ability to use the two types of rewards as differential cues for predicting the goal outcome on the following trial. For example, chow pellets predicted milk reward on the following trial while milk reward predicted no reward on the following trial or vice versa for other rats. Pschirrer's rats showed appropriate anticipation by running equally fast on the two types of rewarded trials and running slowly on the unrewarded trials. This discrimination was obtained with an intertrial interval of 15 minutes. These results indicate that HC delayed-response learning is not limited to the learning of an alternating pattern of reward and nonreward.
Pschirrer extended his findings by training rats on a go-left-go-right discrimination. The type of reward received on the preceding trial was the cue for the appropriate choice response, rather than for the goal outcome, on the following trial. For some rats, a milk reward on the preceding trial was the discriminative cue for running to the left side of a T-maze while a pellet reward on the preceding trial was the discriminative stimulus for running to the right side; the reverse was true for other rats. With an intertrial period of 3 minutes, the rats eventually learned to choose the correct side on over 80% of the trials.
Petrinovich and Bolles (1957) used the rat's own behavior, rather than a reward outcome, as a discriminative cue for choice behavior on the next trial. The rats were rewarded for running to the side of a T-maze opposite to that chosen on the preceding trial. They learned to alternate sides despite an intertrial interval of over an hour.
The stimuli used in the HC delayed-response experiments described above are not commonly used in discrimination learning experiments, and thus it might still be argued that HC delayed-response learning is limited to a few special cases involving unusual stimuli. To exclude this possibility Revusky (1974) provided evidence that stimuli like those used in traditional discrimination experiments can also be effective in HC delayed-response learning. His stimuli were a large black goalbox and a narrow white goalbox. Each runway trial ended in one or other goalbox on a random basis. Whether or not the goalbox contained reward on the current trial was correlated only with the type of goalbox present on the preceding trial. Some rats received reward when the preceding trial had terminated in the black goalbox but not when the preceding trial had terminated in the white goalbox; the reverse was true for other rats. After many trials, each separated by an interval of at least 4 minutes, the rats learned to run more quickly on rewarded than on unrewarded trials.
Delayed-Reward Learning
In the present section, it will be shown that delayed-reward learning, like delayed-response learning, is facilitated when the animals spend the delay away from the apparatus. Using a procedure under which the delay was spent in the home cage, I demonstrated that rats can learn a simple discrimination in a T-maze with delays of reward lasting up to an hour.
In the earliest experiment (Lett, 1973), rats were trained to perform a spatial discrimination in a T-maze with a 1-minute delay of reward. The T-maze consisted of a startbox flanked on the left side by a white endbox and on the right by a black endbox. From the startbox, the rat could directly enter either of the two endboxes whereupon a door closed to prevent retracing. For half the rats, the left endbox was correct and for the remainder the right endbox was correct. An unusual feature of the procedure was that the rat was not rewarded in the correct endbox. Regardless of which endbox it selected, the rat was removed and placed in its home cage to spend a 1-minute delay. When the delay ended, the rat was returned to the startbox. If the choice response had been incorrect, the startbox was empty and the rat had to make another choice which was followed by another delay in the home cage. When the correct choice had been made, the startbox contained reward, a dish of wet mash. During each day's training, this procedure was continued until the rat made a correct choice and, after the usual delay in the home cage, received its reward in the startbox.
Figure 1.3 ...
Table of contents
- Cover
- Title
- Copyright
- Contents
- Preface
- 1. Long-Delay Learning: Implications for Learning and Memory Theory
- 2. Spatial Fourier Analysis and Human Vision
- 3. Echoic Storage
- 4. Analyzing Memory by Cuing: Intrinsic and Extrinsic Knowledge
- Author Index
- Subject Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Tutorial Essays in Psychology by N. S. Sutherland in PDF and/or ePUB format, as well as other popular books in Psychology & Experimental Psychology. We have over 1.5 million books available in our catalogue for you to explore.