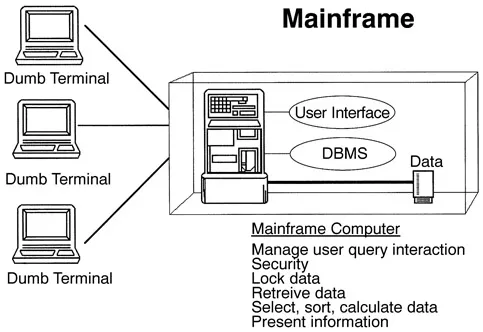
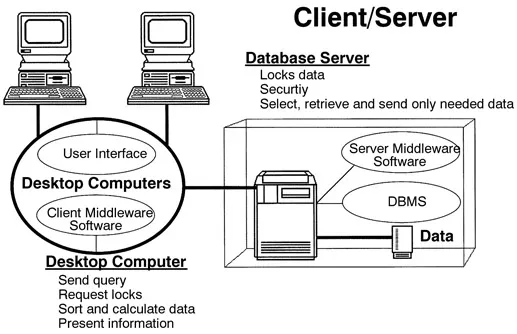
The development of client-server architecture is the major enabling technology behind distributed computing and the driving force towards federating heterogeneous networked databases.5’8 Unlike mainframe architecture, workload is balanced between the client and server (Figure 2). The client handles the user interface-query formulation and results presentation. User-friendly graphics-based client software offers a consistent interface regardless of the underlying support structure. Today’s PC-based client can also manage multiple tasks, such as maintaining simultaneous connections to a variety of sources. The result is transparent access to information sources regardless of location. The server handles the database management tasks and the processing of requests.
Middleware
Connecting the client to the server is a class of software known as middleware. The software components that comprise middleware physically reside on both the client and server. Middleware insures that the client can communicate or interoperate with the server regardless of the different hardware and software involved. Clients and servers generally communicate by using a standardized sequence of messages known as a protocol. A message can be a request from the client for the server to perform an operation, such as search a remote database. A message from the server can be a response to the client, such as the results of a search. The Application Programming Interface (API) is the middleware component that facilitates the transferring of messages between the client and server based on a protocol.
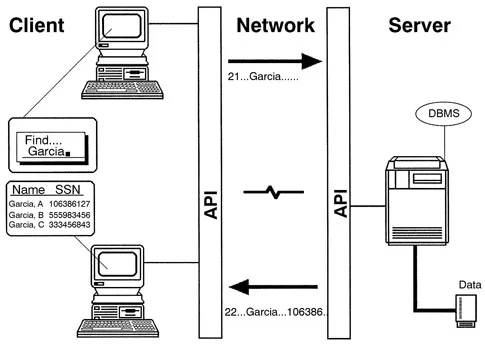
The API protocol defines a set of messages that both the client and server understand (Figure 3). The client’s API translates a message into a form independent of either the client or server that permits travel across the network. The server’s API receives the message and translates it into a form that the server understands. The message is processed, and a response is sent to the client via the server’s API. The client’s API transforms the response into a form that the client understands, and thus completes the transaction.3
FIGURE 3. The Application Programming Interface (API) is the middleware component that facilitates the transfer of messages across the network. The client query is converted into a standardized form that the server’s API can translate and submit to the DBMS. Results are likewise converted into a form that the client’s API can present to the client program.
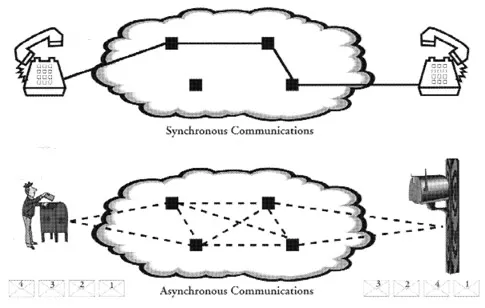
Depending on how the API is implemented, messages can be sent either synchronously or a synchronously (Figure 4). Synchronous models are generally session-oriented. A connection is established and maintained for the duration of a session. A telephone call is based on a synchronous communications model where a connection is maintained for the duration of a conversation. For client-server, a session can be the exchange of a sequence of requests and responses in order to accomplish a specific task. The advantage of this is that the session is stateful. The client and server can use what has previously transpired in the messages that are exchanged and operations that are performed. This is particularly useful in an iterative activity such as searching.
The problem is that the connection is maintained even while the server is waiting for a request from the client, or vice-versa. A connection ties up the resources of both the client and server. Neither the client nor the server can do other activities while in a session, even during periods of inactivity. This may be viewed as an advantage since it insures that a sequence of messages are exchanged in proper order. Nevertheless it is inefficient, and impacts on the scalability of the system. The Remote Procedure Call (RPC) is a synchronous communications implementation common to client-server architecture where operations are executed on remote servers but appear to the client as local functions. Typical of synchronous models, the client is blocked from doing other work until the operation has completed execution and a response is received.
FIGURE 4. In synchronous communications a connection is maintained for the duration of the session. The client is busy until the connection is terminated. In asynchronous communications the client is free to do other tasks as soon as the current task is initiated. However, there is no guarantee that the tasks will complete in the order initiated.
Alternatively, asynchronous models are not session-oriented. A message is sent but the sender does not wait for a response before doing other work. The recipient is not sitting idle waiting for a message. This is similar to sending messages via the postal system, or electronically via E-mail. Multitasking in a modern operating system involves the execution of a task without waiting for the task to complete before initiating the execution of another task. The HTTP protocol used to access information on the World Wide Web is based on an asynchronous communications model. The client establishes a connection with a server in sending a message, such as a request for information. Once the message is sent, the client is free to send messages to other servers. Once the server receives the message and sends the requested information, it closes the connection. If the client wants to send additional messages to the same server, it will have to reestablish a connection with the server. For each message a connection is established and terminated.
Resources are tied up only when needed. During periods of inactivity while waiting for messages, the client and server are free to do other activities. The server, for example, is free to service other requests. This contributes to the system’s scalability. However, since a new connection must be established with each message, state information is not maintained. The server does not remember anything about the previous message. The stateless nature of the asynchronous communications model limits the level of sophistication possible in iterative activities, such as searching. Current research is focused on how to implement stateful asynchronous models.
Regardless of implementation, because the API is well defined for both the client and server, it provides unparalleled flexibility in choosing hardware and software components for both the client and server. As long as the client and server use the same API, their components can be independently upgraded or changed without critically impacting each other. Furthermore, the role of the API as represented in middleware software plays an increasingly strategic role in the evolution of network computing that enables interoperability among heterogeneous systems.
Z39.50
The Z39.50 protocol is an example of a synchronous session-oriented implementation of the client-server architecture specifically designed for database searching and information retrieval on systems that run on different hardware and software. Developed in conjunction with the Library of Congress and bibliographic service providers, the Z39.50 protocol allows databases from different information providers to interoperate. Z39.50 currently supports the search and retrieval of bibliographic records primarily in the MARC format.7’20
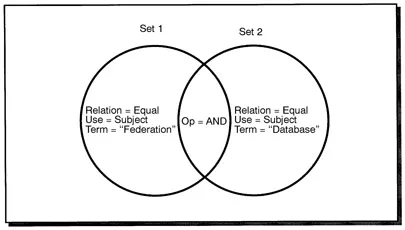
The Z39.50 standard specifies the messages that are exchanged in a session, the structure and semantics of a search query, and how results are returned to the user. The search query is hierarchically structured into sets permitting the inclusion of Boolean operators to connect the sets (Figure 5). Each set includes a search term or phrase, and any parameters that specify which attributes of the record to search, such as author, title or descriptor fields.
Currently the standards assume that the client and server communicate over a stateful connection on the Internet. The dialogue that is created by the exchange of messages between the client and server is called a Z39.50 Associtation. Messages are a sequence of commands and responses. The protocol establishes a set pattern for dialoguing. For each command sent by the client, the server responds with an acknowledgment or the requested information (Figure 6).
FIGURE 5. The Z39.50 query structure is hierarchically arranged into sets. Sets are connected by Boolean operators.
A searcher submits a query using the client interface. The middleware software module on the client is called the Origin. It translates the query into a standardized form specified by the Z39.50 protocol. The Origin initiates a session with the INIT command. The software module on the intended server is called the Target. The Target sends an acknowledgment that the session has started. The Origin sends the query via the SEARCH command. The Target interfaces with the desired database on a remote system. It responds to the query and sends the results of the query back to the Origin. The Origin interfaces with the searcher. The searcher informs the Origin which records to view. The Origin sends a PRESENT command with the specific records to retrieve. Finally, a TERMINATION command is sent to end the session.
Newer versions of the protocol are expected to better support the searching of databases with more diverse record structures. The EXPLAIN command will allow the client to ask the server to describe the contents, the record structure and supported attributes of the database it serves. A full-text document delivery service will also be provided.
Nevertheless, there are limitations to Z39.50. It cannot adequately handle searching full-text documents. Full-text documents often provide a rich and complex set of access point...