This volume introduces the latest popular methods for conducting business research. The goal of each chapter author--a leading authority in a particular subject area--is to provide an understanding of each method with a minimum of mathematical derivations. The chapters are organized within three general interrelated topics--Measurement, Decision Analysis, and Modeling.
The chapters on measurement discuss generalizability theory, latent trait and latent class models, and multi-faceted Rasch modeling. The chapters on decision analysis feature applied location theory models, data envelopment analysis, and heuristic search procedures. The chapters on modeling examine exploratory and confirmatory factor analysis, dynamic factor analysis, partial least squares and structural equation modeling, multilevel data analysis, modeling of longitudinal data by latent growth curve methods and structures, and configural models of longitudinal categorical data.

- 448 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Modern Methods for Business Research
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Subtopic
ManagementIndex
BusinessChapter One
Applied Generalizability Theory Models
California State University, Fullerton
Generalizability (G) theory is a statistical theory about the dependability of behavioral measurements (Shavelson & Webb, 1991). Although many psychometricians can be credited with paving the way for G theory (e.g., Burt, 1936, 1947; Hoyt, 1941; Lindquist, 1953), it was formally introduced by Cronbach and his associates (Cronbach, Gleser, Nanda, & Rajaratnam, 1972; Cronbach, Rajaratnam, & Gleser, 1963; Gleser, Cronbach, & Rajaratnam, 1965) as an extension of classical reliability theory. Since the major publication by Cronbach et al. (1972), G theory has gained increasing attention, as evidenced by the growing number of studies in the literature that apply it (Shavelson, Webb, & Burstein, 1986). The diversity of measurement problems that G theory can solve has developed concurrently with the frequency of its application (Marcoulides, 1989a). Some researchers have gone so far as to consider G theory “the most broadly defined psychometric model currently in existence” (Brennan, 1983, p. xiii). Clearly, the greatest contribution of G theory lies in its ability to model a remarkably wide array of measurement conditions through which a wealth of psychometric information can be obtained (Marcoulides, 1989c).
The purpose of this chapter is to review the major concepts in G theory and illustrate its use as a comprehensive method for designing, assessing, and improving the dependability of behavioral measurements. To gain a perspective from which to view the application of this measurement procedure and to provide a frame of reference, G theory is compared with the more traditionally used classical reliability theory. It is hoped, by providing a clear and understandable picture of G theory, that the practical applications of this technique will be adopted in business and management research. Generalizability theory most certainly deserves the serious attention of all researchers involved in measurement studies.
Overview of Classical Reliability Theory
Classical theory is the earliest theory of measurement and the foundation for many modern methods of reliability estimation (Cardinet, Tourneur, & Allai, 1976). Despite the development of the more comprehensive G theory, classical theory continues to have a strong influence among measurement practitioners today (Suen, 1990). In fact, many tests currently in existence provide psychometric information based on the classical approach. Classical theory assumes that when a test is administered to an individual the observed score is comprised of two components. The first component is the true underlying ability of the examinee, which is the intended target of the measurement procedure. The second component is some combination of unsystematic error in the measurement, which somehow clouds the estimate of the examinee’s true ability. This relationship can be symbolized as:
Observed score (X) = True score (T) + Error (E)
The better a test is at providing an accurate indication of an examinee’s ability, the more accurate the T component will be and the smaller the E component. Classical theory also provides a reliability coefficient that permits the estimation of the degree to which the T component is present in a measurement. The reliability coefficient is expressed as the ratio of the variance of true scores to the variance of observed scores and as the error variance decreases the reliability coefficient increases. Mathematically this relationship is expressed as:
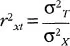
or
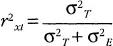
The evaluation of the reliability of a measurement procedure is basically a question of determining how much of the variation in a set of observed scores is a result of the systematic differences among individuals and how much is the result of other sources of variation. Test–retest reliability estimates provide an indication of how consistently a test ranks examinees over time. This type of reliability requires administering a test on two different occasions and examining the correlation between the two test occasions to determine stability over time. Internal consistency is another method for estimating reliability and measures the degree to which individual items within a given test provide similar and consistent results about an examinee. Another method of estimating reliability involves administering two “parallel” forms of the same test at different times and examining the correlation between the forms.
The preceding methods for estimating reliabilities of measurements suggest that it is unclear which interpretation of error is the most appropriate. Obviously, the error variance estimates will vary according to the measurement designs used (i.e., test–retest, internal consistency, parallel forms), as will the estimates of reliability. Unfortunately, because classical theory provides only one definition of error, it is unclear how one should choose between these reliability estimates. Thus, in classical theory one often faces the uncomfortable fact that data obtained from the administration of the same test to the same individuals may yield three different reliability coefficients.
To make this discussion concrete, an example is in order. A personnel manager wishes to measure the job performance of five salespersons by using a simple rating form. The rating form covers such things as effective communication, effectiveness under stress, meeting deadlines, work judgments, planning and organization, and initiative. Two supervisors independently rate the salespersons in terms of their overall perfomance using the rating form on two occasions, with ratings from “not satisfactory” to “superior.” The ratings comprised a 5-point scale. Table 1.1 presents data from the hypothetical example.
Table 1.1 Data From Hypothetical Job Performance Example
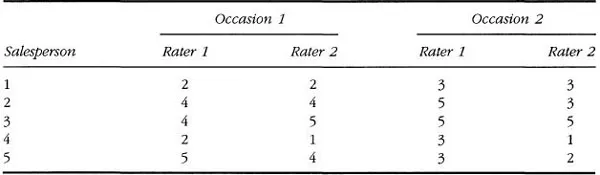
Using the preceding data, how might classical theory calculate the reliability of these jobs performance measures? Obviously, with performance measurements taken on two different occasions, a test–retest reliability can be calculated. A test–retest reliability coefficient is calculated by correlating the salespersons’ scores from Occasion 1 with the scores from Occasion 2, after summing over all other information in the table. This value is approximately 0.73. Of course, an internal consistency reliability can also be calculated. This value is approximately 0.87. Thus, it appears that not only are the estimates of reliability in classical theory different, but they are not even estimates of the same quantity (Webb, Rowley, & Shavelson, 1988). Although classical test theory defines reliability as the ratio of the variance of true scores to the variance of observed scores, as evidenced by the earlier example, one is confronted with changing definitions of what constitutes true and error variance. For example, if one computes a test–retest reliability coefficient, then the day-to-day variation in the salespersons’ performance is counted as error, but the variation due to the sampling of items is not. On the other hand, if one computes an internal consistency reliability coefficient, the variation due to the sampling of dif...
Table of contents
- Cover
- Half Title
- Title Page
- Copyright Page
- Table of Contents
- Preface
- 1. Applied Generalizability Theory Models
- 2. Latent Trait and Latent Class Models
- 3. Measurement Designs Using Multifacet Rasch Modeling
- 4. Applied Location Theory Models
- 5. Data Envelopment Analysis: An Introduction and an Application to Bank Branch Performance Assessment
- 6. Heuristic Search Methods
- 7. Factor Analysis: Exploratory and Confirmatory Approaches
- 8. Dynamic Factor Analysis
- 9. Structural Equation Modeling
- 10. The Partial Least Squares Approach for Structural Equation Modeling
- 11. Methods for Multilevel Data Analysis
- 12. Modeling Longitudinal Data by Latent Growth Curve Methods
- 13. Structural and Configural Models for Longitudinal Categorical Data
- Author Index
- Subject Index
- About the Authors
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Modern Methods for Business Research by George A. Marcoulides in PDF and/or ePUB format, as well as other popular books in Business & Management. We have over 1.5 million books available in our catalogue for you to explore.