![]()
1
Introduction
There is a difference between data and information. We hear about big data. In most cases, the humongous amount of data contains only concise information. For example, when we read a news report, we get the gist from the title of the article. The actual text has just the details and does not add much to the information content. Loosely speaking, the text is the data and the title is its information content.
The fact that data is compressible has been known for ages; that is, the field of statistics—the art and science of summarizing and modeling data—was developed. The fact that we can get the essence of millions of samples from only a few moments or represent it as a distribution with very few parameters points to the compressibility of data.
Broadly speaking, compressed sensing deals with this duality—abundance of data and its relatively sparse information content. Truly speaking, compressed sensing is concerned with an important sub-class of such problems—where the sparse information content has a linear relationship with data. There are many such problems arising in real life. We will discuss a few of them here so as to motivate you to read through the rest of the book.
Machine Learning
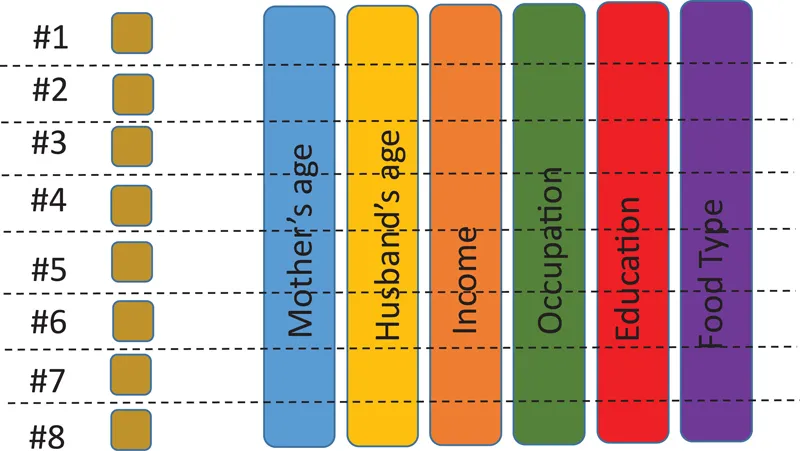
Consider a health analyst trying to figure out what are the causes of infant mortality in a developing country. Usually, when an expecting mother comes to a hospital, she needs to fill up a form. The form asks many questions: for example, the date of birth of the mother and father (thereby their ages), their education level, their income level, type of food (vegetarian or otherwise), number of times the mother has visited the doctor, and the occupation of the mother (housewife or otherwise). Once the mother delivers the baby, the hospital keeps a record of the baby’s condition. Therefore, there is a one-to-one correspondence between the filled-up form and the condition of the baby. From this data, the analyst tries to find out what are the factors that lead to the outcome (infant mortality).
FIGURE 1.1
Health record and outcome.
For simplicity, the analyst can assume that the relationship between the factors (age, health, income, etc.) and the outcome (mortality) is linear, so that it can be expressed as shown in the following (Figure 1.1).
Formally, this can be expressed as follows:
where b is the outcome, H is the health record (factors along columns and patients along rows), and x is the (unknown) variable that tells us the relative importance of the different factors. The model allows for some inconsistencies in the form of noise n.
In the simplest situation, we will solve it by assuming that the noise is normally distributed; we will minimize the l2-norm.
However, the l2-norm will not give us the desired solution. It will yield an x that is dense, that is, will have non-zero values in all positions. This would mean that ALL the factors are somewhat responsible for the outcome. If the analyst says so, the situation would not be very practical. It is not possible to control all aspects of the mother (and her husband’s) life. Typically, we can control only a few factors, not all. But the solution (1.2) does not yield the desired solution.
Such types of problems fall under the category of regression. The simplest form of regression, the ridge regression/Tikhonov regularization (1.3), does not solve the problem either.
| (1.3) |
This too yields a dense solution, which in our example is ineffective. Such problems have been studied for long statistics. Initial studies in this area proposed greedy solutions, where each of the factors was selected following some heuristic criterion. In statistics, such techniques were called sequential forward selection; in signal processing, they were called matching pursuit.
The most comprehensive solution to this problem is from Tibshirani; he introduced the Least Angle Selection and Shrinkage Operator (LASSO). He proposed solving,
| (1.4) |
The l1-norm penalty promotes a sparse solution (we will learn the reason later). It means that x will have non-zero values only corresponding to certain factors, and the rest will be zeroes. This would translate to important (non-zero) and unimportant (zero) factors. Once we decide on a few important factors, we can concentrate on controlling them and improving child mortality.
However, there is a problem with the LASSO solution. It only selects the most important factor from the set of related factors. For example, in child’s health, it is medically well known that the parents’ age is an important aspect. Therefore, we consider the age of both parents. If LASSO is given a free run (without any medical expe...