
eBook - ePub
Resilience Engineering
Concepts and Precepts
- 416 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Resilience Engineering
Concepts and Precepts
About this book
For Resilience Engineering, 'failure' is the result of the adaptations necessary to cope with the complexity of the real world, rather than a breakdown or malfunction. The performance of individuals and organizations must continually adjust to current conditions and, because resources and time are finite, such adjustments are always approximate. This definitive new book explores this groundbreaking new development in safety and risk management, where 'success' is based on the ability of organizations, groups and individuals to anticipate the changing shape of risk before failures and harm occur. Featuring contributions from many of the worlds leading figures in the fields of human factors and safety, Resilience Engineering provides thought-provoking insights into system safety as an aggregate of its various components, subsystems, software, organizations, human behaviours, and the way in which they interact. The book provides an introduction to Resilience Engineering of systems, covering both the theoretical and practical aspects. It is written for those responsible for system safety on managerial or operational levels alike, including safety managers and engineers (line and maintenance), security experts, risk and safety consultants, human factors professionals and accident investigators.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Chapter 1
Resilience – the Challenge of the Unstable
Safety is the sum of the accidents that do not occur. While accident research has focused on accidents that occurred and tried to understand why, safety research should focus on the accidents that did not occur and try to understand why.
Understanding Accidents
Research into system safety is faced with the conundrum that while there have been significant developments in the understanding of how accidents occur, there has been no comparable developments in the understanding of how we can adequately assess and reduce risks. A system is safe if it is impervious and resilient to perturbations and the identification and assessment of possible risks is therefore an essential prerequisite for system safety. Since accidents and risk assessment furthermore are two sides of the same coin, so to speak, and since both are constrained in equal measure by the underlying models and theories, it would be reasonable to assume that developments in system safety had matched developments in accident analysis. Just as we need to have an aetiology of accidents, a study of possible causes or origins of accidents, we also need to have an aetiology of safety – more specifically of what safety is and of how it may be endangered. This is essential for work on system safety in general and for resilience engineering in particular. Yet for reasons that are not entirely clear, such a development has been lacking.
The value or, indeed, the necessity of having an accident model has been recognised for many years, such as when Benner (1978) noted that:
Practical difficulties arise during the investigation and reporting of most accidents. These difficulties include the determination of the scope of the phenomenon to investigate, the identification of the data required, documentation of the findings, development of recommendations based on the accident findings, and preparation of the deliverables at the end of the investigation. These difficulties reflect differences in the purposes for the investigations, which in turn reflect different perceptions of the accident phenomenon.
The ‘different perceptions of the accident phenomenon’ are what in present day terminology are called the accident models. Accident models seem to have started by relatively uncomplicated single-factor models of, e.g., accident proneness (Greenwood & Woods, 1919) and developed via simple and complex linear causation models to present-day systemic or functional models (for a recent overview of accident models, see Hollnagel, 2004.)
The archetype of a simple linear model is Heinrich’s (1931) Domino model, which explains accidents as the linear propagation of a chain of causes and effects (Figure 1.1). This model was associated with one of the earliest attempts of formulating a complete theory of safety, expressed in terms of ten axioms of industrial safety (Heinrich et al., 1980, p. 21). The first of these axioms reads as follows:
The occurrence of an injury invariably results from a completed sequence of factors – the last one of these being the accident itself. The accident in turn is invariably caused or permitted directly by the unsafe act of a person and/or a mechanical or physical hazard.
According to this view, an accident is basically a disturbance inflicted on an otherwise stable system. Although the domino model has been highly useful by providing a concrete approach to understanding accidents, it has unfortunately also reinforced the misunderstanding that accidents have a root cause and that this root cause can be found by searching backwards from the event through the chain of causes that preceded it. More importantly, the domino model suggests that system safety can be enhanced by disrupting the linear sequence, either by ‘removing’ a ‘domino’ or by ‘spacing’ the ‘dominos’ further apart. (The problems in providing a translation from model components to the world of practice are discussed further in Chapter 17.)
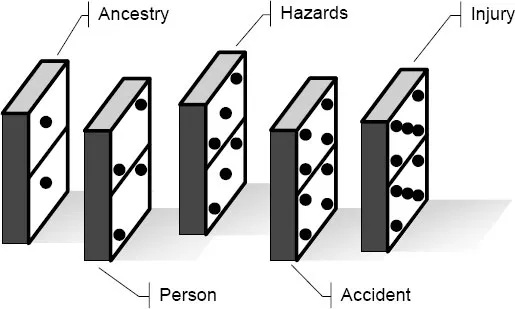
Figure 1.1: Simple linear accident model (Domino model)
The comparable archetype of a complex linear model is the well-known Swiss cheese model first proposed by Reason (1990). According to this, accidents can be seen as the result of interrelations between real time ‘unsafe acts’ by front-line operators and latent conditions such as weakened barriers and defences, represented by the holes in the slices of ‘cheese’, cf. Figure 1.2. (Models that describe accidents as a result of interactions among agents, defences and hosts are also known as epidemiological accident models.) Although this model is technically more complex than the domino model, the focus remains on structures or components and the functions associated with these, rather than on the functions of the overall system as such. The Swiss cheese model comprises a number of identifiable components where failures (and risks) are seen as due to failures of the components, most conspicuously as the breakdown of defences. Although causality is no longer a single linear propagation of effects, an accident is still the result of a relatively clean combination of events, and the failure of a barrier is still the failure of an individual component. While the whole idea of a complex linear model such as this is to describe how coincidences occur, it cannot detach itself from a structural perspective involving the fixed relations between agents, hosts, barriers and environments.
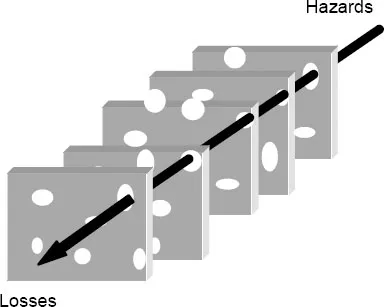
Figure 1.2: Complex linear accident model (Swiss cheese model)
Since some accidents defy the explanatory power of even complex linear models, alternative explanations are needed. Many authors have pointed out that accidents can be seen as due to an unexpected combination or aggregation of conditions or events (e.g., Perrow, 1984). A practical term for this is concurrence, meaning the temporal property of two (or more) things happening at the same time and thereby affecting each other. This has led to the view of accidents as non-linear phenomena that emerge in a complex system, and the models are therefore often called systemic accident models, cf., Chapter 4.
This view recognises that complex system performance always is variable, both because of the variability of the environment and the variability of the constituent subsystems. The former may appropriately be called exogenous variability, and the latter endogenous variability. The endogenous variability is to a large extent attributable to the people in the system, as individuals and/or groups. This should nevertheless not be taken to imply that human performance is wrong or erroneous in any way. On the contrary, performance variability is necessary if a joint cognitive system, meaning a human-machine system or a socio-technical system, is successfully to cope with the complexity of the real world (Hollnagel & Woods, 2005). The essence of the systemic view can be expressed by the following four points:
• Normal performance and as well as failures are emergent phenomena. Neither can therefore be attributed to or explained by referring to the (mal)functions of specific components or parts. Normal performance furthermore differs from normative performance: it is not what is prescribed by rules and regulation but rather what takes place as a result of the adjustments required by a partly unpredictable environment. Technically speaking, normal performance represents the equilibrium that reflects the regularity of the work environment.
• The outcomes of actions may sometimes differ from what was intended, expected or required. When this happens it is more often due to variability of context and conditions than to the failures of actions (or the failure of components or functions). On the level of individual human performance, local optimisation or adjustment is the norm rather than the exception as shown by the numerous shortcuts and heuristics that people rely on in their work.
• The adaptability and flexibility of human work is the reason for its efficiency. Normal actions are successful because people adjust to local conditions, to shortcomings or quirks of technology, and to predictable changes in resources and demands. In particular, people quickly learn correctly to anticipate recurring variations; this enables them to be proactive, hence to save the time otherwise needed to assess a situation.
• The adaptability and flexibility of human work is, however, also the reason for the failures that occur, although it is rarely the cause of such failures. Actions and responses are almost always based on a limited rather than complete analysis of the current conditions, i.e., a trade-off of thoroughness for efficiency. Yet since this is the normal mode of acting, normal actions can, by definition, not be wrong. Failures occur when this adjustment goes awry, but both the actions and the principles of adjustment are technically correct.
Accepting a specific model does not only have consequences for how accidents are understood, but also for how resilience is seen. In a simple linear model, resilience is the same as being impervious to specific causes; using the domino analogy, the pieces either cannot fall or are so far apart that the fall of one cannot affect its neighbours. In a complex linear model, resilience is the ability to maintain effective barriers that can withstand the impact of harmful agents and the erosion that is a result of latent conditions. In both cases the transition from a safe to an unsafe state is tantamount to the failure of some component or subsystem and resilience is the ability to endure harmful influences. In contrast to that, a systemic model adopts a functional point of view in which resilience is an organisation’s ability efficiently to adjust to harmful influences rather than to shun or resist them. An unsafe state may arise because system adjustments are insufficient or inappropriate rather than because something fails. In this view failure is the flip side of success, and therefore a normal phenomenon.
Anticipating Risks
Going from accident analysis to risk assessment, i.e., from understanding what has happened to the identification of events or conditions that in the future may endanger system safety, it is also possible to find a number of different models of risks, although the development has been less noticeable. Just as there are single-factor accident models, there are risk assessment models that consider the failure of individual components, such as Failure Mode and Effects Analysis. Going one step further, the basic model to describe a sequence of actions is the event tree, corresponding to the simple linear accident model. The event tree represents a future accident as a result of possible failures in a pre-determined sequence of events organised as a binary branching tree. The ‘root’ is the initiating event and the ‘leaves’ are the set of possible outcomes – either successes or failures. In a similar manner, a fault tree corresponds to a complex linear model or an epidemiological model. The fault tree describes the accident as the result of a series of logical combinations of conditions, which are necessary and sufficient to produce the top event, i.e., the accident (cf. Figure 1.3).
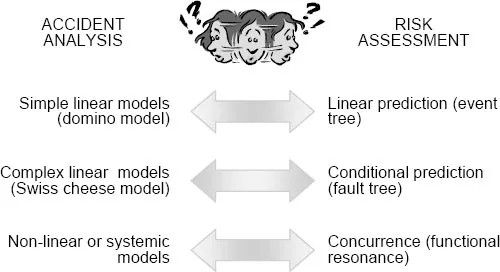
Figure 1.3: Models for accident analysis and risk assessment
Event trees and fault trees may be adequate for risk assessment when the outcomes range from incidents to smaller accidents, since these often need less elaborate explanations and may be due to relatively simple combinations of factors. Most major accidents, however, are due to complex concurrences of multiple factors, some of which have no apparent a priori relations. Event and fault trees are therefore unable fully to describe them – although this does not prevent event trees from being the favourite tool for Probabilistic Safety Assessment methods in general. It is, indeed, a consequence of the systemic view that the potential for (complex) accidents cannot be described by a fixed structure such as a tree, graph or network, but must invoke some way of representing dynamic bindings or couplings, for instance as in the functional resonance accident model (Hollnagel, 2004). Indeed, the problems of risk assessment may to a large degree arise from a reliance on graphical representations, which – as long as they focus on descriptions of links between parts – are unable adequately to account for concurrence and for how a stable system slowly or abruptly may become unstable.
The real challenge for system safety, and therefore also for resilience engineering, is to recognise that complex systems are dynamic and that a state of dynamic stability sometimes may change into a state of dynamic instability. This change may be either abrupt, as in an accident, or slow, as in a gradual erosion of safety margins. Complex systems must perforce be dynamic since they must be able to adjust their performance to the conditions, cf. the four points listed above. These adjustments cannot be pre-programmed or built into the system, because they cannot be anticipated at the time of design – and sometimes not even later. It is practically impossible to design for every little detail or every situation that may arise, something that procedure writers have learned to their dismay. Complex systems must, however, be dynamically stable, or constrained, in the sense that the adjustments do not get out of hand but at all times remain under control. Technically this can be expressed by the concept of damping, which denotes the progressive reduction or suppression of deviations or oscillation in a device or system (over time). A system must obviously be able to respond to changes and challenges, but the responses must not lead the system to lose control. The essence of resilience is therefore the intrinsic ability of an organisation (system) to maintain or regain a dynamically stable state, which allows it to continue operations after a major mishap and/or in the presence of a continuous stress.
Dictionaries commonly define resilience as the ability to ‘recover quickly from illness, change, or misfortune’, one suggestive synonym being buoyancy or a bouncing quality. Using this definition, it stands to reason that it is easier to recover from a potentially destabilising disturbance if it is detected early. The earlier an adjustment is made, the smaller the resulting adjustments are likely to be. This has another beneficial effect, which is a corollary of the substitution myth. According to this, artefacts are value neutral in the sense that the introduction of an artefact into a system only has the intended and no unintended effects (Hollnagel & Woods, 2005, p. 101). Making a response to or recovering from a disturbance requires an adjustment, hence a change to the system. Any such change may have consequences that go beyond the local and intended effects. If the consequences from the recovery are small, i.e., if they can effectively be confined to a subsystem, then the likelihood of negative side-effects is reduced and the resilience is therefore higher. As a result of this, the definition of resilience can be modified to be the ability of a system or an organisation to react to and recover from disturbances at an early stage, with minimal effect on the dynamic stability. The challenges to system safety come from instability, and resilience engineering is an expression of the methods and principles that prevent this from taking place.
For the analytical part, resilience engineering amounts to a systemic accident model as outlined above. Rather than looking for causes we should look for concurrences, and rather than seeing concurrences as exceptions we should see them as normal and therefore also as inevitable. This may at times lead to the conclusion that even though an accident happened nothing really went wrong, in the sense that nothing happened that was out of the ordinary. Instead it is the concurrence of a number of events, just on the border of the ordinary, that constitutes an explanation of the accident or event.
For the predictive part, resilience engineering can be addressed, e.g., by means of a functional risk identification method, such as proposed by the functional resonance accident model (Hollnagel, 2004). To make progress on resilience engineering we have to go beyond failure modes of component (subsystem, human) to concurrences. This underlines the functional view since concurrences take place among events and functions rather than among components. The challenge is understand when a system may lose its dynamic stability and become unstable. To do so requires powerful methods combined with plenty of imagination (Adamski & Westrum, 2003).
Systems are Ever-Changing
No system (i.e., combination of artifact and humans) can avoid changes. Changes occur continuously throughout a system’s lifetime. This should be regarded as a destiny. The incompleteness of a system is partly attributable to this ever-changing nature. Changes take place because of external drivers (e.g., economic pressure). But changes also take place because of internal drivers. For instance, humans are always motivated to make changes that they think will improve system administration; humans often find unintended ways of utilizing the artifact; leaders are encouraged to introduce new visions in order to stimulate and lead people; … Like these, the system is always subject to changes, hence metamorphosing itself like a living matter. This floating nature often causes mismatches between administrative frameworks and the ways in which the sys...
Table of contents
- Cover
- Half Title
- Title Page
- Copyright Page
- Table of Contents
- PREFACE
- PROLOGUE: RESILIENCE ENGINEERING CONCEPTS
- PART I: EMERGENCE
- PART II: CASES AND PROCESSES
- PART III: CHALLENGES FOR A PRACTICE OF RESILIENCE ENGINEERING
- EPILOGUE: RESILIENCE ENGINEERING PRECEPTS
- APPENDIX
- BIBLIOGRAPHY
- AUTHOR INDEX
- SUBJECT INDEX
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Resilience Engineering by David D. Woods, Erik Hollnagel,David D. Woods,Nancy Leveson, Erik Hollnagel in PDF and/or ePUB format, as well as other popular books in Technology & Engineering & Transportation Industry. We have over 1.5 million books available in our catalogue for you to explore.