
eBook - ePub
Mechanisms in the Chain of Safety
Research and Operational Experiences in Aviation Psychology
- 192 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Mechanisms in the Chain of Safety
Research and Operational Experiences in Aviation Psychology
About this book
How should we organize our selection or training procedures? In what way can a flight crew mediate problems? How are we to understand reported errors? Mechanisms in the Chain of Safety presents recent findings in aviation psychology, bringing fresh insights to such questions. Aviation psychologists study personnel selection and training; they evaluate the management of flight operations, and ultimately they analyse the things that went wrong. The strong interrelation between these components allows us to talk about a chain of safety. This volume appraises this chain of safety by considering the mechanisms that determine its effectiveness - input mechanisms, coping mechanisms and control mechanisms. Each contribution discusses a component of the chain while the book as a whole emphasizes and illustrates that understanding the connections between these parts is essential for the future. By addressing these issues the book leads to further considerations such as how mistakes are linked to training and how coping mechanisms should help us to understand errors and accidents. Mechanisms in the Chain of Safety will appeal to aviation professionals (human factors experts, safety managers, pilots, ATCOs, air navigation service providers, etc.) and academics, researchers, graduates and postgraduates in human factors and psychology. Although primarily written for the aviation industry, this book will also be of interest to other high-risk dynamic activities that face similar challenges: the need to present effective and safe outcomes to the public in general and the stakeholders in particular.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Chapter 1
GAP: Assessment of Performance in Teams – A New Attempt to Increase Validity
Introduction
Safe and effective performance in aviation, for example pilot proficiency, demands not only excellent technical knowledge, but also pronounced interpersonal competence, which includes the selection and distribution of information, cooperative goal orientation and of course decision making. Moreover, skills in leadership and conflict management are required (Maschke and Rother, 2006).
Modern pilot training methods reflect these demands. “Human performance and limitations”, “multi-crew coordination training” and “crew resource management training” are important subjects in the airline pilot education and licensing process.
In order to select skilled candidates for training, a psychological selection including group assessment methods is employed by many airlines and air traffic controller organizations (Goeters, 2003). These methods typically comprise group discussion, group planning and prioritization tasks. The applicant’s behavior is observed, registered by the observers using paper and pencil, and lastly, rated within a given guideline framework.
With the advance of computer and information technology there are two significant reasons why these methods require updating (Huelmann and Oubaid, 2004). First, typical tasks in the working environment of pilots are located at the human-machine gateway. Second, in conventional assessment center exercises, the objectivity of behavior ratings is comparatively lower than in other psychological methods. This is due to observer errors, complex interactions, and time-absorbing behavior reporting (paper and pencil).
A further problem of those aforementioned methods is the often low interrater reliability among different observers. This is also a direct result of the varying consideration of which exhibited behavior is deemed significant for a certain dimension. Additionally, noting observations by hand draws the observer’s attention away from the continuing process of interaction. This results in missing or misperceiving behavioral units, an additional negative effect on reliability.
To overcome those problems, a computer-based group test system (GAP Assessment®; Group Assessment of Performance and Behaviour; Oubaid, 2007; Oubaid, Zinn and Klein, 2008) was developed in which behavior observations made by four experts (consisting of training captains and aviation psychologists) and objective behavior measures are integrated into an overall evaluation. The basis of the multi-level observations are taxonomically derived complex scenarios in which three or four applicants gradually receive different assignments and interact with each other face-to-face as well as through their individual touchscreen monitors that are part of the GAP network (see Figure 1.1).
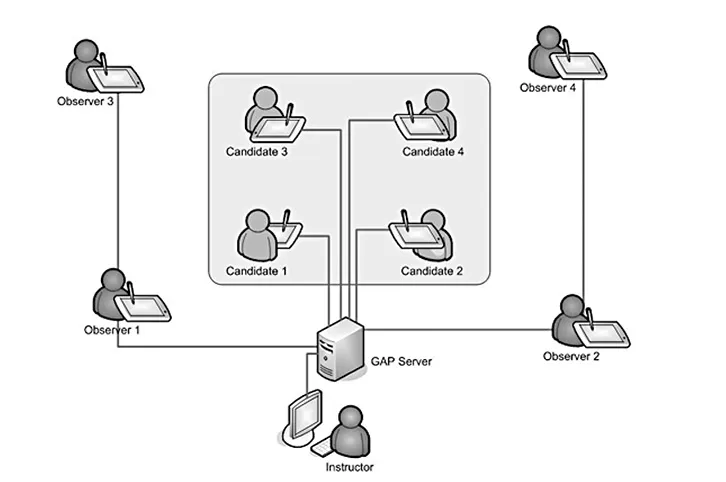
Figure 1.1 Overview of the GAP Assessment® network including four observers and four applicants
Method
As a first step, a behavioral observation model was developed that also functions as the backbone for the scenario construction. This model is based on three sources: (1) the set of basic competencies used in Lufthansa pilot training, which includes basic interpersonal, technical and procedural competencies for a safe flight accomplishment (Lufthansa, 1999). (2) The VERDI Circumplex Behavioral model for DLR pilot selection (for example, Hoeft, 2003). (3) A Fleishman job requirement analysis for airline pilots (Maschke, Goeters and Klamm, 2000) was integrated to elaborate the areas of competence. Six areas of competence could be identified: leadership, teamwork, communication, decision making, adherence to procedures, and workload management.
As a second step, individual behavioral units – the behavioral anchors – were derived to translate the areas of competence into practice. These anchors were presented to assessment-center experts (aviation psychologists, training captains) to be rated regarding their prototypic assignment to the areas of competence following the Act Frequency Approach (Buss and Craik, 1980, 1983). The behavioral anchors were then combined into behavioral subsets (GAP sets). These GAP sets are the basis of behavioral observation in GAP scenarios. In the final version, three different categories of strain symptoms (hypomotor/hypermotor, vegetative, and paralinguistic symptoms) were integrated.
During four sequences the observers use a touch-screen to assign behavioral anchors to register the behavioral units which were presented by the applicants (see Figure 1.2).
The observer’s screen also includes:
• feedback information about tasks the applicants are currently working on;
• feedback about certain performance parameters like talk-time, matching-task, or errors made;
• notifications about individual and group messages given by the instructors to intervene.
After each sequence, additional clinical ratings of the past performance are given by observers (for all applicants) and by the applicants (self-rating and peer-rating): rating leadership, teamwork and effectiveness. The observers rate two further dimensions: stress resistance and authenticity.
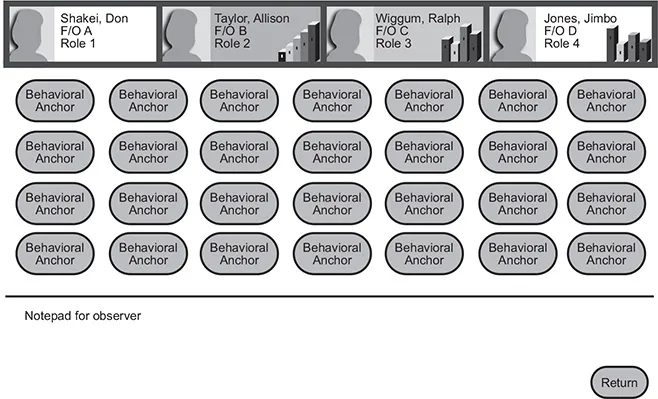
Figure 1.2 Overview of the GAP Assessment® observer screen
Typically, candidates tend to overestimate their behavior in assessment centers (Sarges, 1990, p. 529). GAP Assessment® enhances the quality of self-evaluation by implementing objective self-awareness during the self-evaluation process. According to the Self-awareness theory, people who focus their attention on themselves evaluate and compare their behavior to their internal standards and values (Duval and Wicklund, 1972). In GAP Assessment®, the self-awareness condition is assisted by presenting the candidate’s photograph during self-rating. The photograph is taken during instruction time and also used for the subsequent peer-rating.
To augment the connection between the set of required competencies, the behavioral anchors and the roles played by applicants, scenarios were created on the basis of these anchors. The resulting GAP Assessment® scenario consists of four sequences. Sequences one and three contain schedule planning. Sequences two and four are conflict tasks in which the individual interests are not fully compatible to each other. In one example scenario, each candidate is one of three or four flight attendants. His or her role involves planning, which entails the rearrangement of passengers on a flight and rotation schedules. The role also involves conflict tasks, which include group decisions about an unattractive rotation and the nomination of an executive position. The information presented on the applicant’s screen contains both individual and group role details, task instructions and a set of working rules and restrictions. To estimate the applicant’s cognitive workload, a simple matching task is presented during the whole scenario. It involves a pair of randomly drawn letters with a refresh-rate of five seconds (see Figure 1.3).

Figure 1.3 Example of the GAP Assessment® applicant’s screen
Results
The analysis focussed on three aspects:
• statistics for the GAP anchor measures;
• the quality of additional dimensional post-sequence ratings (self-rating versus peer- rating and observer rating);
• correlations between GAP variables and DLR assessment variables.
The sample consisted of N = 131 applicants, n = 115 males, and n = 16 females. The ratio of males versus females reflects approximately the typical ratio of pilot applicant groups. The mean age was 20.9 years. The data was collected between May and July 2010.
The GAP competence areas did not correlate significantly with age or school grades (A-level). However, there was one exception, decision making multiplied by age (see Table 1.1).
Table 1.1 Correlations of GAP anchor scores with biographical data
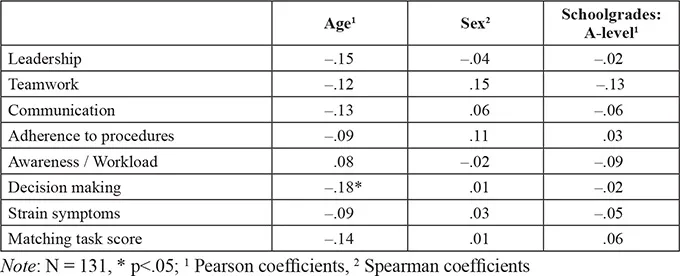
Table 1.2 displays the correlations between the post-hoc observer ratings with self-ratings and peer-ratings.
Table 1.2 Pearson correlations of observer ratings with self-ratings and peer-ratings
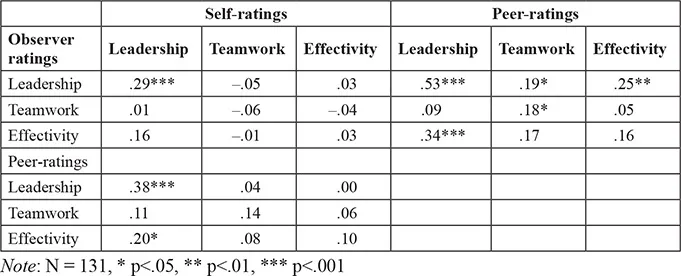
Self-ratings and peer-ratings show a high congruence for leadership.
Table 1.3 Pearson correlations of observer’s GAP anchor scores with GAP dimensional ratings
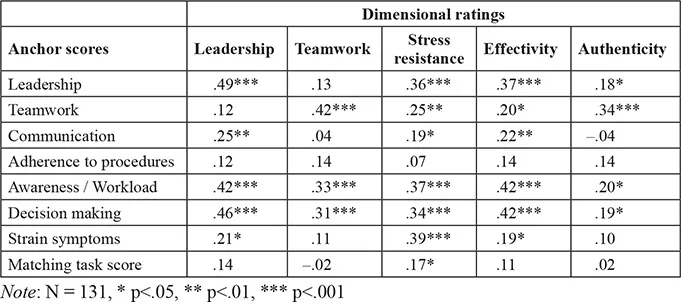
The anchor-based observation results in a comparatively high accordance of judgements with the post-hoc dimensional ratings (Table 1.3). The high correlations of decision making and awareness/workload anchor scores with all dimensional ratings are remarkable and can be attributed to the highly structured GAP tasks.
In the next analysis, GAP anchor scores were compared with the judgements of assessment center experts using the VERDI Circumplex Behavioral model (Hoeft, 2003) and the DCT-Scheme (Stelling, 1999) for DLR pilot selection. The statistical analysis includes comparisons of these judgements on different levels (see Tables 1.4 and 1.5).
Table 1.4 Correlations of GAP anchor scores with VERDI dimensional ratings
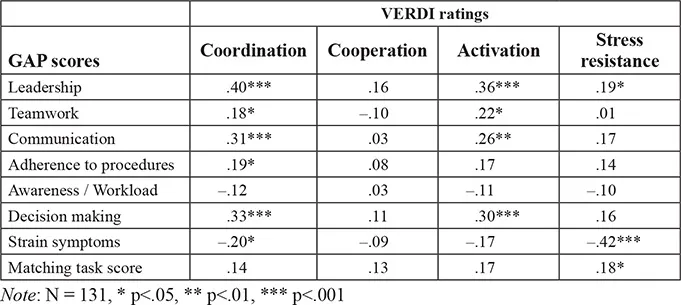
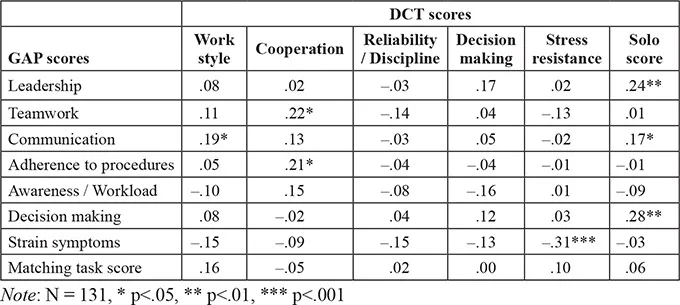
Table 1.5 shows the correlations of GAP anchor scores with DCT scores.
Table 1.5 Correlations of GAP anchor scores with DCT scores
Most correlations are plausible and convincing. As expected, correlations between GAP leadership and VERDI coordination are highest due to their common definition. Also, the significant correlation between the matching task and VERDI stress resistance is easy to interpret, because VERDI stress resistance involves the ability to work under stress. The main unexpected result is the low correlation between VERDI cooperation and all GAP variables, namely GAP teamwork. A possible explanation is that VERDI cooperation involves more non-verbal aspects.
The correlations with the DCT are mostly low. One exp...
Table of contents
- Cover Page
- Title Page
- Copyright Page
- Contents
- List of Figures
- List of Tables
- About the Editors
- List of Contributors
- Acknowledgements
- Introduction: Mechanisms in the Chain of Safety
- 1 GAP: Assessment of Performance in Teams – A New Attempt to Increase Validity
- 2 The Importance of Prospective Memory for the Selection of Air Traffic Controllers
- 3 Analysis of Learning Curves in On-the-Job Training of Air Traffic Controllers
- 4 How Cockpit Crews Successfully Cope with High Task Demands
- 5 Manual Flying Skill Decay: Evaluating Objective Performance Measures
- 6 Civil Pilots’ Stress and Coping Behaviors: A Comparison Between Taiwanese and Non-Taiwanese Aviators
- 7 Anticipatory Processes in Critical Flight Situations
- 8 Error Detection During Normal Flight Operations: Resilient Systems in Practice
- 9 The Role of GPS in Aviation Incidents and Accidents
- 10 Creating Safer Systems: PIRATe (The Proactive Integrated Risk Assessment Technique)
- 11 Safety Reporting System as a Foundation for a Safety Culture
- 12 Conclusions: Extending the Chain
- Author Index
- Subject Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Mechanisms in the Chain of Safety by Teresa C. D'Oliveira, Teresa D'Oliveira,Alex de Voogt,Teresa C D'Oliveira, Teresa C D'Oliveira, Alex de Voogt in PDF and/or ePUB format, as well as other popular books in Technology & Engineering & Industrial Engineering. We have over 1.5 million books available in our catalogue for you to explore.