Health care is everywhere under tremendous pressure with regard to efficiency, safety, and economic viability - to say nothing of having to meet various political agendas - and has responded by eagerly adopting techniques that have been useful in other industries, such as quality management, lean production, and high reliability. This has on the whole been met with limited success because health care as a non-trivial and multifaceted system differs significantly from most traditional industries. In order to allow health care systems to perform as expected and required, it is necessary to have concepts and methods that are able to cope with this complexity. Resilience engineering provides that capacity because its focus is on a system's overall ability to sustain required operations under both expected and unexpected conditions rather than on individual features or qualities. Resilience engineering's unique approach emphasises the usefulness of performance variability, and that successes and failures have the same aetiology. This book contains contributions from acknowledged international experts in health care, organisational studies and patient safety, as well as resilience engineering. Whereas current safety approaches primarily aim to reduce or eliminate the number of things that go wrong, Resilient Health Care aims to increase and improve the number of things that go right. Just as the WHO argues that health is more than the absence of illness, so does Resilient Health Care argue that safety is more than the absence of risk and accidents. This can be achieved by making use of the concrete experiences of resilience engineering, both conceptually (ways of thinking) and practically (ways of acting).

- 296 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Resilient Health Care
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Topic
MedicinePART I
Health Care as a Multiple Stakeholder, Multiple Systems Enterprise
Chapter 1
Making Health Care Resilient: From Safety-I to Safety-II
Safety as the Freedom From Unacceptable Risk
Safety has traditionally been defined as a condition where nothing goes wrong. Or rather, since we know that it is impossible to ensure that nothing goes wrong, as a condition where the number of things that go wrong is acceptably small – whatever ‘acceptably’ may mean. This is, however, an indirect and somewhat paradoxical definition since safety is defined by what it is not, by what happens when it is missing, rather than by what it is. One consequence of this definition is that safety is measured indirectly, not by its presence or as a quality in itself, but by the consequences of its absence.
In relation to human activity it makes good practical sense to focus on situations where things go wrong, both because such situations by definition are unexpected and because they may lead to unintended and unwanted harm or loss of life and property. Throughout the ages, the starting point for safety concerns has therefore been the occurrence, potential or actual, of some kind of adverse outcome, whether it has been categorised as a risk, a hazard, a near miss, an incident, or an accident. Historically speaking, new types of accidents have been accounted for by the introduction of new types of causes (e.g. metal fatigue, ‘human error,’ organisational failure) rather than by challenging or changing the basic underlying assumption of causality. We have, therefore, through centuries become so accustomed to explaining accidents in terms of cause–effect relations – simple or compound – that we no longer notice it. And we cling tenaciously to this tradition, although it has becomes increasingly difficult to reconcile with reality.
Habituation
An unintended but unavoidable consequence of associating safety with things that go wrong is a creeping lack of attention to things that go right. The psychological explanation for that is called habituation, a form of adaptive behaviour that can be described as non-associative learning. Through habituation we learn to disregard things that happen regularly, simply because they happen regularly. In academic psychology, habituation has been studied at the level of neuropsychology and also has usually been explained at that level (Thompson and Spencer, 1966).
It is, however, entirely possible also to speak about habituation at the level of everyday human behaviour (actions and responses). This was noted as far back as 1890, when William James, one of the founding fathers of psychology, wrote that ‘habit diminishes the conscious attention with which our acts are performed’ (James, 1890: 114). In today’s language it means that we stop paying attention to something as soon as we get used to doing it. After some time, we neither notice that which goes smoothly nor do we think it is necessary to do so. This applies both to actions and their outcomes – both what we do ourselves and what others do.
From an evolutionary perspective, as well as from the point of view of an efficiency-thoroughness trade-off (Hollnagel, 2009a), habituation makes a lot of sense. While there are good reasons to pay attention to the unexpected and the unusual, it may be a waste of time and effort to pay much attention to that which is common or similar. To quote James again: ‘Habitual actions are certain, and being in no danger of going astray from their end, need no extraneous help’ (p. 149). Reduced attention is precisely what happens when actions regularly produce the intended and expected results and when things ‘simply’ work. When things go right there is no recognisable difference between the expected and the actual, hence nothing that attracts attention or initiates an arousal reaction. Neither is there any motivation to try to understand why things went well: they obviously went well because the system – people and technology – worked as it should and because nothing untoward happened. While the first argument – the lack of a noticeable difference between outcomes – is acceptable, the second argument is fatally flawed. The reason for that will become clear in the following.
Looking at What Goes Wrong Rather Than Looking at What Goes Right
To illustrate the consequences of looking at what goes wrong rather than looking at what goes right, consider Figure 1.1. This represents the case where the (statistical) probability of a failure is 1 out of 10,000 – technically written as p = 10-4. This means that for every time we expect that something will go wrong (the thin line), there are 9,999 times where we should expect that things will go right and lead to the outcome we want (the grey area). The ratio of 1:10,000 corresponds to a system or organisation where the emphasis is on performance (cf. Amalberti, 2006); the ratio would be even more extreme for an ultra-safe system. In health care the ratio has for many years been around 1:10, e.g., Carthey, de Leval and Reason (2001).
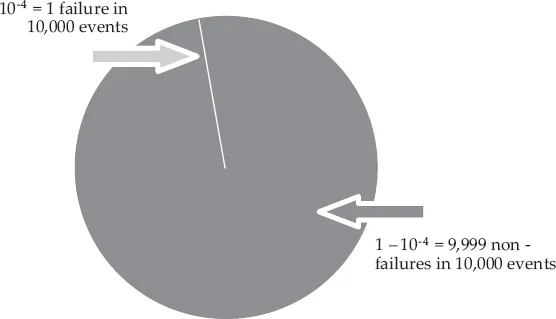
Figure 1.1 The imbalance between things that go right and things that go wrong
The tendency to focus on what goes wrong is reinforced in many ways. It is often required by regulators and authorities; it is supported by models and methods; it is documented in countless databases and illustrated by almost as many graphs; it is described in literally thousands of papers, books, and conference proceedings; and there are an untold number of experts, consultants, and companies that constantly remind us of the need to avoid risks, failures, and accidents – and of how their services can help to do just that. The net result is abundant information both about how things go wrong and about what must be done to prevent this from happening. The focus on failures also conforms to our stereotypical understanding of what safety is and on how safety should be managed, cf. above. The recipe is the simple principle known as ‘find and fix’: look for failures and malfunctions, try to find their causes, and try to eliminate causes and / or improve barriers.
One unfortunate and counterproductive consequence of this is that safety and the core activity (treating patients) compete for resources; this means that investments in safety are seen as costs, and therefore (sometimes) hard to justify or sustain. Another consequence is that learning is limited to that which has gone wrong, which means that it only happens infrequently and only uses a fraction of the data available. (A more cynical view is that learning is limited to what we are able to describe and explain.)
The situation is quite different when it comes to that which goes right, i.e., the 9,999 events out of the 10,000. A focus on what goes right receives little encouragement. There is no demand from authorities and regulators to look at what works well, and if someone should want to do so, there is little help to be found; we have few theories or models about how human and organisational performance succeeds, and few methods to help us study how it happens; examples are few and far between (Reason, 2008), and actual data are difficult to locate; it is hard to find papers, books or other forms of scientific literature about it; and there are few people who claim expertise in this area or even consider it worthwhile. Furthermore, it clashes with the traditional focus on failures, and even those who find it a reasonable endeavour are at a loss when it comes to the practicalities: there are no simple methods or tools and very few good examples to learn from.
Yet one interesting consequence of this perspective is that safety and core activity no longer compete for resources; what benefits one will also benefit the other. Another consequence is that learning can focus on that which has gone right, which means that there are literally countless opportunities for learning, and that data are readily available – once the attention is turned away from failures.
Safety-I: Avoiding Things that Go Wrong
The traditional definition of safety as a condition where the number of adverse outcomes (accidents / incidents / near misses) is as low as possible can be called Safety-I. The purpose of managing Safety-I is consequently to achieve and maintain that state. The US Agency for Healthcare Research and Quality, for instance, defines safety as the ‘freedom from accidental injury’, while the International Civil Aviation Organization defines safety as ‘the state in which harm to persons or of property damage is reduced to, and maintained at or below, an acceptable level through a continuing process of hazard identification and risk management.’
The ‘philosophy’ of Safety-I is illustrated by Figure 1.2. Safety-I promotes a bimodal or binary view of work and activities, according to which they either succeed or fail. When everything works as it should (‘normal’ functioning), the outcomes will be acceptable; things go right, in the sense that the number of adverse events is acceptably small. But when something goes wrong, when there is a malfunction, human or otherwise, this will lead to a failure (an unacceptable outcome). The issue is therefore how the transition from normal to abnormal (or malfunction) takes, place, e.g., whether it happens through an abrupt or sudden transition or through a gradual ‘drift into failure’. According to the logic of Safety-I, safety and efficiency can be achieved if this transition can be blocked. This unavoidably leads to an emphasis on compliance in the way work is carried out.
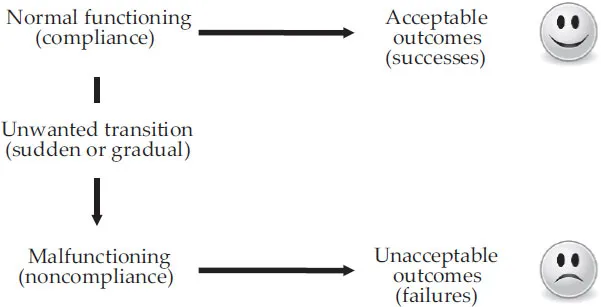
Figure 1.2 The Safety-I view of failures and successes
The focus on failures creates a need to find the causes of what went wrong. When a cause has been found, the next logical step is either to eliminate it or to disable suspected cause–effect links. Following that, the outcome should then be measured by counting how many fewer things go wrong after the intervention. Safety-I thus implies what might be called a ‘hypothesis of different causes,’ which posits that the causes or ‘mechanisms’ of adverse events are different from those of events that succeed. If that was not the case, the elimination of such causes and the neutralisation of such ‘mechanisms’ would also reduce the likelihood that things could go right and hence be counterproductive.
The background for the Safety-I perspective is found in well-understood, well-tested, and well-behaved systems. It is characteristic of such systems that there is a high degree of reliability of equipment, that workers and managers are vigilant in their testing, observations, procedures, training, and operations, that staff are well trained, that management is enlightened, and that good operating procedures are in place. If these assumptions are correct, humans – as ‘fallible machines’ – are clearly a liability and their performance variability can be seen as a threat. According to the logic of Safety-I, the goal – the coveted state of safety – can be achieved by constraining all kinds of performance variability. Examples of frequently used constraints are selection, strict training, barriers of various kinds, procedures, standardisation, rules, and regulations. The undue optimism in the efficacy of this solution has extended historical roots. But whereas the optimism may have been justified to some extent 100 years ago, it is not so today. The main reason is that the work environment has changed dramatically, and to such an extent that the assumptions of yesteryear are no longer valid.
Safety-I: Reactive Safety Management
The nature of safety management clearly depends on the definition of safety. From a Safety-I perspective, the purpose of safety management is to make sure that the number of adverse outcomes is kept as low as possible – or as low as reasonably practicable (e.g. Melchers, 2001). A good example of that is provided by the WHO research cycle shown in Figure 1.3. The figure shows a repeated cycle of steps that begins when something has gone wrong so that someone has been harmed. In health care, ‘measuring harm’ means counting how many patients are harmed or killed and from what type of adverse events. In railways, accidents can be defined as ‘employee deaths, disabling injuries and minor injuries, per 200,000 hours worked by the employees of the railway company’ or ‘train and grade crossing accidents that meet the reporting criteria, per million train miles’. Similar definitions can be found in every domain where safety is a concern.
This approach to safety management is reactive, because it is based on responding to something that either has gone wrong or has been identified as a risk – as something that could go wrong. The response typically involves looking for ways to eliminate the cause – or causes – that have been found, or to control the risks, either by finding the causes and eliminating them, or by improving options for detection and recovery. Reactive safety management embraces a causality credo, which goes as follows: (1) Adverse outcomes (accidents, incidents) happen when something goes wrong. (2) Adverse outcomes therefore have causes, which can be found and treated.
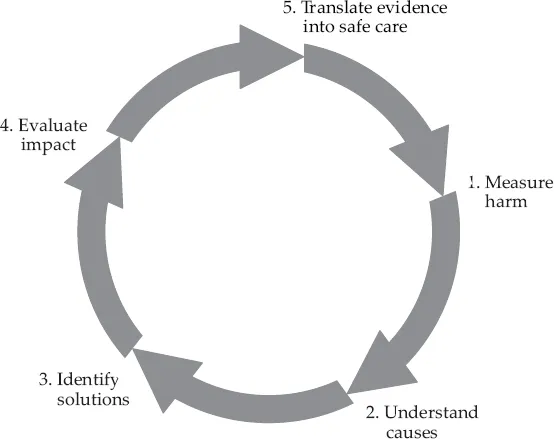
Figure 1.3 Reactive Safety Management Cycle (WHO)
From a Safety-I perspective, the purpose of safety management is to keep the number of accidents and incidents as low as possible by reacting when an unacceptable event has occurred. Such reactive safety management can work in principle if events do not occur so often that it becomes difficult or impossible to take care of the actual work, i.e., the primary activities. But if the frequency of adverse events increases, the need to respond will sooner or later require so much capacity that the reactions both become inadequate and partly lag behind the process. In practice, it means that control of the situation is lost and with that, the ability to manage safety effectively (Hollnagel and Woods, 2005).
Practical examples of this condition are easy to find. If patients are admitted to the emergency room at a rate that is higher than the rate by which they can be treated and discharged, the capacity to treat them will soon be exhausted. This can happen during everyday conditions (Wears, Perry et al., 2006), or during an epidemic (Antonio et al., 2004). On a more mundane level, most health care organisations, as well as most industries, are struggling to keep ahead of a maelstrom of incident reports mandated by law. Even if only the most serious incidents are analysed, there may still be insufficient time to understand and respond to what happened.
Another condition is that the process being managed is familiar and sufficiently regular to allow responses to be prepared ahead of time (anticipation). The worst situation is clearly when something completely unknown happens, since time and resources then must be spent on finding out what it is and work out what to do, before a response can actually be given. In order for reactive safety management to be effective, it must be possible to recognise events so quickly that the organisation can initiate a prepared response with minimal delay. The downside of this is that hasty and careless recognition may lead to inappropriate and ineffective responses.
Safety-II: Ensuring that Things Go Right
As technical and socio-technical systems have continued to develop, not least due to the allure of ever more powerful information technology, systems and work environments have gradually become more intractable (Hollnagel, 2010). Since the models and methods of Safety-I assume that systems are tractable, in the sense that they are well understood and well behaved, Safety-I models and methods are less and less able to deliver the required and coveted ‘state of safety.’ Because this inability cannot be overcome by ‘stretching’ the tools of Safety-I even further, it makes sense to consider whether the problem may lie in the definition of safety. One option is, therefore, to change the definition and to focus on what goes right rather than on what goes wrong (as suggested by Figure 1.1). Doing so will change the definition of safety from ‘avoiding that something goes wrong’ to ‘ensuring that everything goes right’ – or more precisely, to the ability to succeed under varying conditions, so that the number of intended and acceptable outcomes (in other words, everyday activities) is as high as possible. The consequence of this definition is that the basis for safety and safety management now becomes an understanding of why things go right, which means an understanding of everyday activities.
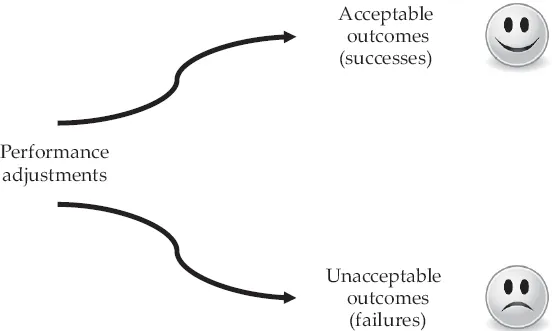
Figure 1.4 The Safety-II view of failures and successes
Safety-II explicitly assumes that systems work because people are able to adjust what they do to match the conditions of work. People learn to identify and overcome design flaws and functional glitches, because they can recognise the actual demands and adjust their performance accordingly, and because they interpret and apply procedures to match the conditions. People can also detect and correct when something goes wrong or when it is about to go wrong, hence they can intervene before the situation becomes seriously worsened. The result of that is performance variability, not in the negative sense where variability is seen as a deviation from some norm or standard, but in the positive sense that variability represents the adjustments that are the basis for safety and productivity (Figure 1.4).
In contrast to Safety-I, Safety-II acknowledges that systems are incompletely understood, that descriptions can be complicated, and that changes are frequent and irregular rather than infrequent and regular. Safety-II, in other words, acknowledges that systems are intractable rather than tractable (Hollnagel, 2010). While the reliability of technology and equipment in such systems may be high, workers and managers frequently trade off thoroughness for efficiency, the competence of staff varies and may be inconsistent or incompatible, and reliable operating procedures are scarce. Under these conditions, humans are clearly an asset rather than a liability and their ability to adjust what they do to the conditions is a strength rather than a threat.
Performance variability or performance adjustments are a sine qua non for the f...
Table of contents
- Cover
- Half Title
- Title Page
- Copyright Page
- Table of Contents
- List of Figures and Tables
- List of Contributors
- Preface: On the Need for Resilience in Health Care
- PART I HEALTH CARE AS A MULTIPLE STAKEHOLDER, MULTIPLE SYSTEMS ENTERPRISE
- PART II THE LOCUS OF RESILIENCE – INDIVIDUALS, GROUPS, SYSTEMS
- PART III THE NATURE AND PRACTICE OF RESILIENT HEALTH CARE
- Epilogue: How to Make Health Care Resilient
- Bibliography
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Resilient Health Care by Erik Hollnagel,Jeffrey Braithwaite in PDF and/or ePUB format, as well as other popular books in Medicine & Industrial & Organizational Psychology. We have over 1.5 million books available in our catalogue for you to explore.