![]()
II
Technology
INTRODUCTION
Part II presents the various technologies used to create a virtual human. As explained in Chapter 1, the concern in this book is just with digital virtual humans, so robot-related electro-mechanical (and other) technology will not be considered. This book also focuses on what can be done with the technology in early 2020s, rather than dwelling on the aspirational technologies of the future – although some of these will be considered in Chapter 13. However, consideration will be given as to what factors and interests are prompting the development of the different technologies, and how rapidly progress might be made. Particular challenges that the development of a contributing technology introduces, such as ethical or moral concerns, will also be explored.
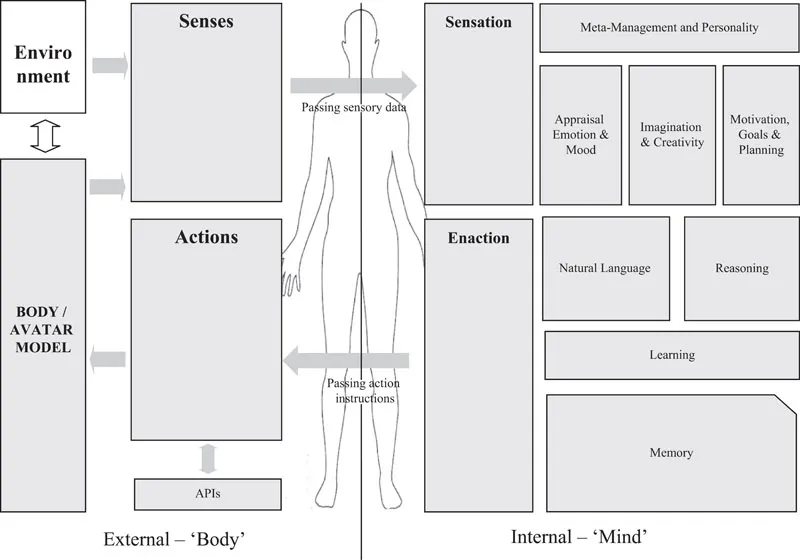
In order to describe the various elements of a virtual human, the component model in Figure II.1 will be used. It is a more detailed version of the model introduced at Figure 1.1. This has been designed to act as a guide to the discussions in the following chapters. There is no clear agreement or model of what constitutes a virtual human, but the elements shown in Figure II.1 are largely those that appear with regularity across different researchers’ cognitive and virtual human architectures as described in more detail in Chapter 6, and so can be taken as being a reasonable representation of the key elements of a virtual human. This model has also been found, in the authors’ own work, to be at a practical level to give a useful level of detail without becoming too complex.
FIGURE II.1 Virtual human component architecture.
It should be noted that the model shows a clear separation between the ‘body model’ and the ‘mind model’. Maintaining this distinction emphasises the fact that the virtual human’s ‘body’ could exist in a wide variety of manifestations, from disembodied voice on a mobile phone, to a 3D avatar in a virtual world, to even a physical robot, possibly all at the same time. In practice, this book argues that such a distinction between the body and mind elements may not be as unambiguous as it is initially presented here, but for now, it is a useful distinction. It should also be noted that in this book ‘mind’ and ‘brain’ tend to be used synonymously, whereas a stricter definition might be that, for Chapter 4 in particular, the ‘mind’ represents the processes whereas the ‘brain’ represents the processing substrate, although such dualism is, of course, open to debate!
Each element of the model will be discussed in more detail in the chapters that follow.
• Chapter 3 will consider the elements of ‘body’ and the senses.
• Chapter 4 will consider the elements of the ‘mind’.
• Chapter 5 will consider communication.
• Chapter 6 will consider the more functionally orientated cognitive architectures.
• Chapter 7 will consider the environment within which the virtual human may operate and the importance of embodiment.
• Chapter 8 will then consider how these different elements can be brought together to create a virtual human, and how ‘human’ such a virtual human might be.
![]()
CHAPTER 3
Body and Senses
INTRODUCTION
This chapter will examine the technologies which enable the creation of an avatar body for a virtual human, and the ways in which that body can incorporate human, and non-human like senses. It will explore the extent to which current approaches and techniques enable a human body to be modelled realistically as a digital avatar and analyse how the capability might develop over the coming years. The section headings follow the elements shown in the Virtual Human Component Architecture at Figure II.1.
Much of the work in this area is being driven by the computer generated imagery (CGI) of the film industry, and the motion capture and animation of the gaming industry, where CGI is almost indistinguishable from the real. However, for a virtual human, both imagery and animation need to be generated in real time, and in response to unknown events. This makes it more challenging than movie CGI, but mirrors the trend in many computer games towards having ‘sandbox’ environments where the player can explore well beyond a scripted set of encounters.
WHAT MAKES AN AVATAR?
In digital terms, an avatar for a virtual human (or physical human) can take a number of forms, including:
• A static 2D head-and-shoulders image, as used in many chat applications,
• An animated 2D head-and-shoulders or full body image, as used in some customer support applications, or
• A fully animated 3D character within a game or virtual world.
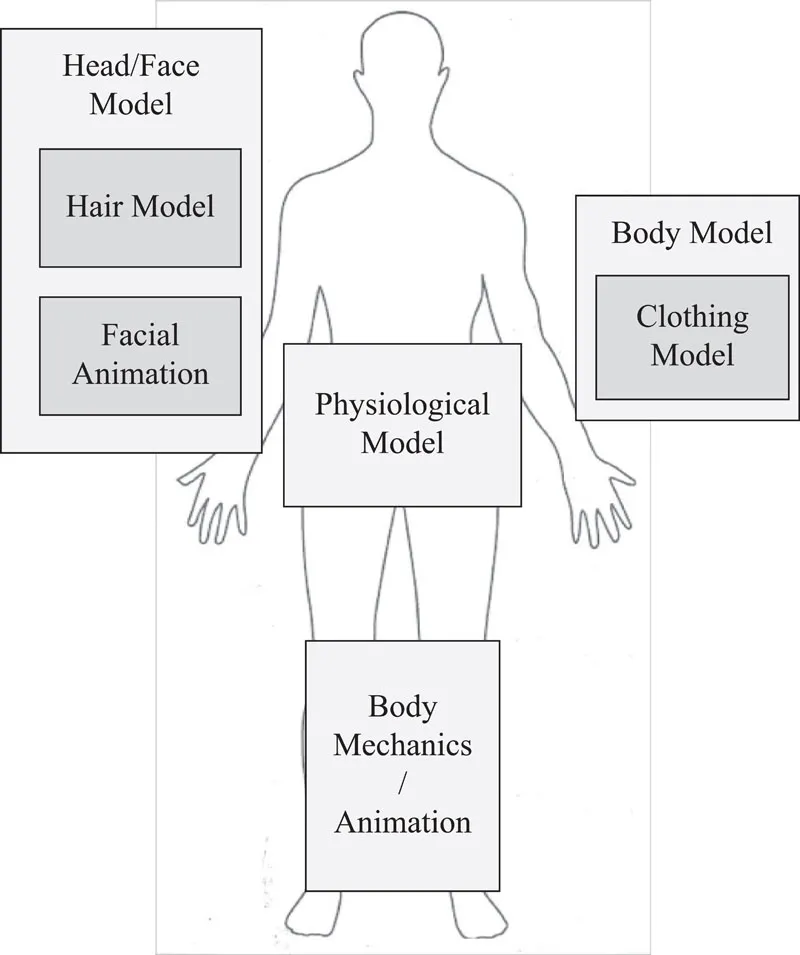
In creating an avatar for a human or virtual human, the key technology areas that need to be considered are:
• Facial rendering,
• Facial and speech animation,
• Hair modelling,
• Body rendering and modelling,
• Body mechanics and animation,
• Clothes modelling, and
• The body physiological model.
These are shown diagrammatically in Figure 3.1.
FIGURE 3.1 The elements of a virtual human body.
Note: Colour images and video of state-of-the-art examples to illustrate each of the areas discussed, along with further links, are on the website accompanying this book at www.virtualhumans.ai.
FACIAL RENDERING
Probably the most important element of any avatar representation of a virtual human is the face (Figure 3.2). For humans, talking face-to-face with someone else is seen as a richer experience than talking on the phone using only voice, or having a text-chat. There is also a preference for a physical face-to-face rather than a video link, partly since the higher fidelity enables more subtle conversational and emotional cues to be detected.
The challenge of accurate facial rendering is dominated by the notion of Mori’s ‘uncanny valley’ (1970) described in Chapter 2.
FIGURE 3.2 Simple 2D avatars developed with the Sitepal system (www.sitepal.com). Animated, talking versions are available at www.virtualhumans.ai, as well as links to more state-of-the-art facial renders. (a) A cartoon 2D animated avatar. (b) An animated 2D avatar based on a photograph of one of the authors. (c) An animated 2D avatar based on a photograph of one of the authors.
In one experiment, Fan et al. (2012) showed facial parts, in real and CGI pairs, to participants and identified that the main clues that enabled people to tell a human from a CGI face were: Eyes (36%), Skin (22%), Illumination (17%), Expression (11%) and Colour (2%). In addition, research by MacDorman et al. (2009), whilst confirming much of the uncanny valley hypothesis, also found that it was vital to get facial proportions right, especially as the photorealism increases. In a further study, Farid and Bravo (2012) found that people could identify the ‘real’ image of a person 85% of the time with typical (2010 era) computer generated faces, i.e., a computer generated version only fooled them 15% of the time. Whereas Balas and Pacella (2015) found that artificial faces formed an ‘out-group’, that is, they were seen as qualitatively different from the faces that a person usually sees (for example, in terms of race or age) and so were harder to remember or discriminate between than real human faces. From a technical modelling perspective, the key elements of a high-quality face are:
• A mesh (3D model) with sufficient detail (and deformation control) to mimic even the smallest creases in the face and provide believable movement (see next section);
• ‘Normal’ maps to show very minor skin detail, e.g., pimples, pores;
• Texture imagery with constant variation across the face to provide believable skin tone and blemishes; and
• Specular maps and other approaches (for example, sub-surface scattering) so that the skin responds correctly to light illumination and doesn’t look too waxy (based on Staples 2012).
Many commercial simulation applications, such as Virtual Battlefield System 3, use ‘photo-faces’, where a conventional 2D face image is ‘pasted’ onto a generic or customizable head shape. The face can be mapped to the head shape based on features such as the eye-eye distance. Compared to the CGI offerings, the faces can look very anomalous, particularly when animated or viewed from side angles, and can easily fall into the uncanny valley. Many consumer games have adopted more cartoon-like avatars, possibly until such time as the more lifelike faces are available.
The real challenges in facial animation are:
• Being able to render in real time, particularly in response to movement and changes in lighting;
• Rendering hair; it is no coincidence that many examples of high quality facial rendering tend to have no hair or very close cropped hair; and
• Being able to capture the likeness of a real person in an automated way.
The key limitation appears to be computer processing power, given the amount of light modelling and mesh detail required for highly realistic images and animations. This means that mobile devices are likely to have inferior avatar faces for the medium term.
FACIAL AND SPEECH ANIMATION
Whilst having a high-fidelity digital model of a human face offers one level of problem, having it move to create realistic expressions, and, particularly, to synchronize its mouth with any speech is an even greater challenge. Facial animation includes both the making of facial expressions (raising eyebrows, scrunching eyes, and smiling) and the movement of the mouth (and neighbouring areas) to match any speech being produced. A text-to-speech engine (see Chapter 5) generates the sound of what the avatar is saying, but this sound must then be used to animate the lips in real time so that it seems that it is the avatar that is saying it.
Kshirsagar et al. (2004) describes the lip sync process as being:
1. Extracting the phonemes from the speech audio. Phenomes are the smallest units of speech sound, such as ‘p’, ‘t’, ‘th’, ‘ng’ and there are about 46 phonemes in English.
2. Mapping phonemes to visemes, the visual counterparts of each phoneme showing lip shapes, such as pursed lips for an ‘oo’ sound, from a parameterized database.
3. Blending between successive visemes (called co-articulation).
The broader facial expressions must of course also be consistent with the spoken text (for example, eyebrows, eyes, head movements).
Ezzat et al. (2002) describes three approaches to speech animation:
1. Keyframing – the viseme method described above. For example, Ezzat describes how speech animation can be applied to video output, so that from one reference video, the videoed person can be made to say anything.
w2. Physics-based, modelling the underlying facial muscles and skin. Nagano’s work (2015) follows this approach, using a microstructure approach to skin deformation during talking and other facial gestures. A video of the system is available at http://gl.ict.usc.edu/Research/SkinStretch/.
3. Machine learning methods trained from recorded data and then used to synthesize new motion (for example, hidden Markov models – HMMs). This approach is used by Cao et al. (2005) who extends the machine learning control of speech animation to include all related emotion driven facial expressions as part of the speech. It is also used by Cassell et al. (2004) in the Behaviour Expression Animation Toolkit (BEAT), developed at the Massachusetts Institute of Technology (MIT) with Department of Defense (DOD) funding to automatically and appropriately fully animate the face from the text that it is meant to say.
Other video demonstrations of speech animation can be found at www.virtualhumans.ai.
Speech is a far more natural way of interacting with virtual characters, but if the sound is not linked to the face of the character speaking, then it appears disembodied. However, once linked to a face, the speech animation/lip sync must be good enough not to be off-putting and, as a result, cause an interruption to the illusion. Thus, better speech animation should result in improved simulations and virtual character engagement, particularly where interpersonal skills are required. However, the ability to create a fully lifelike, talking head of another person opens up a wide variety of ethical issues.
HAIR MODELLING
It is notable that many of the published examples of high-fidelity facial models are either bald or wearing hats. This is because the realistic modelling of...