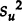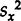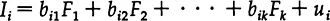Causal models are formal theories stating the relationships between precisely defined variables, and have become an indispensable tool of the social scientist. This collection of articles is a course book on the causal modeling approach to theory construction and data analysis. H. M. Blalock, Jr. summarizes the then-current developments in causal model utilization in sociology, political science, economics, and other disciplines. This book provides a comprehensive multidisciplinary picture of the work on causal models. It seeks to address the problem of measurement in the social sciences and to link theory and research through the development of causal models.Organized into five sections (Simple Recursive Models, Path Analysis, Simultaneous Equations Techniques, The Causal Approach to Measurement Error, and Other Complications), this volume contains twenty-seven articles (eight of which were specially commissioned). Each section begins with an introduction explaining the concepts to be covered in the section and links them to the larger subject. It provides a general overview of the theory and application of causal modeling.Blalock argues for the development of theoretical models that can be operationalized and provide verifiable predictions. Many of the discussions of this subject that occur in other literature are too technical for most social scientists and other scholars who lack a strong background in mathematics. This book attempts to integrate a few of the less technical papers written by econometricians such as Koopmans, Wold, Strotz, and Fisher with discussions of causal approaches in the social and biological sciences. This classic text by Blalock is a valuable source of material for those interested in the issue of measurement in the social sciences and the construction of mathematical models.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
THE CAUSAL APPROACH TO MEASUREMENT ERROR AND AGGREGATION
III
Part III deals with complications produced whenever variables have been imperfectly measured or whenever one finds it necessary to utilize aggregate data to test theories about more micro-level processes. In both instances, we are concerned with how to handle situations involving missing pieces of information that introduce additional unknowns into the system. There is now a substantial and growing body of literature on both of these topics, and therefore the editor has decided to supplement the necessarily small number of chapters in the present volume with a second volume that will focus primarily on measurement-error complications in panel and experimental designs.
Measurement errors generally produce biases in one's estimates that can only be corrected by providing a measurement-error model that contains specific assumptions about the sources of these measurement errors and that will also enable one to estimate measurement-error variances and covariances. In the simplest of cases where the measured variable X’ = X + u, where the measurement-error term, u, is assumed uncorrelated with the true value X, the resulting biases will be a function of the ratio of
to
. But this ratio will be unknown since both X and u will be unmeasured. We encounter an identification problem produced by these unmeasured variables, even in instances of recursive systems. If there are sources of measurement-error biases, as well as strictly random errors, there will be still more unknowns, and without a theory the situation may become intractable.
Whenever there are multiple measures of each variable, there may be sufficient empirical information to produce overidentified systems, provided relatively simple assumptions can be made about sources of random and nonrandom measurement errors. As a general rule, the more indicators one has and the simpler his assumptions, the greater the number of excess equations that will be available to test the compatibility of the data with the model. There will always be a number of alternative models that are consistent with any given set of data, but one may proceed by rejecting inadequate models. Having tentatively settled on a particular model, one may then estimate path coefficients, though it may not be possible to estimate unstandardized coefficients without imposing additional restrictions.
The simplest models involving multiple indicators obviously stem from the literature on factor analysis and related approaches, but they afford a somewhat different perspective that permits the introduction of various kinds of complications involving different sources of nonrandom errors. The general strategy suggested is to construct “auxiliary theories” that explicitly link each indicator variable with the unmeasured variables of interest.1r In factor analysis, the unmeasured variables or “factors” are taken as causes of the indicators, and each indicator is taken as an endogenous variable that is a function of the unmeasured factors alone, plus a unique disturbance term. If the indicators are represented as and the factors as F;, we in effect have a set of reduced-form equations of the type
where we assume that none of the indicators appears in any of the equations for the remaining indicators. In other words, we rule out any direct causation among the indicators. In many sociological and political science applications, however, this simple model is obviously inappropriate, and we need a more complex auxiliary theory.
The notion of an auxiliary theory implies that we construct causal models linking indicators and unmeasured variables, just as though there were no fundamental difference between the two. We then examine the situation to see if, using only the measured variables, we have available enough empirical information to estimate all of the path or regression coefficients in the system. Usually the system will be underidentified, and we must then consider the nature of the simplifications that will be necessary to achieve identification and to produce excess equations that can be utilized for testing purposes.
In the first chapter in Part III, Costner begins with a very simple model involving only two indicators of X and two of Y, assuming strictly random measurement error and a recursive context in which X affects Y. With a total of four measures, there are six correlations that can be obtained from the data, and these may be used to estimate the five path coefficients of the model. The excess equation can then provide a test criterion in this overidentified system. The principle can be extended in a number of directions, as Costner and others have shown. First, it can be extended to the general lc-equation case, provided there are at least two measures of each variable, and it may also be utilized in connection with certain kinds of simple causal chains when there is a single measure for the intervening variables. If additional indicators of each variable are used, the system becomes highly overidentified so that multiple tests can be made. This also permits one to introduce certain relatively simple kinds of nonrandom measurement errors in some of the indicators, as demonstrated in the chapters by Costner (12), Werts, Linn, and Jöreskog (13), Herting (14), and Herting and Costner (15).
The chapter by Werts, Linn, and Jöreskog, which was specifically written for the earlier edition of this volume, anticipates a line of development that has culminated in a very useful series of LISREL programs developed by Jöreskog and Sörbom and designed to facilitate the testing of measurementerror models that may be superimposed upon structural-equation systems of the type that are discussed in Part II. Herting's chapter provides a useful expository discussion of this rather complicated LISREL procedure. Unfortunately, it will usually be the case that one's initial measurement-error models will not provide very close empirical fittings to one's data because of errors of specification that may be difficult to pin down in the absence of a well-grounded measurement-error theory. Herting and Costner examine a number of different types of possible misspecifications and provide a series of simulation studies designed to suggest possible strategies that may be used to help locate alternative sources of errors by utilizing the tests and measures provided in the LISREL program. In doing so, their aim is to stress the fact that this important new tool can be used in an exploratory fashion to improve upon our causal models of measurement-error processes.
The chapter by Sullivan (16) involves a very different practical strategy for utilizing multiple-partial controlling techniques as an alternative to the multiple-indicator approach. In many instances, one will be dealing with blocks of highly intercorrelated variables, with no clear idea as to the causal connections within these blocks. Some variables within each block may be perfectly measured, whereas others may not. Some indicators may be causes of the variables of inte...
Table of contents
Cover Page
Title Page
Copyright
Preface
I Simple Recursive Models and Path Analysis
II Simultaneous-Equation Techniques
III The Causal Approach to Measurement Error and Aggregation
Author Index
Subject Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Causal Models in the Social Sciences by H.M. Blalock Jr., H.M. Blalock Jr.,Jr. Blalock, Jr. Blalock in PDF and/or ePUB format, as well as other popular books in Social Sciences & Social Science Research & Methodology. We have over 1.5 million books available in our catalogue for you to explore.